Paul Wurth S.A., 1122 Luxembourg, Luxembourg.
Department Computer Science, Technische Universität Kaiserslautern, 67663 Kaiserslautern, Germany.
Sensors (Basel). 2022 Nov 6;22(21):8540. doi: 10.3390/s22218540.
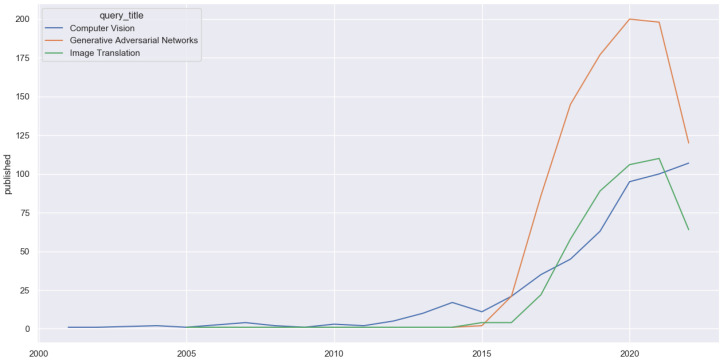
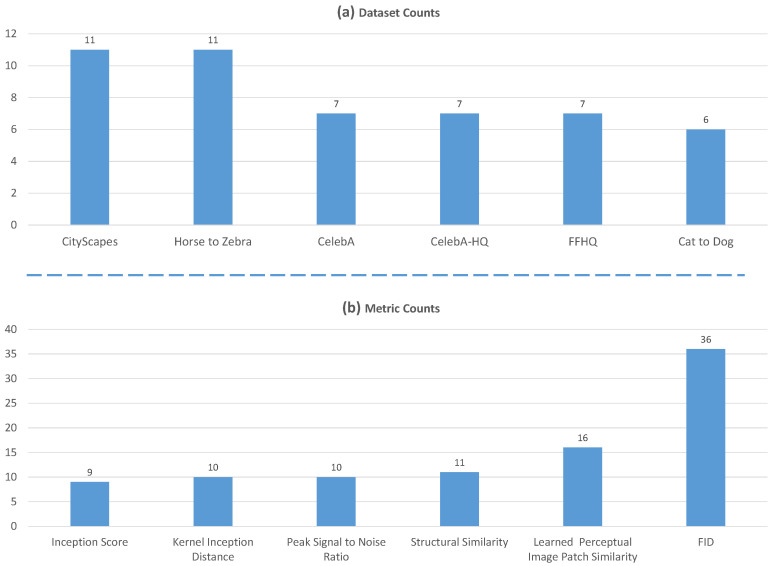
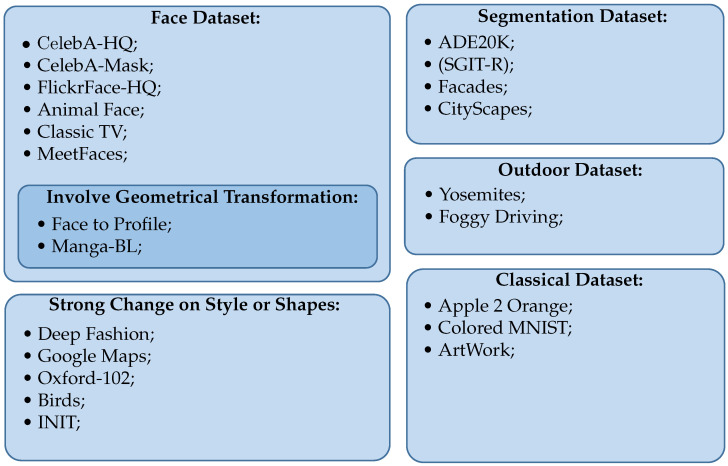
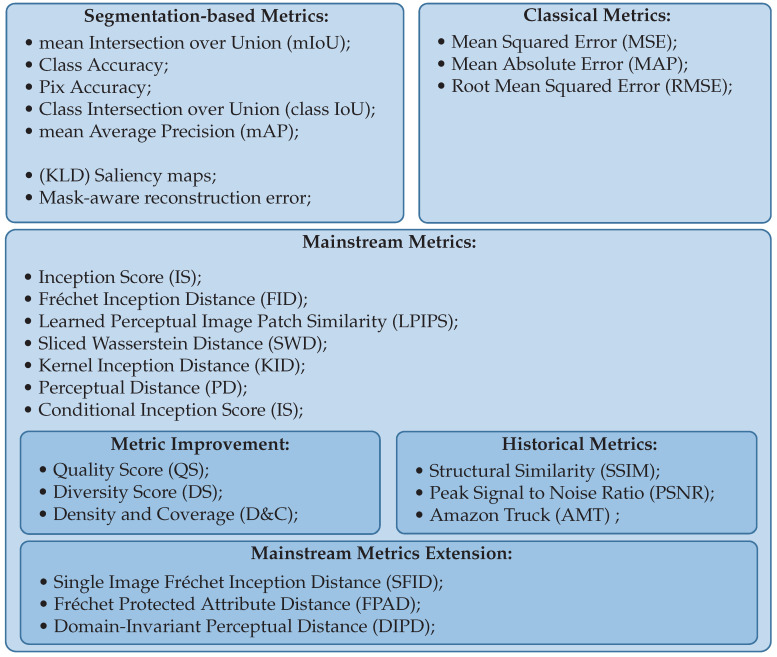
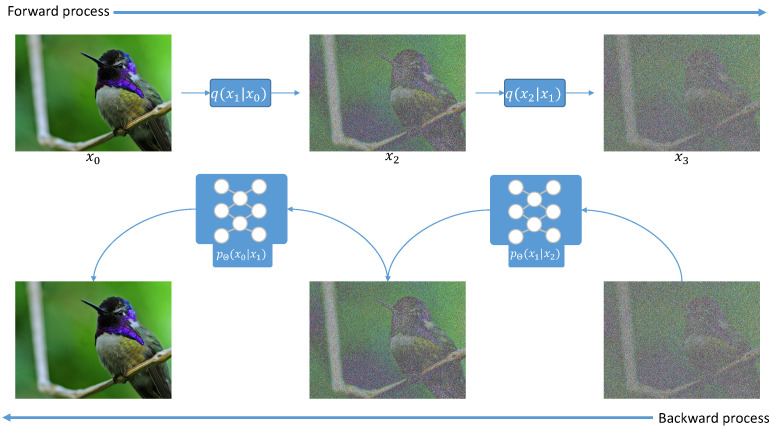
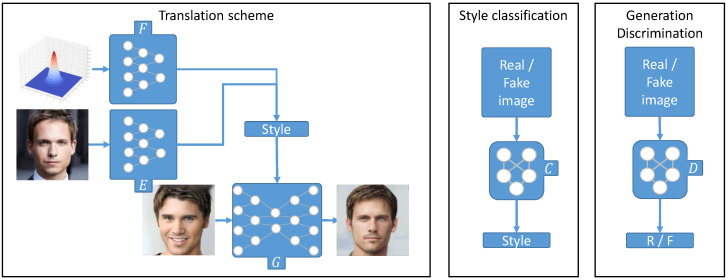
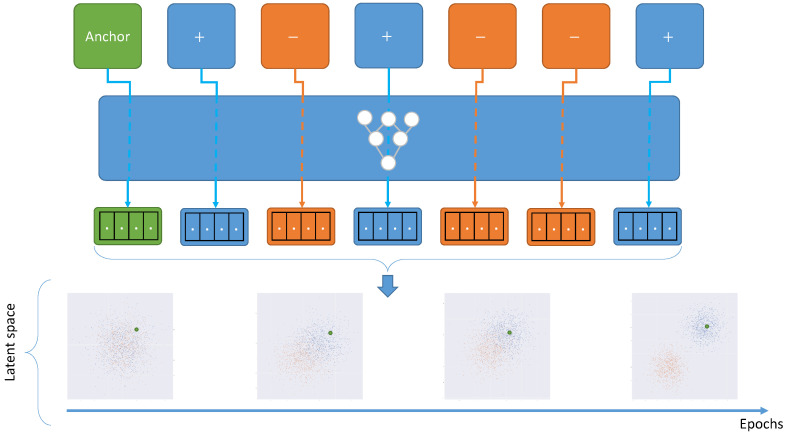
Supervised image-to-image translation has been proven to generate realistic images with sharp details and to have good quantitative performance. Such methods are trained on a paired dataset, where an image from the source domain already has a corresponding translated image in the target domain. However, this paired dataset requirement imposes a huge practical constraint, requires domain knowledge or is even impossible to obtain in certain cases. Due to these problems, unsupervised image-to-image translation has been proposed, which does not require domain expertise and can take advantage of a large unlabeled dataset. Although such models perform well, they are hard to train due to the major constraints induced in their loss functions, which make training unstable. Since CycleGAN has been released, numerous methods have been proposed which try to address various problems from different perspectives. In this review, we firstly describe the general image-to-image translation framework and discuss the datasets and metrics involved in the topic. Furthermore, we revise the current state-of-the-art with a classification of existing works. This part is followed by a small quantitative evaluation, for which results were taken from papers.
监督式图像到图像的翻译已被证明可以生成具有锐利细节的逼真图像,并且具有良好的定量性能。此类方法是在配对数据集上进行训练的,其中源域中的图像已经在目标域中有相应的翻译图像。然而,这种配对数据集的要求带来了巨大的实际限制,需要领域知识,甚至在某些情况下是不可能获得的。由于这些问题,提出了无监督的图像到图像的翻译,它不需要领域专业知识,可以利用大量未标记的数据集。尽管这些模型表现良好,但由于它们的损失函数中引入的主要约束,使得训练不稳定,因此很难训练。自从 CycleGAN 发布以来,已经提出了许多方法,试图从不同的角度解决各种问题。在本综述中,我们首先描述了一般的图像到图像的翻译框架,并讨论了该主题中涉及的数据集和指标。此外,我们通过对现有工作的分类来修订当前的最新技术。这部分之后是一个小的定量评估,结果取自论文。