Aix Marseille University, Inserm, MMG, Marseille, France.
Barcelona Supercomputing Center (BSC), Barcelona, Spain.
BMC Bioinformatics. 2022 Jul 23;23(1):293. doi: 10.1186/s12859-022-04828-2.
Enrichment analyses are widely applied to investigate lists of genes of interest. However, such analyses often result in long lists of annotation terms with high redundancy, making the interpretation and reporting difficult. Long annotation lists and redundancy also complicate the comparison of results obtained from different enrichment analyses. An approach to overcome these issues is using down-sized annotation collections composed of non-redundant terms. However, down-sized collections are generic and the level of detail may not fit the user's study. Other available approaches include clustering and filtering tools, which are based on similarity measures and thresholds that can be complicated to comprehend and set.
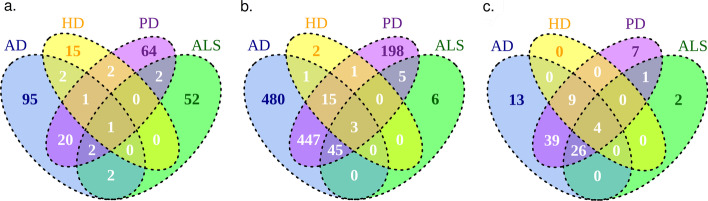
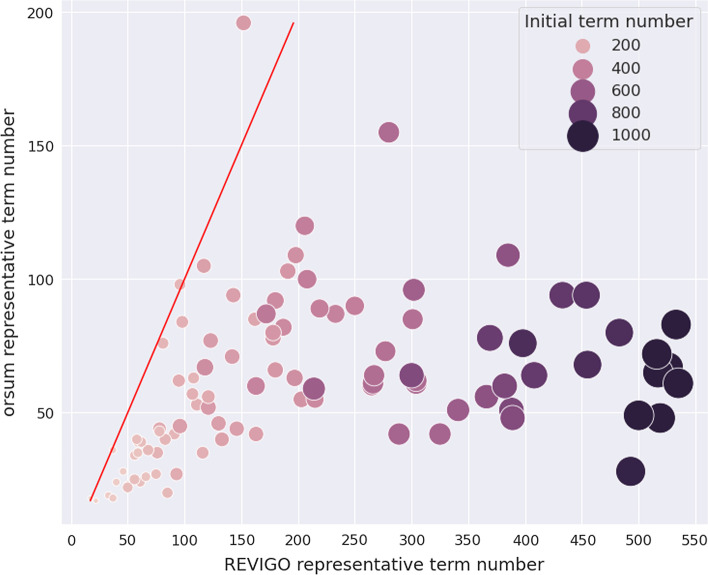
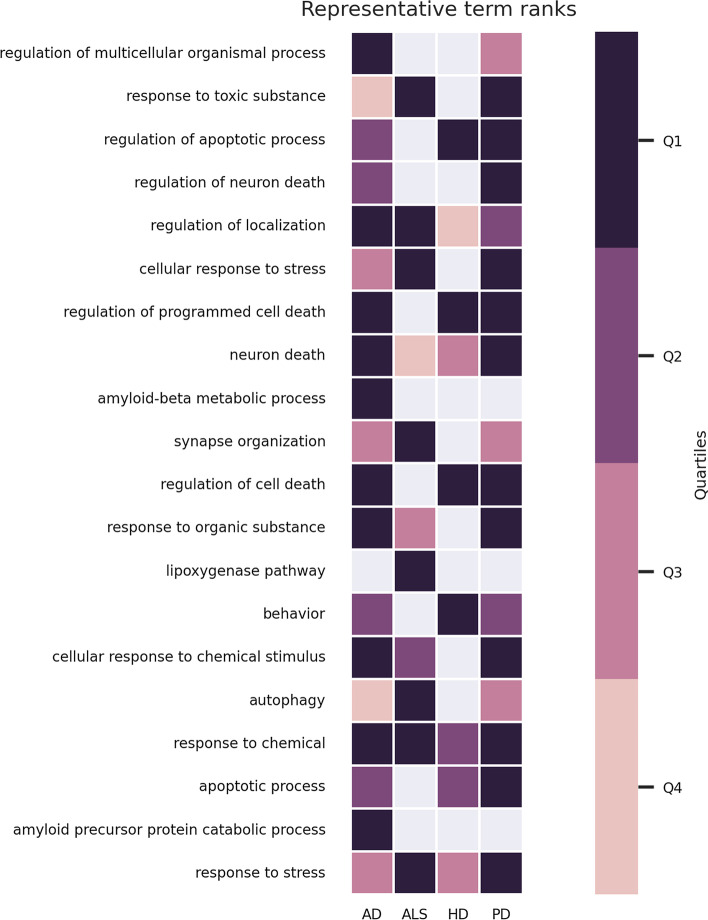
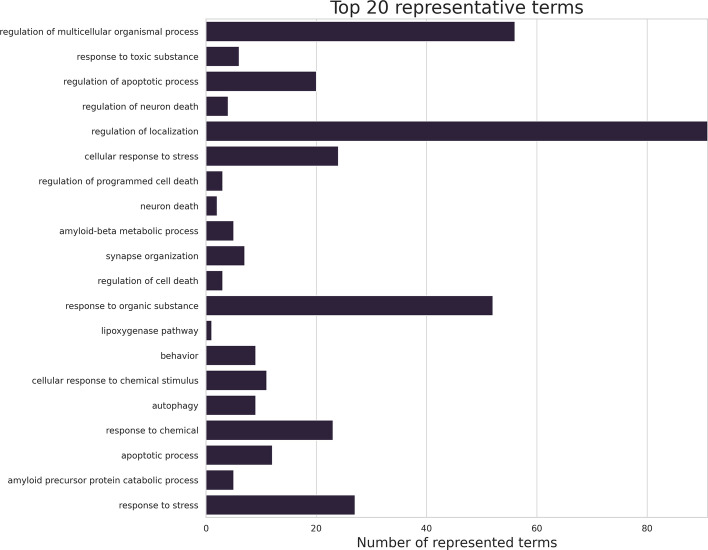
We propose orsum, a Python package to filter enrichment results. orsum can filter multiple enrichment results collectively and highlight common and specific annotation terms. Filtering in orsum is based on a simple principle: a term is discarded if there is a more significant term that annotates at least the same genes; the remaining more significant term becomes the representative term for the discarded term. This principle ensures that the main biological information is preserved in the filtered results while reducing redundancy. In addition, as the representative terms are selected from the original enrichment results, orsum outputs filtered terms tailored to the study. As a use case, we applied orsum to the enrichment analyses of four lists of genes, each associated with a neurodegenerative disease.
orsum provides a comprehensible and effective way of filtering and comparing enrichment results. It is available at https://anaconda.org/bioconda/orsum .
富集分析被广泛应用于研究感兴趣的基因列表。然而,此类分析通常会产生具有高度冗余性的大量注释术语列表,使得解释和报告变得困难。长注释列表和冗余性也使不同富集分析结果的比较变得复杂。克服这些问题的一种方法是使用由非冗余术语组成的缩小注释集。然而,缩小的集合是通用的,细节水平可能不符合用户的研究需求。其他可用的方法包括聚类和过滤工具,它们基于相似性度量和阈值,这些可能难以理解和设置。
我们提出了 orsum,这是一个用于过滤富集结果的 Python 包。orsum 可以集体过滤多个富集结果,并突出显示常见和特定的注释术语。orsum 中的过滤基于一个简单的原则:如果有一个更具显著性的术语至少注释了相同的基因,则会丢弃该术语;剩余的更具显著性的术语成为被丢弃术语的代表术语。该原则确保在过滤结果中保留主要的生物学信息,同时减少冗余性。此外,由于代表术语是从原始富集结果中选择的,orsum 会输出针对研究定制的过滤术语。作为一个用例,我们将 orsum 应用于四个与神经退行性疾病相关的基因列表的富集分析。
orsum 提供了一种易于理解和有效的过滤和比较富集结果的方法。它可以在 https://anaconda.org/bioconda/orsum 上获得。