Mortimer B. Zuckerman Mind Brain Behavior Institute, Columbia University, New York, NY, United States of America.
Department of Neuroscience, Columbia University, New York, NY, United States of America.
PLoS One. 2022 Jun 1;17(6):e0269297. doi: 10.1371/journal.pone.0269297. eCollection 2022.
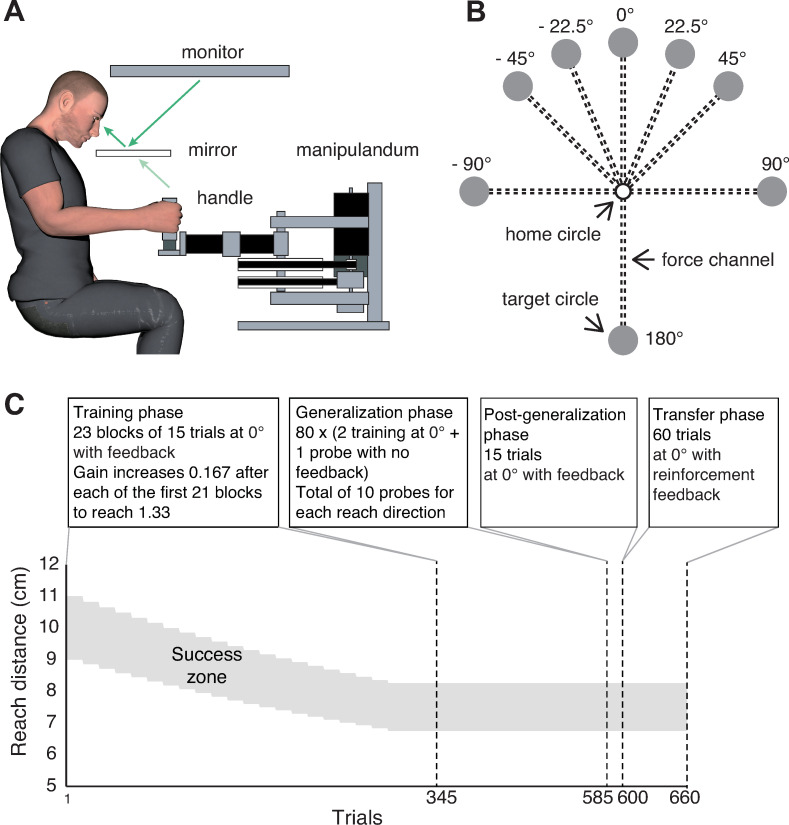
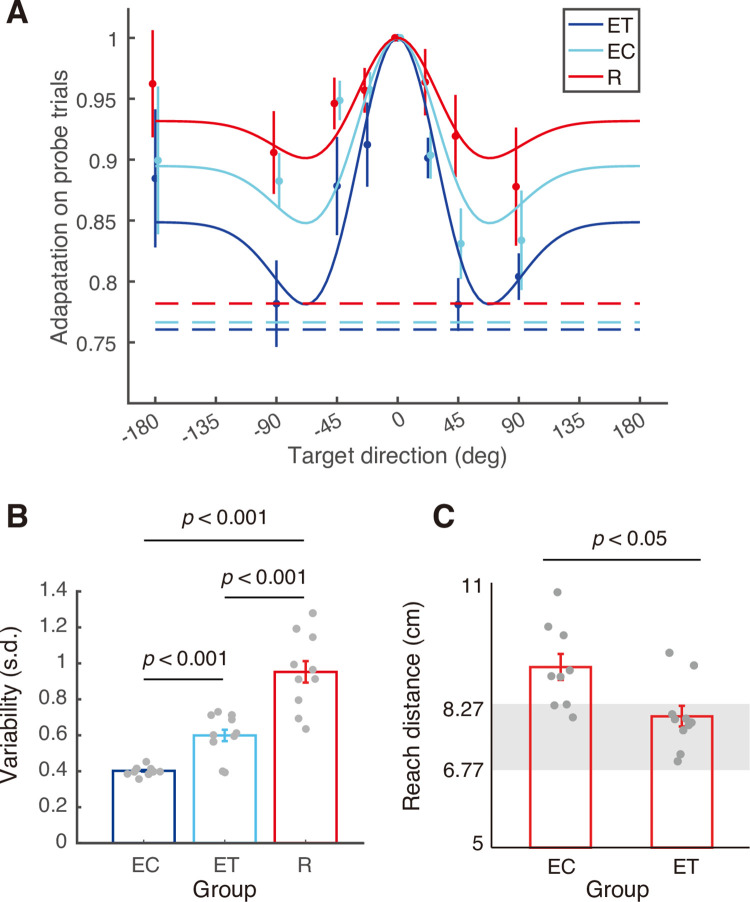
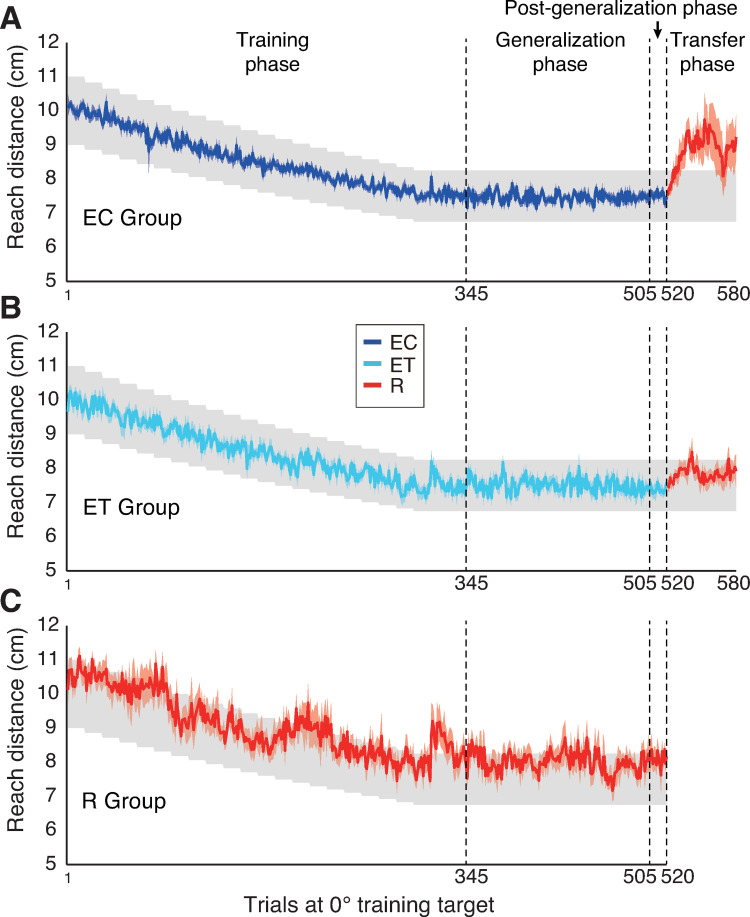
Motor adaptation can be achieved through error-based learning, driven by sensory prediction errors, or reinforcement learning, driven by reward prediction errors. Recent work on visuomotor adaptation has shown that reinforcement learning leads to more persistent adaptation when visual feedback is removed, compared to error-based learning in which continuous visual feedback of the movement is provided. However, there is evidence that error-based learning with terminal visual feedback of the movement (provided at the end of movement) may be driven by both sensory and reward prediction errors. Here we examined the influence of feedback on learning using a visuomotor adaptation task in which participants moved a cursor to a single target while the gain between hand and cursor movement displacement was gradually altered. Different groups received either continuous error feedback (EC), terminal error feedback (ET), or binary reinforcement feedback (success/fail) at the end of the movement (R). Following adaptation we tested generalization to targets located in different directions and found that generalization in the ET group was intermediate between the EC and R groups. We then examined the persistence of adaptation in the EC and ET groups when the cursor was extinguished and only binary reward feedback was provided. Whereas performance was maintained in the ET group, it quickly deteriorated in the EC group. These results suggest that terminal error feedback leads to a more robust form of learning than continuous error feedback. In addition our findings are consistent with the view that error-based learning with terminal feedback involves both error-based and reinforcement learning.
运动适应可以通过基于误差的学习来实现,这种学习受感觉预测误差驱动,也可以通过强化学习来实现,这种学习受奖励预测误差驱动。最近关于视觉运动适应的研究表明,与提供连续视觉运动反馈的基于误差的学习相比,在视觉反馈被移除的情况下,强化学习会导致更持久的适应。然而,有证据表明,具有运动终端视觉反馈的基于误差的学习(在运动结束时提供)可能同时受到感觉和奖励预测误差的驱动。在这里,我们使用视觉运动适应任务来检查反馈对学习的影响,在这个任务中,参与者在逐渐改变手和光标运动位移之间的增益的情况下,将光标移动到单个目标上。不同的组在运动结束时分别接受连续误差反馈(EC)、终端误差反馈(ET)或二进制强化反馈(成功/失败)(R)。适应后,我们测试了对位于不同方向的目标的泛化,发现 ET 组的泛化介于 EC 和 R 组之间。然后,我们在光标熄灭且仅提供二进制奖励反馈的情况下,检查了 EC 和 ET 组中适应的持久性。虽然 ET 组的表现得以维持,但 EC 组的表现迅速恶化。这些结果表明,终端误差反馈导致比连续误差反馈更稳健的学习形式。此外,我们的发现与以下观点一致,即具有终端反馈的基于误差的学习涉及基于误差的学习和强化学习。