School of Art and Design, Fuzhou University of International Studies and Trade, Fuzhou, Fujian 350202, China.
School of Foreign Languages, Fuzhou University of International Studies and Trade, Fuzhou, Fujian 350202, China.
Comput Intell Neurosci. 2022 May 21;2022:1779131. doi: 10.1155/2022/1779131. eCollection 2022.
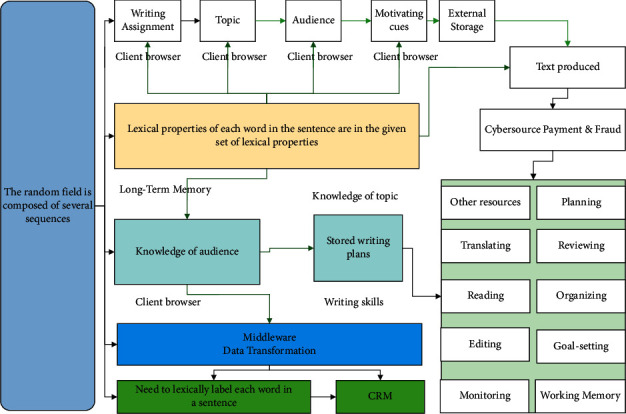
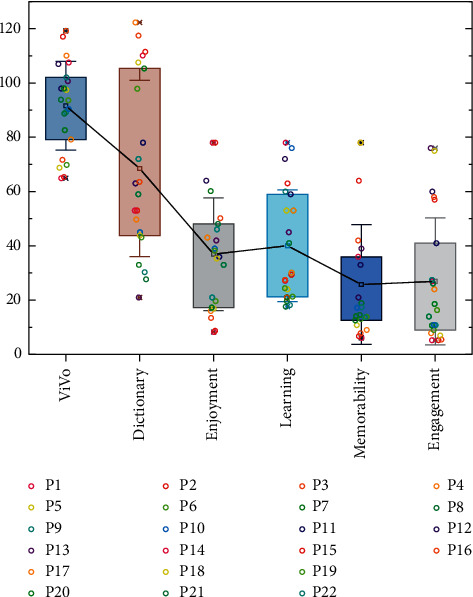
This paper presents an in-depth study and analysis of the model of English writing using artificial intelligence algorithms of neural networks. Based on word vectors, the unsupervised disambiguation, and clustering of multimedia contexts extracted from massive online videos, the disambiguation accuracy reaches over 0.7, and the resulting small-scale multimedia context set can cover up to 90% of vocabulary learning tasks; user experiments show that the multimedia context learning system based on this method can improve the effectiveness and experience of ESL vocabulary learning, as well as the long-term word sense memory of learners. The results are 30% better. Based on the dependency grammatical relations and semantic metrics of collocations on a large-scale professional corpus, we established a collocation intention description and retrieval method in line with users' linguistic cognition and doubled the usage rate of collocation retrieval on the actual deployment system after half a year, becoming a user "sticky" ESL writing aid, and further defined style. Dictionaries only provide basic lexical definitions, and, even if supported by example sentences, they still cannot meet the needs of ESL authors in terms of expressive accuracy and richness. However, the current machine translation is based on the black box deep neural network construction, and its translation process is not understandable and interactive. Among the three algorithmic models constructed in this paper, the multitask learning model outperforms the conditional random field model and the LSTM-CRF model because the multitask learning model with auxiliary tasks solves the problem of sparse data to a certain extent, allowing the model to be trained more adequately in the case of uneven label distribution, and thus performs better than other models in the task of grammatical error detection.
本文深入研究并分析了利用神经网络人工智能算法进行英文写作的模型。基于词向量,对从海量在线视频中提取的多媒体语境进行无监督消歧和聚类,消歧准确率达到 0.7 以上,生成的小规模多媒体语境集可以覆盖 90%以上的词汇学习任务;用户实验表明,基于这种方法的多媒体语境学习系统可以提高 ESL 词汇学习的效率和体验,以及学习者的长期词义记忆。效果提高了 30%。基于大规模专业语料库的搭配依存语法关系和语义度量,我们建立了一种符合用户语言认知的搭配意图描述和检索方法,在实际部署系统上,搭配检索的使用率在半年后提高了一倍,成为用户“粘性”的 ESL 写作助手,并进一步定义了风格。词典仅提供基本的词汇定义,即使有例句支持,在表达准确性和丰富性方面仍然无法满足 ESL 作者的需求。然而,当前的机器翻译是基于黑盒深度神经网络构建的,其翻译过程不可理解和交互。在本文构建的三个算法模型中,多任务学习模型优于条件随机场模型和 LSTM-CRF 模型,因为带有辅助任务的多任务学习模型在一定程度上解决了数据稀疏的问题,使得模型在标签分布不均匀的情况下能够得到更充分的训练,因此在语法错误检测任务中的表现优于其他模型。