Diabetes Unit, Massachusetts General Hospital, Boston, MA, USA.
Broad Institute of MIT and Harvard, Cambridge, MA, USA.
Diabetologia. 2023 Mar;66(3):495-507. doi: 10.1007/s00125-022-05848-6. Epub 2022 Dec 20.
AIMS/HYPOTHESIS: Type 2 diabetes is highly polygenic and influenced by multiple biological pathways. Rapid expansion in the number of type 2 diabetes loci can be leveraged to identify such pathways.
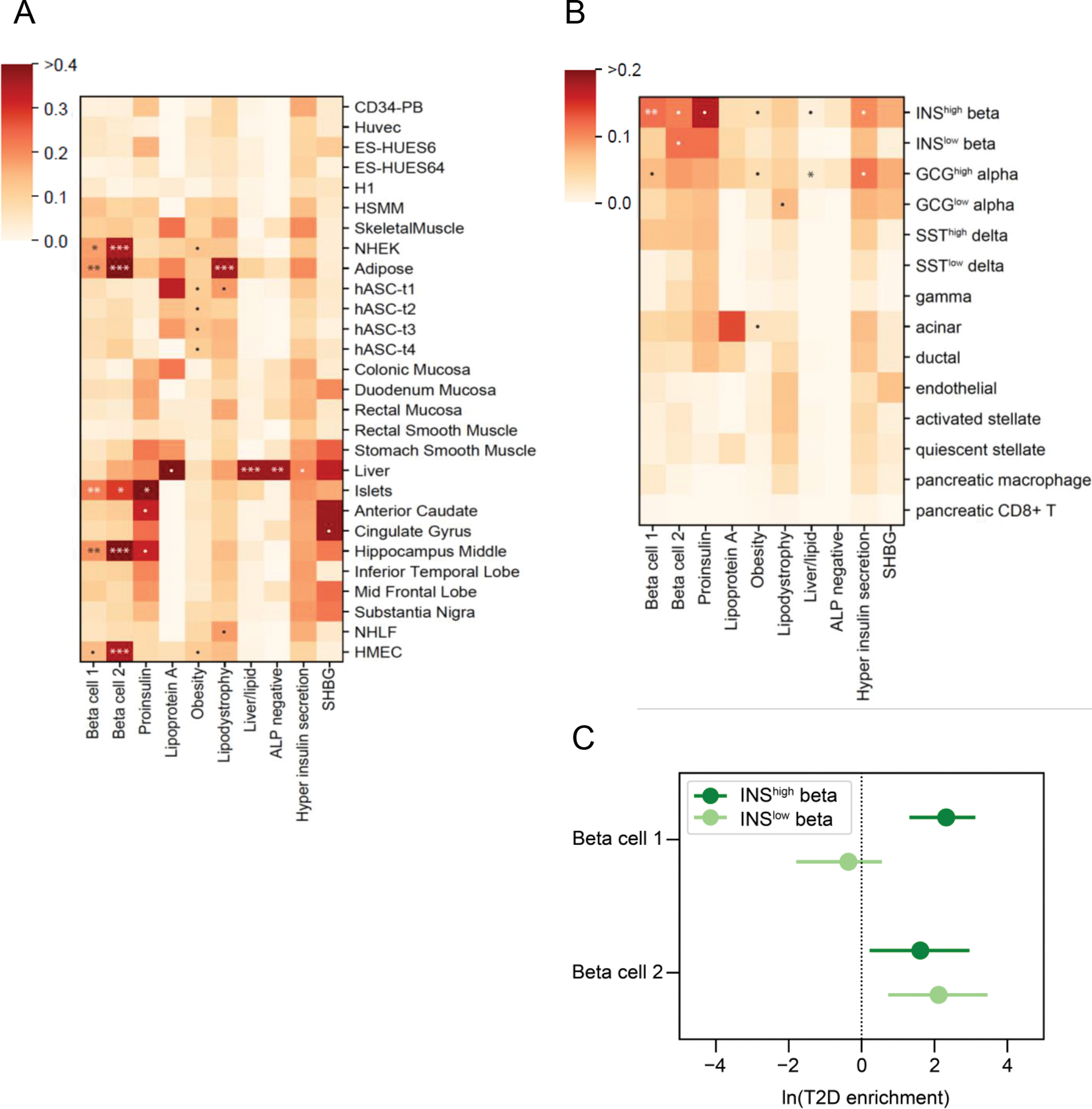
We developed a high-throughput pipeline to enable clustering of type 2 diabetes loci based on variant-trait associations. Our pipeline extracted summary statistics from genome-wide association studies (GWAS) for type 2 diabetes and related traits to generate a matrix of 323 variants × 64 trait associations and applied Bayesian non-negative matrix factorisation (bNMF) to identify genetic components of type 2 diabetes. Epigenomic enrichment analysis was performed in 28 cell types and single pancreatic cells. We generated cluster-specific polygenic scores and performed regression analysis in an independent cohort (N=25,419) to assess for clinical relevance.
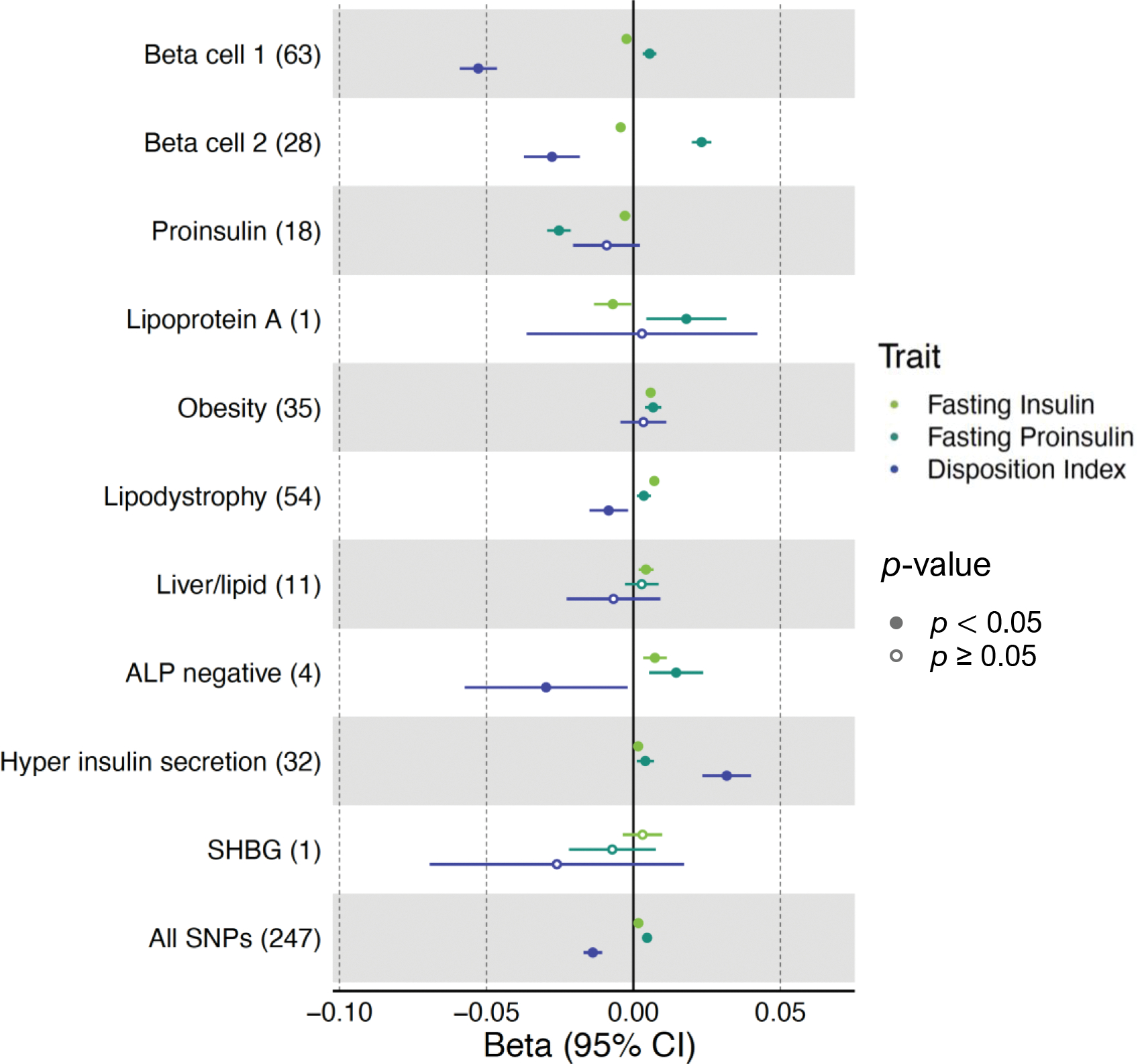
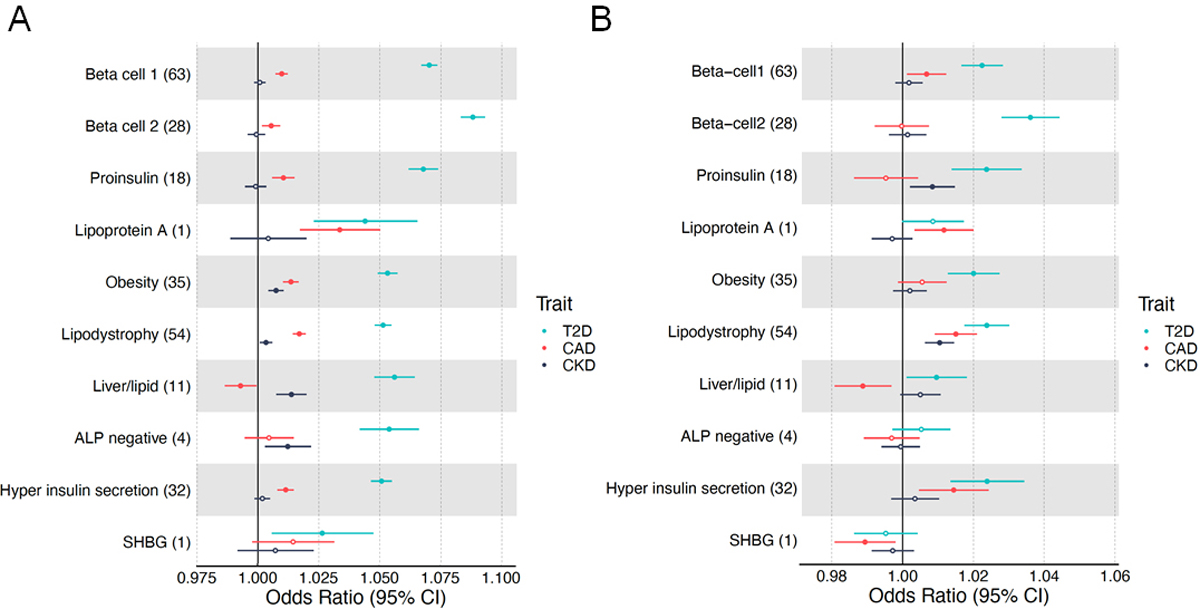
We identified ten clusters of genetic loci, recapturing the five from our prior analysis as well as novel clusters related to beta cell dysfunction, pronounced insulin secretion, and levels of alkaline phosphatase, lipoprotein A and sex hormone-binding globulin. Four clusters related to mechanisms of insulin deficiency, five to insulin resistance and one had an unclear mechanism. The clusters displayed tissue-specific epigenomic enrichment, notably with the two beta cell clusters differentially enriched in functional and stressed pancreatic beta cell states. Additionally, cluster-specific polygenic scores were differentially associated with patient clinical characteristics and outcomes. The pipeline was applied to coronary artery disease and chronic kidney disease, identifying multiple overlapping clusters with type 2 diabetes.
CONCLUSIONS/INTERPRETATION: Our approach stratifies type 2 diabetes loci into physiologically interpretable genetic clusters associated with distinct tissues and clinical outcomes. The pipeline allows for efficient updating as additional GWAS become available and can be readily applied to other conditions, facilitating clinical translation of GWAS findings. Software to perform this clustering pipeline is freely available.
目的/假设:2 型糖尿病是高度多基因的,并受多种生物学途径的影响。快速增加 2 型糖尿病的数量可以用来识别这些途径。
我们开发了一种高通量的管道,能够根据变体-特征关联对 2 型糖尿病的位点进行聚类。我们的管道从 2 型糖尿病和相关特征的全基因组关联研究(GWAS)中提取汇总统计数据,生成 323 个变体×64 个特征关联的矩阵,并应用贝叶斯非负矩阵分解(bNMF)来识别 2 型糖尿病的遗传成分。在 28 种细胞类型和单个胰腺细胞中进行了表观基因组富集分析。我们生成了特定于聚类的多基因评分,并在一个独立的队列(N=25419)中进行回归分析,以评估其临床相关性。
我们确定了十个遗传位点的聚类,重新捕获了我们之前分析的五个聚类,以及与β细胞功能障碍、明显的胰岛素分泌以及碱性磷酸酶、脂蛋白 A 和性激素结合球蛋白水平相关的新聚类。四个聚类与胰岛素缺乏的机制有关,五个与胰岛素抵抗有关,一个机制尚不清楚。这些聚类显示出组织特异性的表观基因组富集,特别是两个与β细胞有关的聚类在功能和应激的胰腺β细胞状态中存在差异富集。此外,聚类特异性的多基因评分与患者的临床特征和结果有差异相关。该管道还应用于冠状动脉疾病和慢性肾病,与 2 型糖尿病有多个重叠的聚类。
结论/解释:我们的方法将 2 型糖尿病的位点分为具有不同组织和临床结果的生理可解释的遗传聚类。该管道允许随着更多 GWAS 的出现进行高效更新,并可方便地应用于其他条件,促进 GWAS 发现的临床转化。执行此聚类管道的软件是免费提供的。