Medical College, Guizhou University, Guiyang, China.
School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu, China.
PeerJ. 2022 Jun 14;10:e13581. doi: 10.7717/peerj.13581. eCollection 2022.
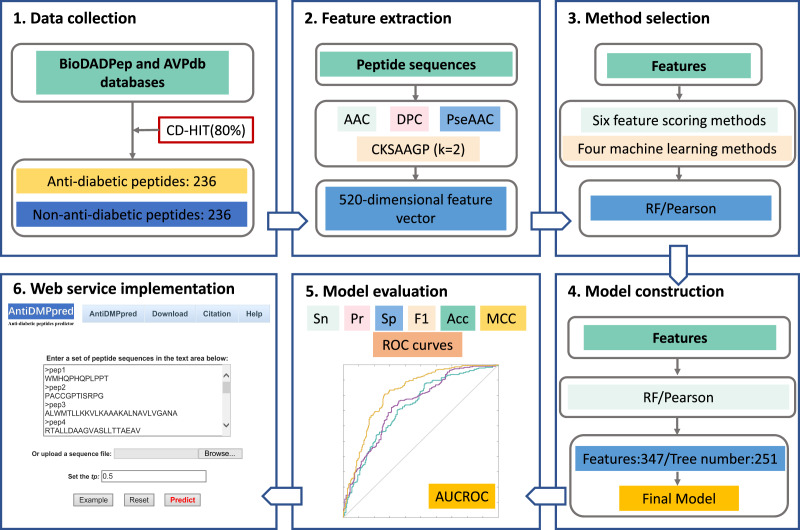
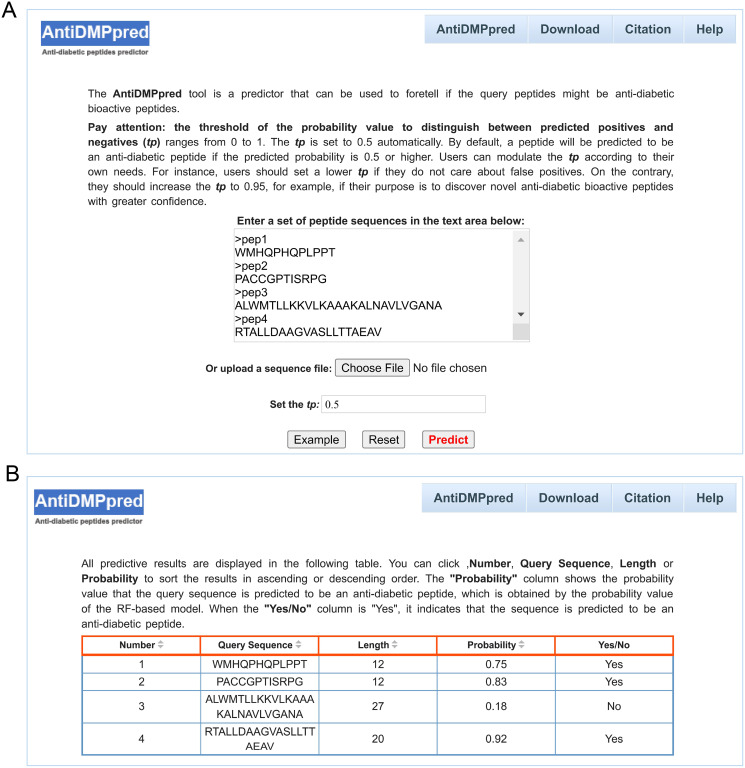
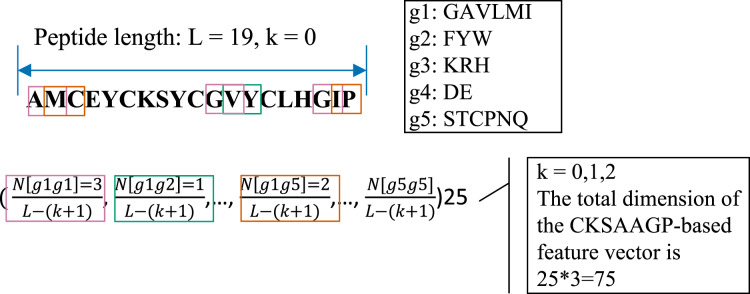
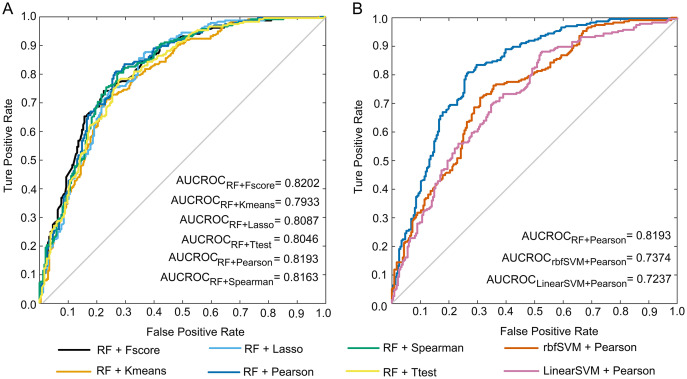
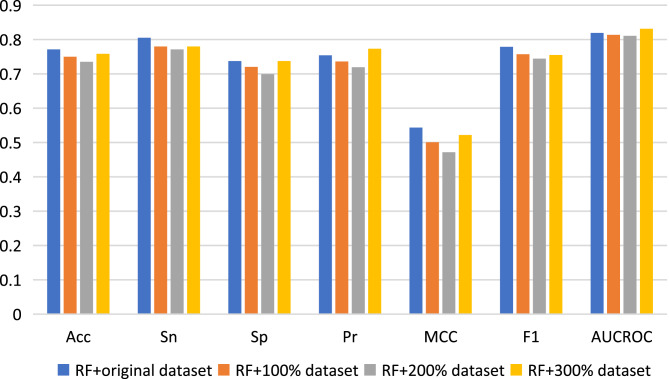
Diabetes mellitus (DM) is a chronic metabolic disease that has been a major threat to human health globally, causing great economic and social adversities. The oral administration of anti-diabetic peptide drugs has become a novel route for diabetes therapy. Numerous bioactive peptides have demonstrated potential anti-diabetic properties and are promising as alternative treatment measures to prevent and manage diabetes. The computational prediction of anti-diabetic peptides can help promote peptide-based drug discovery in the process of searching newly effective therapeutic peptide agents for diabetes treatment. Here, we resorted to random forest to develop a computational model, named AntiDMPpred, for predicting anti-diabetic peptides. A benchmark dataset with 236 anti-diabetic and 236 non-anti-diabetic peptides was first constructed. Four types of sequence-derived descriptors were used to represent the peptide sequences. We then combined four machine learning methods and six feature scoring methods to select the non-redundant features, which were fed into diverse machine learning classifiers to train the models. Experimental results show that AntiDMPpred reached an accuracy of 77.12% and area under the receiver operating curve (AUCROC) of 0.8193 in the nested five-fold cross-validation, yielding a satisfactory performance and surpassing other classifiers implemented in the study. The web service is freely accessible at http://i.uestc.edu.cn/AntiDMPpred/cgi-bin/AntiDMPpred.pl. We hope AntiDMPpred could improve the discovery of anti-diabetic bioactive peptides.
糖尿病(DM)是一种慢性代谢疾病,已成为全球范围内人类健康的主要威胁,造成了巨大的经济和社会逆境。抗糖尿病肽类药物的口服给药已成为糖尿病治疗的新途径。许多生物活性肽已显示出潜在的抗糖尿病特性,有望作为替代治疗措施,预防和管理糖尿病。抗糖尿病肽的计算预测可以帮助促进基于肽的药物发现,从而寻找新的有效的治疗糖尿病的治疗肽剂。在这里,我们求助于随机森林来开发一种计算模型,名为 AntiDMPpred,用于预测抗糖尿病肽。首先构建了一个包含 236 种抗糖尿病肽和 236 种非抗糖尿病肽的基准数据集。使用了四种类型的序列衍生描述符来表示肽序列。然后,我们结合了四种机器学习方法和六种特征评分方法来选择非冗余特征,将其输入到不同的机器学习分类器中进行模型训练。实验结果表明,AntiDMPpred 在嵌套五折交叉验证中达到了 77.12%的准确率和 0.8193 的接收器操作特征曲线下面积(AUCROC),表现出令人满意的性能,超过了研究中实现的其他分类器。该网络服务可在 http://i.uestc.edu.cn/AntiDMPpred/cgi-bin/AntiDMPpred.pl 免费访问。我们希望 AntiDMPpred 能够提高抗糖尿病生物活性肽的发现效率。