NORMENT, Division of Mental Health and Addiction, Oslo University Hospital & Institute of Clinical Medicine, University of Oslo, Oslo, Norway.
Department of Nephrology, Oslo University Hospital, Oslo, Ullevål, Norway.
Geroscience. 2023 Feb;45(1):591-611. doi: 10.1007/s11357-022-00669-2. Epub 2022 Oct 19.
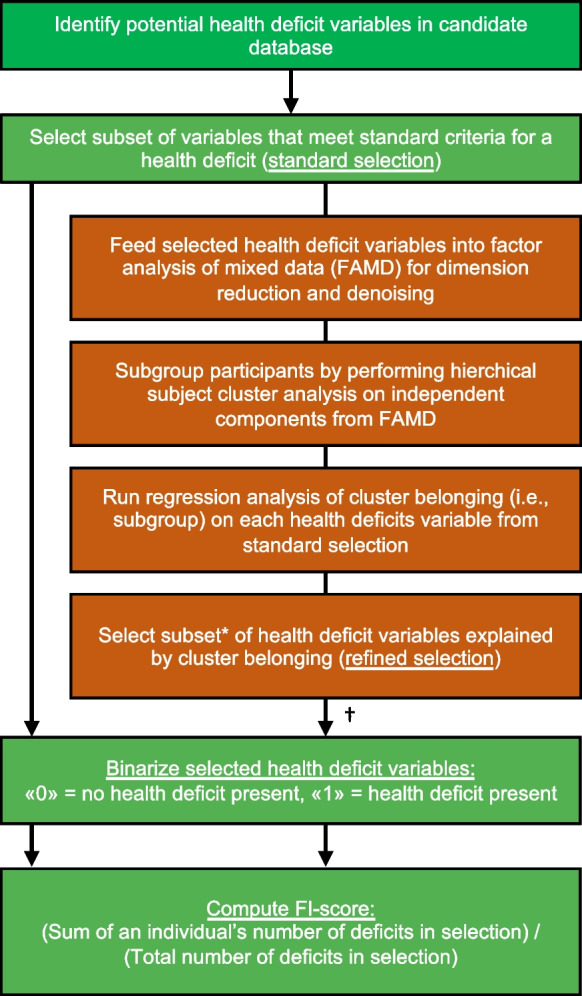
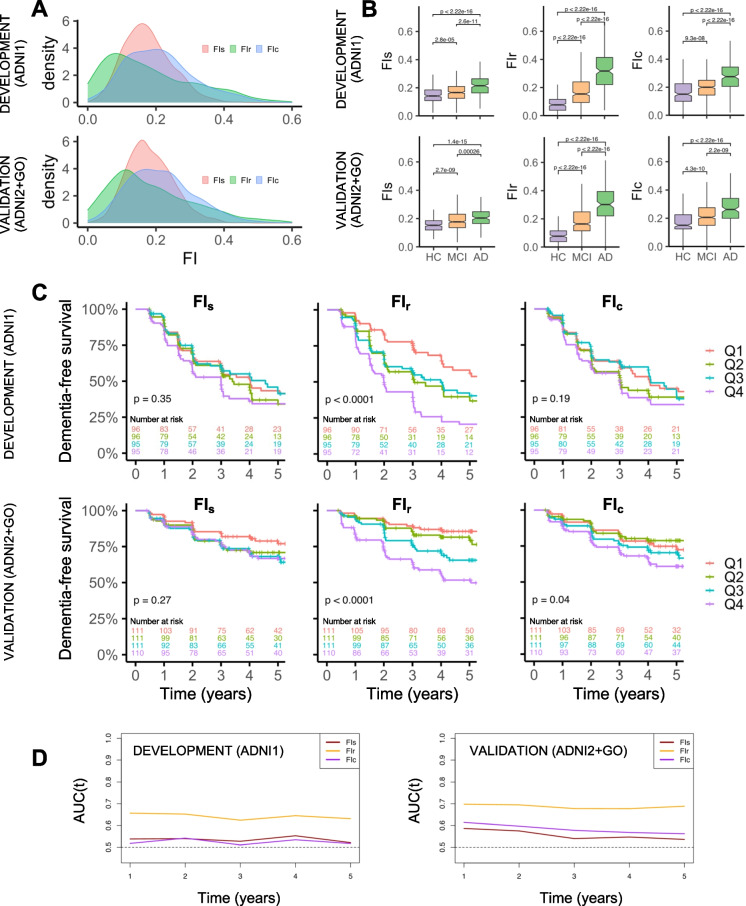
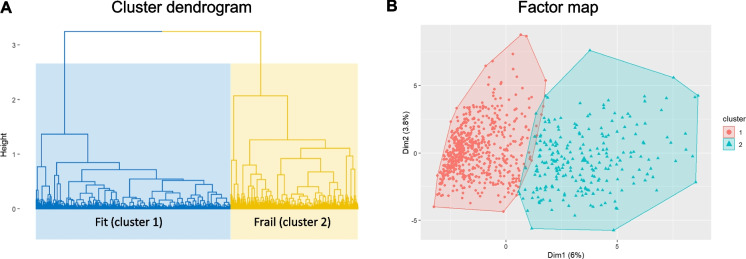
Frailty is a dementia risk factor commonly measured by a frailty index (FI). The standard procedure for creating an FI requires manually selecting health deficit items and lacks criteria for selection optimization. We hypothesized that refining the item selection using data-driven assessment improves sensitivity to cognitive status and future dementia conversion, and compared the predictive value of three FIs: a standard 93-item FI was created after selecting health deficit items according to standard criteria (FI) from the ADNI database. A refined FI (FI) was calculated by using a subset of items, identified using factor analysis of mixed data (FAMD)-based cluster analysis. We developed both FIs for the ADNI1 cohort (n = 819). We also calculated another standard FI (FI) developed by Canevelli and coworkers. Results were validated in an external sample by pooling ADNI2 and ADNI-GO cohorts (n = 815). Cluster analysis yielded two clusters of subjects, which significantly (p < .05) differed on 26 health items, which were used to compute FI. The data-driven subset of items included in FI covered a range of systems and included well-known frailty components, e.g., gait alterations and low energy. In prediction analyses, FI outperformed FI and FI in terms of baseline cognition and future dementia conversion in the training and validation cohorts. In conclusion, the data show that data-driven health deficit assessment improves an FI's prediction of current cognitive status and future dementia, and suggest that the standard FI procedure needs to be refined when used for dementia risk assessment purposes.
衰弱是一种常见的痴呆风险因素,通常通过衰弱指数(FI)来衡量。创建 FI 的标准程序需要手动选择健康缺陷项目,并且缺乏选择优化的标准。我们假设使用数据驱动的评估来改进项目选择可以提高对认知状态和未来痴呆转化的敏感性,并比较了三种 FI 的预测价值:根据 ADNI 数据库中的标准标准(FI)选择健康缺陷项目后,创建了标准的 93 项 FI(FI)。通过使用基于混合数据(FAMD)的聚类分析的因子分析来识别项目子集,计算出了改进的 FI(FI)。我们为 ADNI1 队列(n = 819)开发了这两种 FI。我们还计算了 Canevelli 及其同事开发的另一种标准 FI(FI)。通过汇集 ADNI2 和 ADNI-GO 队列(n = 815),在外部样本中验证了结果。聚类分析得出了两个受试者群,它们在 26 个健康项目上存在显著差异(p <.05),这些项目用于计算 FI。包含在 FI 中的数据驱动项目子集涵盖了多个系统,并包含了众所周知的脆弱性成分,例如步态改变和能量低下。在预测分析中,FI 在训练和验证队列中的基线认知和未来痴呆转化方面优于 FI 和 FI。总之,数据表明,数据驱动的健康缺陷评估可以提高 FI 对当前认知状态和未来痴呆的预测能力,并表明标准 FI 程序在用于痴呆风险评估时需要进行改进。