Nutrition and Metabolism Branch, International Agency for Research on Cancer, NME Branch, 69372 CEDEX 08, Lyon, France.
Genetics Branch, International Agency for Research on Cancer, 69372 CEDEX 08, Lyon, France.
BMC Med. 2022 Oct 19;20(1):351. doi: 10.1186/s12916-022-02553-4.
Epidemiological studies of associations between metabolites and cancer risk have typically focused on specific cancer types separately. Here, we designed a multivariate pan-cancer analysis to identify metabolites potentially associated with multiple cancer types, while also allowing the investigation of cancer type-specific associations.
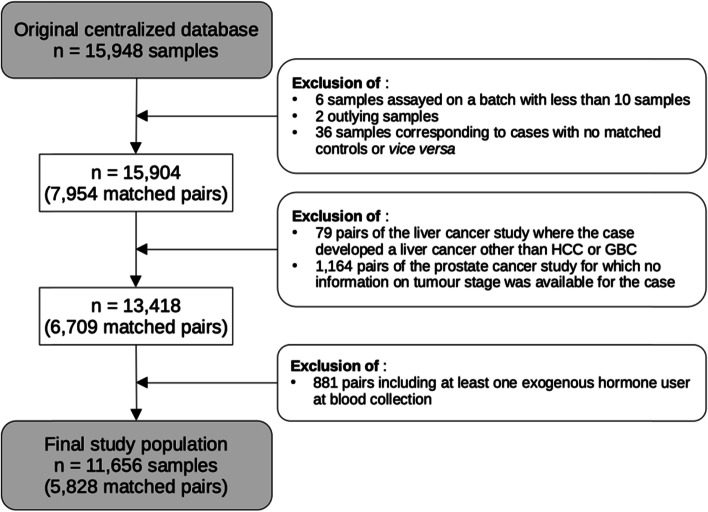
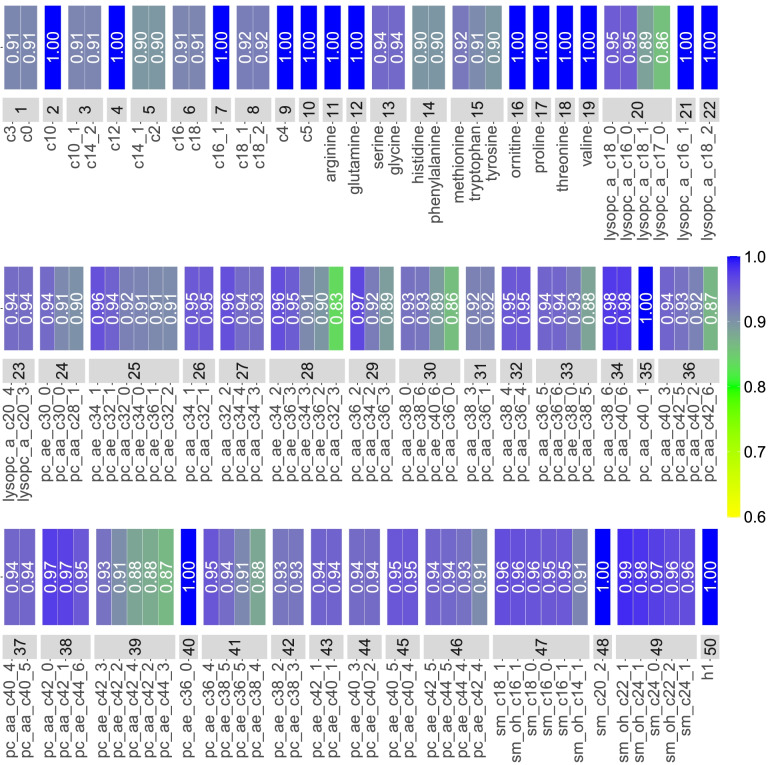
We analysed targeted metabolomics data available for 5828 matched case-control pairs from cancer-specific case-control studies on breast, colorectal, endometrial, gallbladder, kidney, localized and advanced prostate cancer, and hepatocellular carcinoma nested within the European Prospective Investigation into Cancer and Nutrition (EPIC) cohort. From pre-diagnostic blood levels of an initial set of 117 metabolites, 33 cluster representatives of strongly correlated metabolites and 17 single metabolites were derived by hierarchical clustering. The mutually adjusted associations of the resulting 50 metabolites with cancer risk were examined in penalized conditional logistic regression models adjusted for body mass index, using the data-shared lasso penalty.
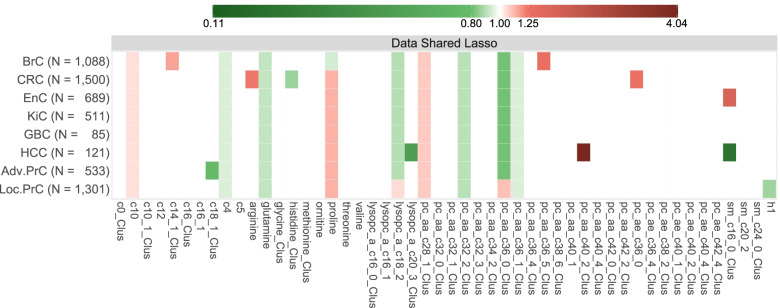
Out of the 50 studied metabolites, (i) six were inversely associated with the risk of most cancer types: glutamine, butyrylcarnitine, lysophosphatidylcholine a C18:2, and three clusters of phosphatidylcholines (PCs); (ii) three were positively associated with most cancer types: proline, decanoylcarnitine, and one cluster of PCs; and (iii) 10 were specifically associated with particular cancer types, including histidine that was inversely associated with colorectal cancer risk and one cluster of sphingomyelins that was inversely associated with risk of hepatocellular carcinoma and positively with endometrial cancer risk.
These results could provide novel insights for the identification of pathways for cancer development, in particular those shared across different cancer types.
代谢物与癌症风险之间的关联的流行病学研究通常分别针对特定的癌症类型。在这里,我们设计了一种多变量泛癌分析方法,以识别可能与多种癌症类型相关的代谢物,同时还允许研究癌症类型特异性关联。
我们分析了来自欧洲前瞻性癌症与营养研究(EPIC)队列中特定于癌症的病例对照研究中针对乳腺癌、结直肠癌、子宫内膜癌、胆囊癌、肾癌、局限性和晚期前列腺癌以及肝细胞癌的 5828 对匹配病例对照的靶向代谢组学数据。从最初的 117 种代谢物的预诊断血液水平中,通过层次聚类衍生出 33 种强相关代谢物的簇代表和 17 种单一代谢物。在调整了身体质量指数的惩罚条件逻辑回归模型中,使用数据共享套索惩罚来调整相互调整后的这些 50 种代谢物与癌症风险的关联。
在所研究的 50 种代谢物中,(i)有六种与大多数癌症类型的风险呈负相关:谷氨酰胺、丁酰肉碱、溶血磷脂酰胆碱 C18:2 和三个磷脂酰胆碱(PC)簇;(ii)有三种与大多数癌症类型呈正相关:脯氨酸、癸酰肉碱和一个 PC 簇;(iii)有 10 种代谢物与特定的癌症类型相关,包括与结直肠癌风险呈负相关的组氨酸和与肝细胞癌风险呈负相关且与子宫内膜癌风险呈正相关的一个鞘磷脂簇。
这些结果可能为识别癌症发展途径提供新的见解,特别是那些与不同癌症类型共享的途径。