Faculty of Engineering, Queensland University of Technology, Gardens Point Campus, 2 George St, Brisbane, QLD, 4000, Australia.
School of Clinical Sciences, Queensland University of Technology, Gardens Point Campus, 2 George St, Brisbane, QLD, 4000, Australia.
Sci Rep. 2022 Oct 20;12(1):17581. doi: 10.1038/s41598-022-22196-y.
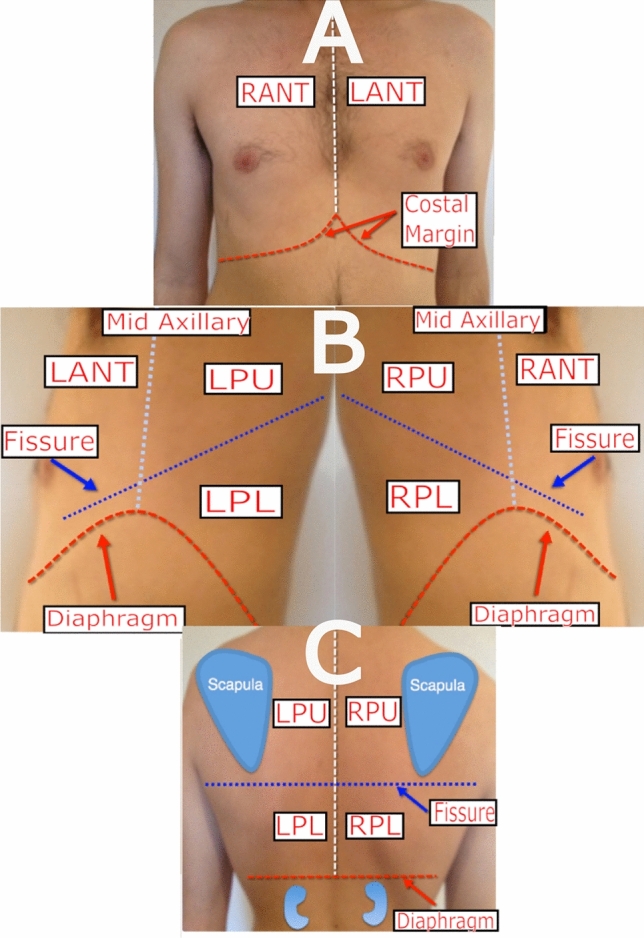
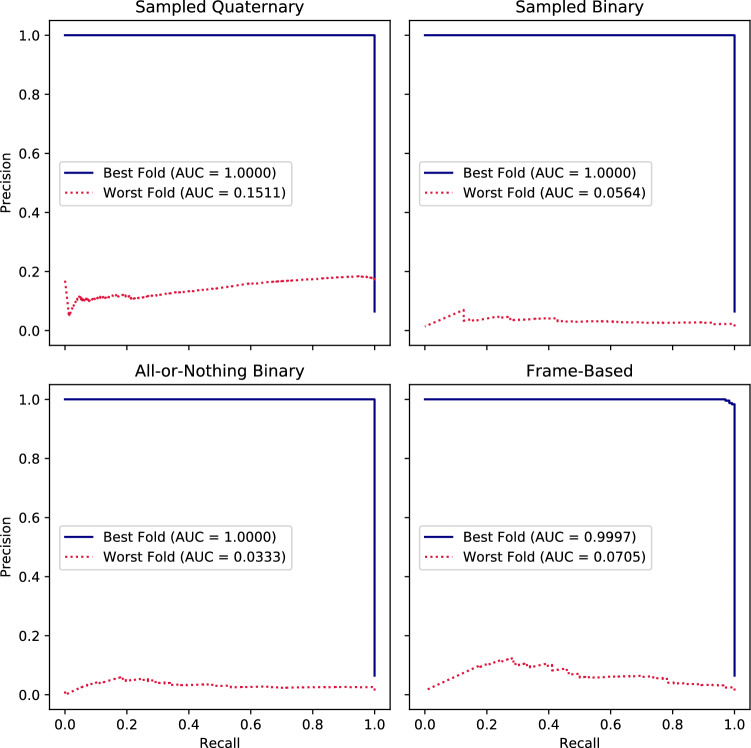
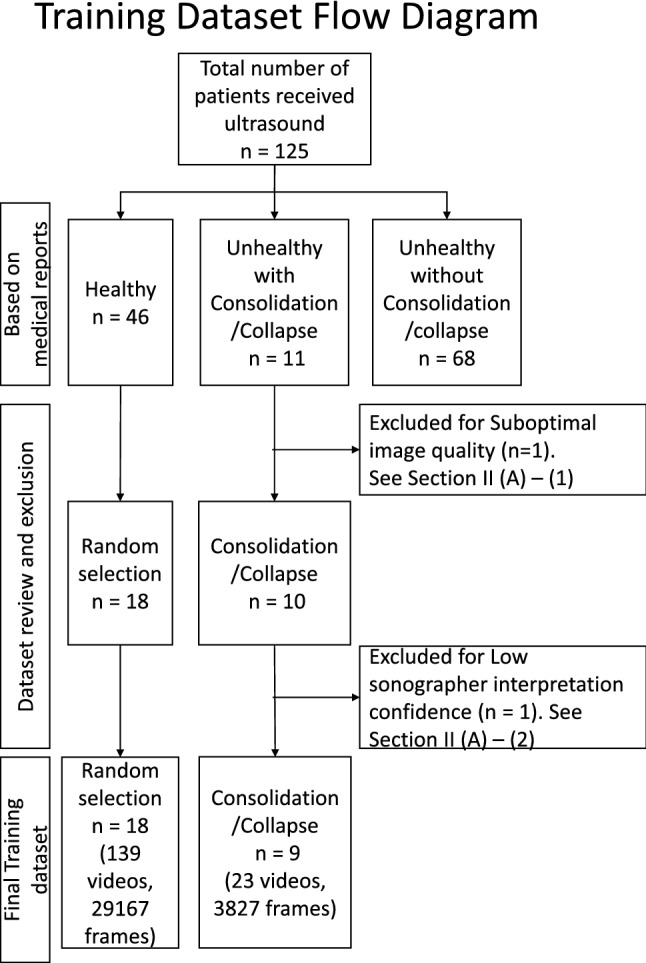
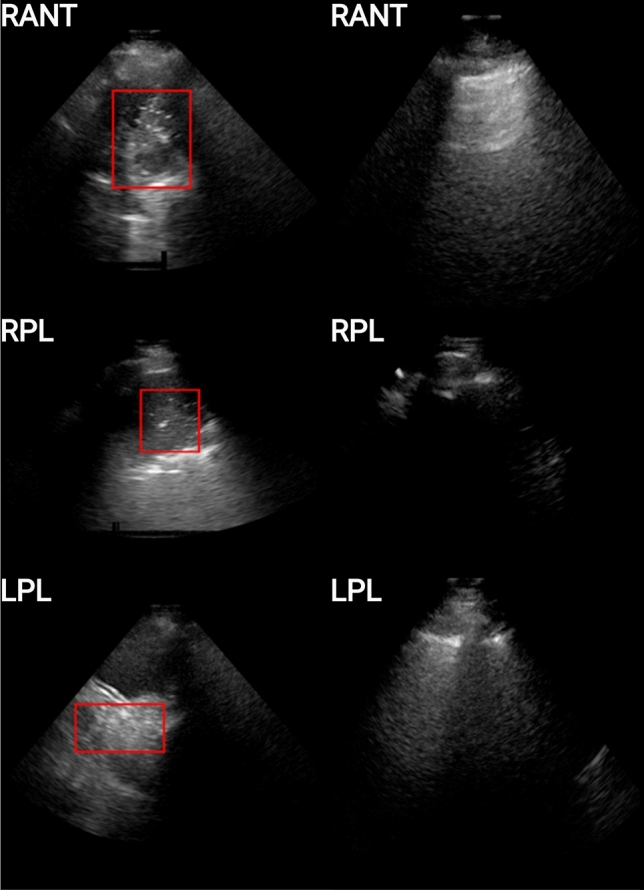
Our automated deep learning-based approach identifies consolidation/collapse in LUS images to aid in the identification of late stages of COVID-19 induced pneumonia, where consolidation/collapse is one of the possible associated pathologies. A common challenge in training such models is that annotating each frame of an ultrasound video requires high labelling effort. This effort in practice becomes prohibitive for large ultrasound datasets. To understand the impact of various degrees of labelling precision, we compare labelling strategies to train fully supervised models (frame-based method, higher labelling effort) and inaccurately supervised models (video-based methods, lower labelling effort), both of which yield binary predictions for LUS videos on a frame-by-frame level. We moreover introduce a novel sampled quaternary method which randomly samples only 10% of the LUS video frames and subsequently assigns (ordinal) categorical labels to all frames in the video based on the fraction of positively annotated samples. This method outperformed the inaccurately supervised video-based method and more surprisingly, the supervised frame-based approach with respect to metrics such as precision-recall area under curve (PR-AUC) and F1 score, despite being a form of inaccurate learning. We argue that our video-based method is more robust with respect to label noise and mitigates overfitting in a manner similar to label smoothing. The algorithm was trained using a ten-fold cross validation, which resulted in a PR-AUC score of 73% and an accuracy of 89%. While the efficacy of our classifier using the sampled quaternary method significantly lowers the labelling effort, it must be verified on a larger consolidation/collapse dataset, our proposed classifier using the sampled quaternary video-based method is clinically comparable with trained experts' performance.
我们的自动化深度学习方法可以识别肺部超声图像中的实变/塌陷,以帮助识别 COVID-19 诱导性肺炎的晚期阶段,其中实变/塌陷是可能的相关病变之一。在训练此类模型时,常见的挑战是注释超声视频的每一帧都需要大量的标注工作。在实践中,对于大型超声数据集,这种工作量变得非常大。为了了解不同程度标注精度的影响,我们比较了标注策略,以训练完全监督模型(基于帧的方法,更高的标注工作量)和不准确监督模型(基于视频的方法,更低的标注工作量),这两种方法都在逐帧的基础上对肺部超声视频进行二进制预测。此外,我们引入了一种新颖的抽样四分法,该方法仅随机抽样 10%的肺部超声视频帧,并根据阳性标注样本的比例为视频中的所有帧分配(顺序)类别标签。与基于视频的不准确监督方法相比,这种方法在精度-召回率曲线下面积(PR-AUC)和 F1 分数等指标上表现更好,尽管它是一种不准确的学习方式。我们认为,我们的基于视频的方法对于标签噪声更稳健,并以类似于标签平滑的方式减轻过拟合。该算法使用十折交叉验证进行训练,得到了 73%的 PR-AUC 分数和 89%的准确率。虽然使用抽样四分法的分类器的功效显著降低了标注工作量,但必须在更大的实变/塌陷数据集上进行验证,我们提出的使用抽样四分法的基于视频的分类器在临床上与经过训练的专家表现相当。