Division of Pharmacoepidemiology and Pharmacoeconomics, Brigham and Women's Hospital, Harvard Medical School, Boston, Massachusetts, USA.
KI Research Institute, Kfar Malal, Israel.
Pharmacoepidemiol Drug Saf. 2022 Sep;31(9):932-943. doi: 10.1002/pds.5500. Epub 2022 Jul 5.
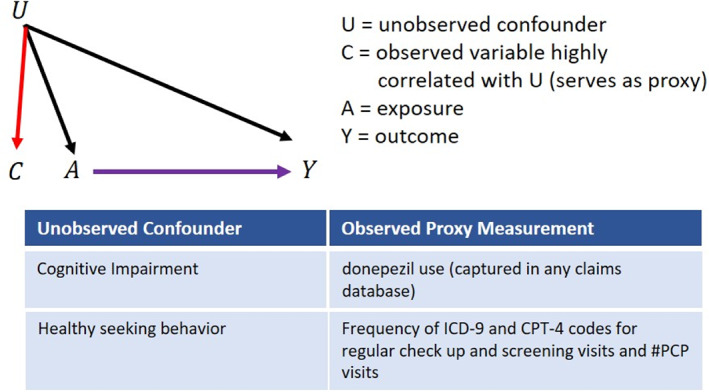
Supplementing investigator-specified variables with large numbers of empirically identified features that collectively serve as 'proxies' for unspecified or unmeasured factors can often improve confounding control in studies utilizing administrative healthcare databases. Consequently, there has been a recent focus on the development of data-driven methods for high-dimensional proxy confounder adjustment in pharmacoepidemiologic research. In this paper, we survey current approaches and recent advancements for high-dimensional proxy confounder adjustment in healthcare database studies.
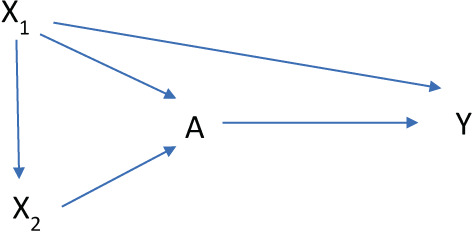
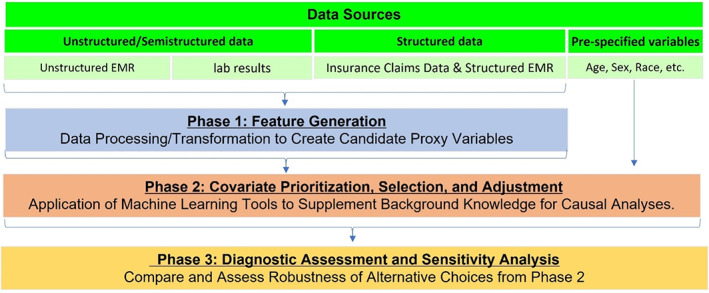
We discuss considerations underpinning three areas for high-dimensional proxy confounder adjustment: (1) feature generation-transforming raw data into covariates (or features) to be used for proxy adjustment; (2) covariate prioritization, selection, and adjustment; and (3) diagnostic assessment. We discuss challenges and avenues of future development within each area.
There is a large literature on methods for high-dimensional confounder prioritization/selection, but relatively little has been written on best practices for feature generation and diagnostic assessment. Consequently, these areas have particular limitations and challenges.
There is a growing body of evidence showing that machine-learning algorithms for high-dimensional proxy-confounder adjustment can supplement investigator-specified variables to improve confounding control compared to adjustment based on investigator-specified variables alone. However, more research is needed on best practices for feature generation and diagnostic assessment when applying methods for high-dimensional proxy confounder adjustment in pharmacoepidemiologic studies.
在利用医疗保健管理数据库进行的研究中,通过补充大量经验证的、可作为未指定或未测量因素“代理”的实证确定特征,可以改善混杂因素的控制。因此,最近人们关注的焦点是开发用于药物流行病学研究中高维代理混杂因素调整的基于数据的方法。本文综述了医疗保健数据库研究中高维代理混杂因素调整的现有方法和最新进展。
我们讨论了高维代理混杂因素调整的三个方面的基本考虑因素:(1)特征生成——将原始数据转换为用于代理调整的协变量(或特征);(2)协变量优先级、选择和调整;(3)诊断评估。我们讨论了每个领域内的挑战和未来发展方向。
虽然有大量关于高维混杂因素优先级/选择方法的文献,但关于特征生成和诊断评估的最佳实践却相对较少。因此,这些领域存在特定的限制和挑战。
越来越多的证据表明,用于高维代理混杂因素调整的机器学习算法可以补充研究者指定的变量,与仅基于研究者指定的变量相比,改善混杂因素的控制。然而,在药物流行病学研究中应用高维代理混杂因素调整方法时,需要更多关于特征生成和诊断评估最佳实践的研究。