Public Health Ontario (PHO), Toronto, ON, Canada.
Dalla Lana School of Public Health, University of Toronto, Toronto, ON, Canada.
BMC Med Inform Decis Mak. 2023 Jan 26;23(1):20. doi: 10.1186/s12911-023-02117-3.
Extracting relevant information about infectious diseases is an essential task. However, a significant obstacle in supporting public health research is the lack of methods for effectively mining large amounts of health data.
This study aims to use natural language processing (NLP) to extract the key information (clinical factors, social determinants of health) from published cases in the literature.
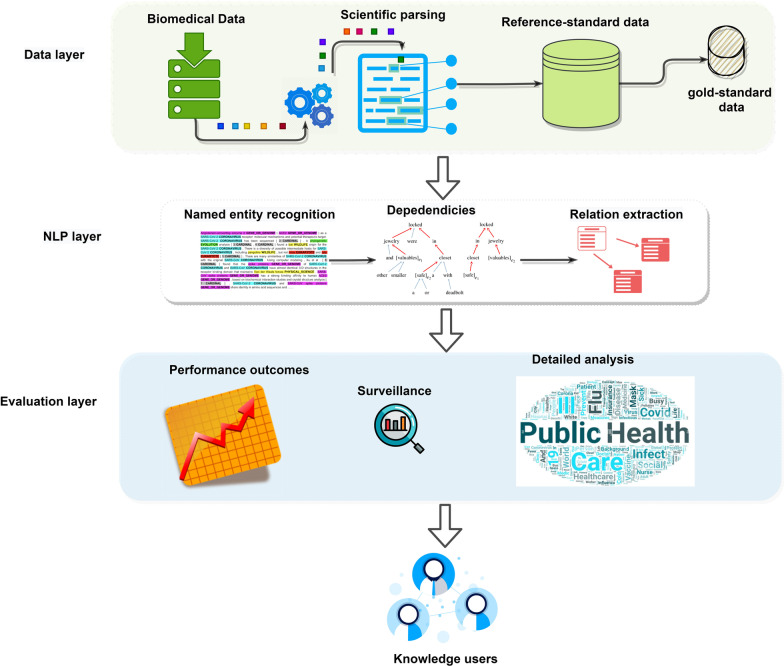
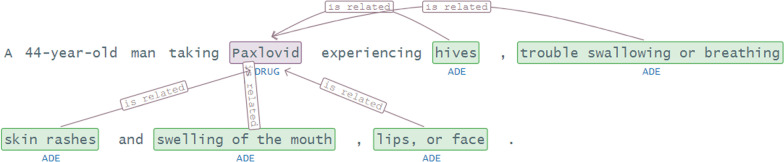
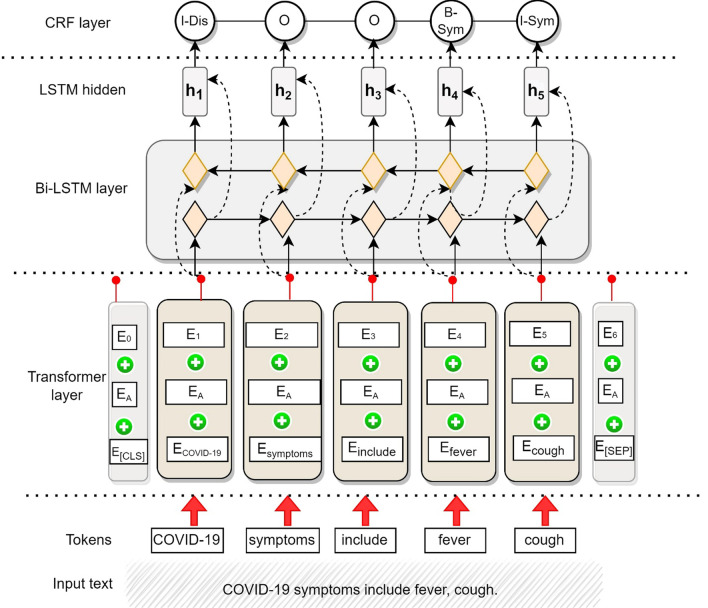
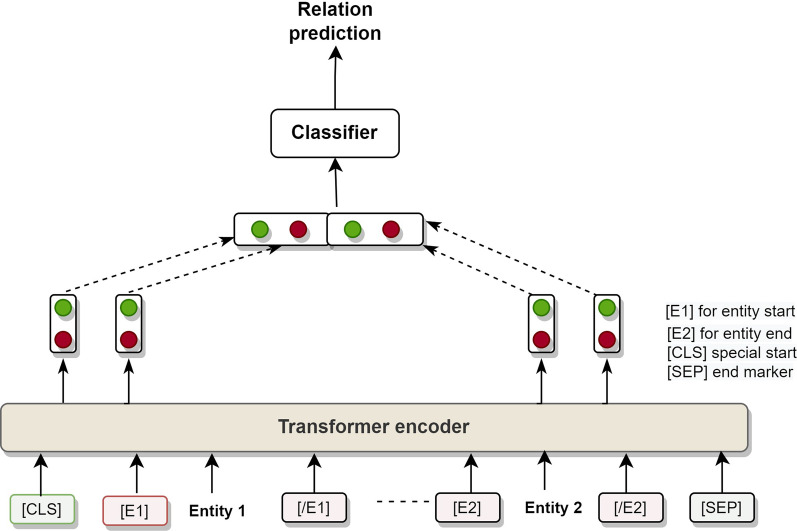
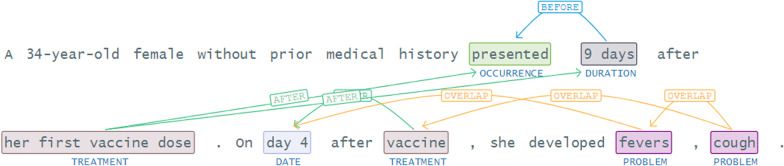
The proposed framework integrates a data layer for preparing a data cohort from clinical case reports; an NLP layer to find the clinical and demographic-named entities and relations in the texts; and an evaluation layer for benchmarking performance and analysis. The focus of this study is to extract valuable information from COVID-19 case reports.
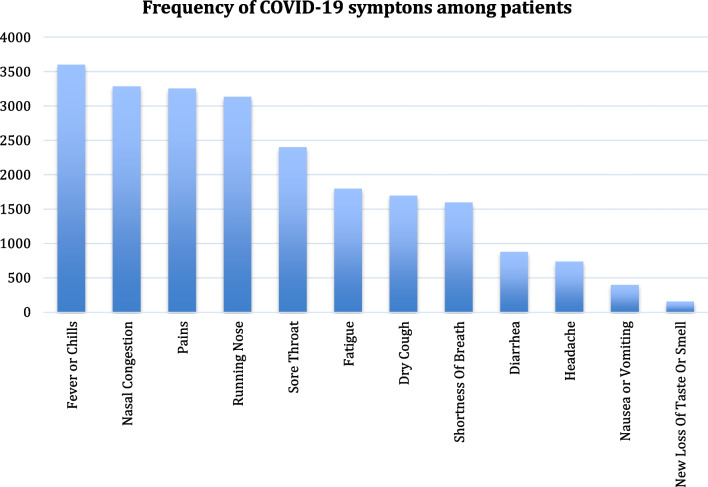
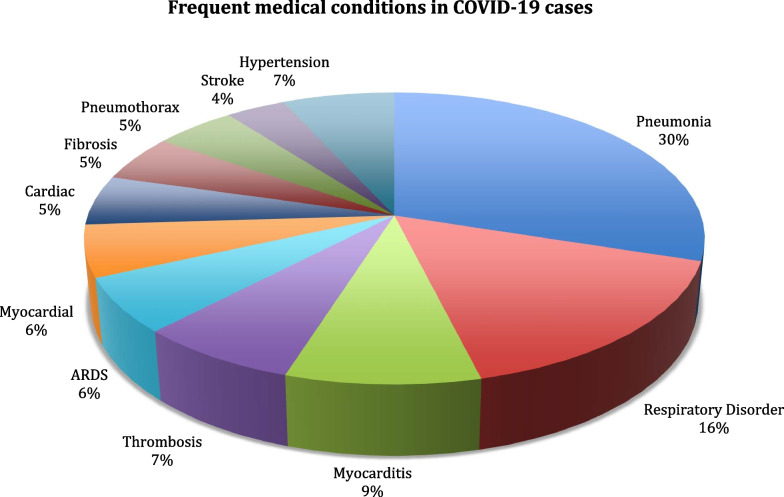
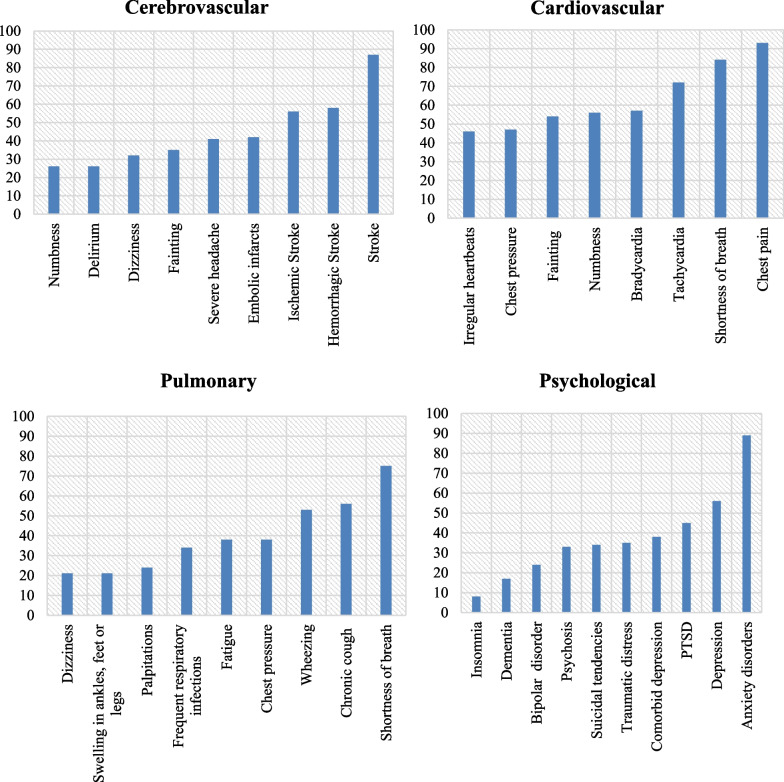
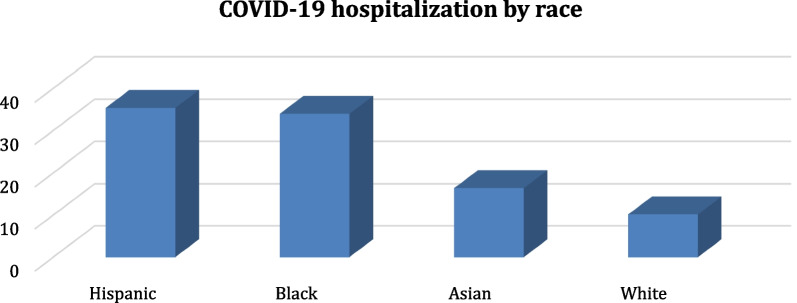
The named entity recognition implementation in the NLP layer achieves a performance gain of about 1-3% compared to benchmark methods. Furthermore, even without extensive data labeling, the relation extraction method outperforms benchmark methods in terms of accuracy (by 1-8% better). A thorough examination reveals the disease's presence and symptoms prevalence in patients.
A similar approach can be generalized to other infectious diseases. It is worthwhile to use prior knowledge acquired through transfer learning when researching other infectious diseases.
提取传染病相关信息是一项重要任务。然而,支持公共卫生研究的一个重大障碍是缺乏有效挖掘大量健康数据的方法。
本研究旨在使用自然语言处理 (NLP) 从文献中的已发表病例中提取关键信息(临床因素、健康的社会决定因素)。
该框架集成了一个数据层,用于从临床病例报告中准备数据队列;一个 NLP 层,用于在文本中找到临床和人口统计学命名实体和关系;以及一个评估层,用于基准性能和分析。本研究的重点是从 COVID-19 病例报告中提取有价值的信息。
NLP 层中的命名实体识别实施在性能上比基准方法提高了约 1-3%。此外,即使没有广泛的数据标注,关系提取方法在准确性方面也优于基准方法(提高了 1-8%)。深入检查揭示了疾病在患者中的存在和症状流行情况。
类似的方法可以推广到其他传染病。在研究其他传染病时,使用通过迁移学习获得的先验知识是值得的。