Sidak David, Schwarzerová Jana, Weckwerth Wolfram, Waldherr Steffen
Department of Functional and Evolutionary Ecology, Faculty of Life Sciences, Molecular Systems Biology (MOSYS), University of Vienna, Vienna, Austria.
Department of Biomedical Engineering, Faculty of Electrical Engineering and Communication, Brno University of Technology, Brno, Czech Republic.
Front Mol Biosci. 2022 Oct 17;9:926623. doi: 10.3389/fmolb.2022.926623. eCollection 2022.
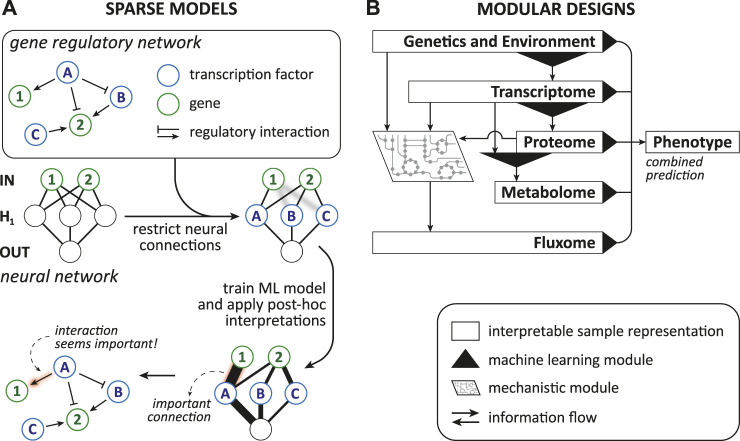
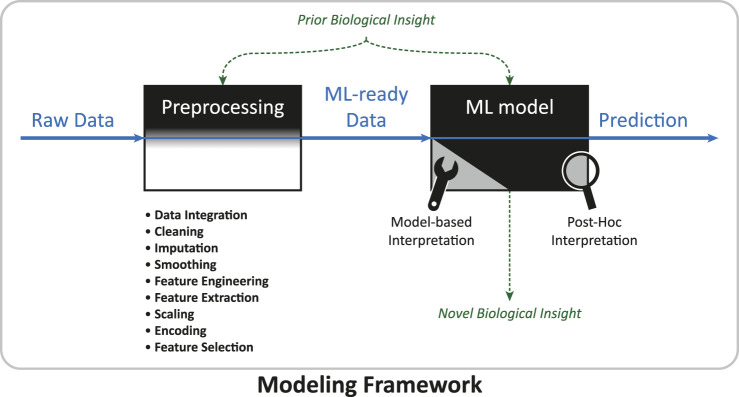
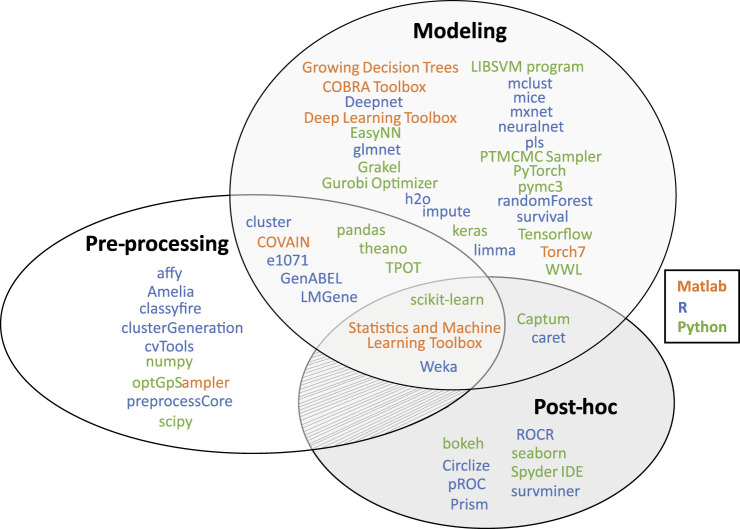
Machine learning has become a powerful tool for systems biologists, from diagnosing cancer to optimizing kinetic models and predicting the state, growth dynamics, or type of a cell. Potential predictions from complex biological data sets obtained by "omics" experiments seem endless, but are often not the main objective of biological research. Often we want to understand the molecular mechanisms of a disease to develop new therapies, or we need to justify a crucial decision that is derived from a prediction. In order to gain such knowledge from data, machine learning models need to be extended. A recent trend to achieve this is to design "interpretable" models. However, the notions around interpretability are sometimes ambiguous, and a universal recipe for building well-interpretable models is missing. With this work, we want to familiarize systems biologists with the concept of model interpretability in machine learning. We consider data sets, data preparation, machine learning methods, and software tools relevant to omics research in systems biology. Finally, we try to answer the question: "What is interpretability?" We introduce views from the interpretable machine learning community and propose a scheme for categorizing studies on omics data. We then apply these tools to review and categorize recent studies where predictive machine learning models have been constructed from non-sequential omics data.
机器学习已成为系统生物学家的强大工具,可用于癌症诊断、优化动力学模型以及预测细胞状态、生长动态或类型。通过“组学”实验获得的复杂生物数据集的潜在预测似乎无穷无尽,但往往并非生物学研究的主要目标。我们常常希望了解疾病的分子机制以开发新疗法,或者需要为基于预测做出的关键决策提供依据。为了从数据中获取此类知识,机器学习模型需要扩展。实现这一目标的最新趋势是设计“可解释”模型。然而,围绕可解释性的概念有时并不明确,且缺少构建良好可解释模型的通用方法。通过这项工作,我们希望让系统生物学家熟悉机器学习中模型可解释性的概念。我们考虑与系统生物学中的组学研究相关的数据集、数据准备、机器学习方法和软件工具。最后,我们尝试回答“什么是可解释性?”这个问题。我们介绍了可解释机器学习领域的观点,并提出了一种对组学数据研究进行分类的方案。然后,我们应用这些工具对近期从非序列组学数据构建预测性机器学习模型的研究进行综述和分类。