Mlodzinski Eric, Wardi Gabriel, Viglione Clare, Nemati Shamim, Crotty Alexander Laura, Malhotra Atul
Division of Pulmonary, Critical Care, Sleep and Physiology, University of California, San Diego, CA, United States.
Department of Emergency Medicine, University of California, San Diego, CA, United States.
JMIR Perioper Med. 2023 Jan 27;6:e41056. doi: 10.2196/41056.
Although there is considerable interest in machine learning (ML) and artificial intelligence (AI) in critical care, the implementation of effective algorithms into practice has been limited.
We sought to understand physician perspectives of a novel intubation prediction tool. Further, we sought to understand health care provider and nonprovider perspectives on the use of ML in health care. We aim to use the data gathered to elucidate implementation barriers and determinants of this intubation prediction tool, as well as ML/AI-based algorithms in critical care and health care in general.
We developed 2 anonymous surveys in Qualtrics, 1 single-center survey distributed to 99 critical care physicians via email, and 1 social media survey distributed via Facebook and Twitter with branching logic to tailor questions for providers and nonproviders. The surveys included a mixture of categorical, Likert scale, and free-text items. Likert scale means with SD were reported from 1 to 5. We used student t tests to examine the differences between groups. In addition, Likert scale responses were converted into 3 categories, and percentage values were reported in order to demonstrate the distribution of responses. Qualitative free-text responses were reviewed by a member of the study team to determine validity, and content analysis was performed to determine common themes in responses.
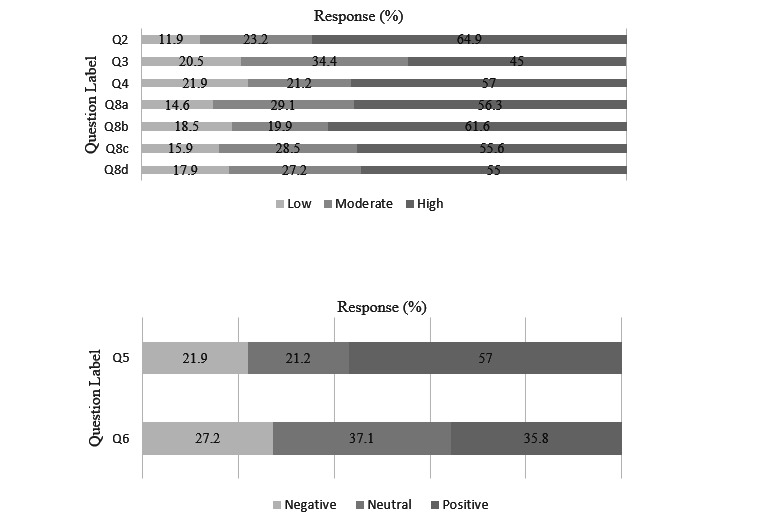
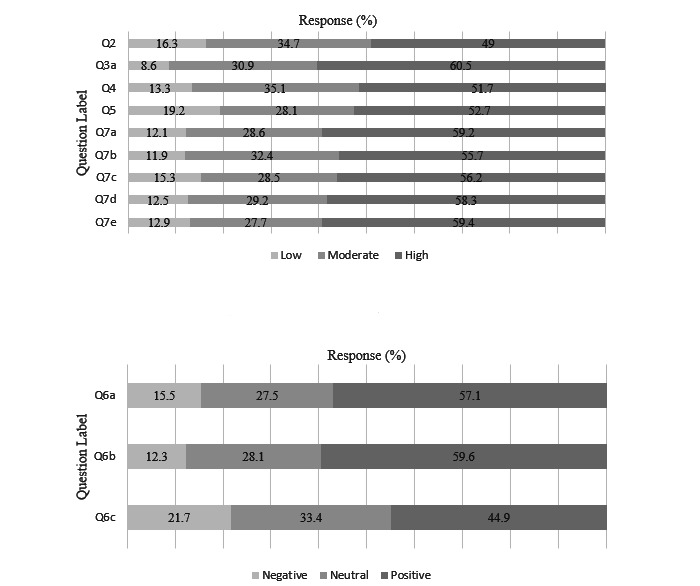
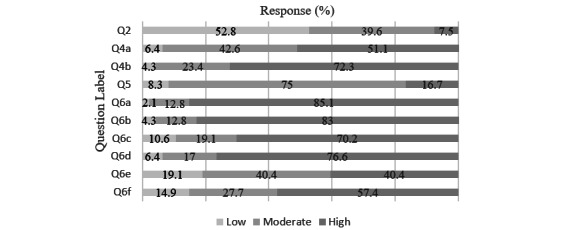
Out of 99 critical care physicians, 47 (48%) completed the single-center survey. Perceived knowledge of ML was low with a mean Likert score of 2.4 out of 5 (SD 0.96), with 7.5% of respondents rating their knowledge as a 4 or 5. The willingness to use the ML-based algorithm was 3.32 out of 5 (SD 0.95), with 75% of respondents answering 3 out of 5. The social media survey had 770 total responses with 605 (79%) providers and 165 (21%) nonproviders. We found no difference in providers' perceived knowledge based on level of experience in either survey. We found that nonproviders had significantly less perceived knowledge of ML (mean 3.04 out of 5, SD 1.53 vs mean 3.43, SD 0.941; P<.001) and comfort with ML (mean 3.28 out of 5, SD 1.02 vs mean 3.53, SD 0.935; P=.004) than providers. Free-text responses revealed multiple shared concerns, including accuracy/reliability, data bias, patient safety, and privacy/security risks.
These data suggest that providers and nonproviders have positive perceptions of ML-based tools, and that a tool to predict the need for intubation would be of interest to critical care providers. There were many shared concerns about ML/AI in health care elucidated by the surveys. These results provide a baseline evaluation of implementation barriers and determinants of ML/AI-based tools that will be important in their optimal implementation and adoption in the critical care setting and health care in general.
尽管重症监护领域对机器学习(ML)和人工智能(AI)兴趣浓厚,但有效的算法在实际应用中的推广却很有限。
我们试图了解医生对一种新型插管预测工具的看法。此外,我们还想了解医疗保健提供者和非提供者对在医疗保健中使用ML的看法。我们旨在利用收集到的数据,阐明该插管预测工具以及重症监护和一般医疗保健中基于ML/AI的算法的实施障碍和决定因素。
我们在Qualtrics中开发了2项匿名调查,一项单中心调查通过电子邮件分发给99名重症监护医生,另一项社交媒体调查通过Facebook和Twitter分发,并采用分支逻辑为提供者和非提供者量身定制问题。调查包括分类、李克特量表和自由文本项目。报告了1至5分的李克特量表平均分及标准差。我们使用学生t检验来检验组间差异。此外,李克特量表的回答被转换为3类,并报告百分比值以展示回答的分布情况。研究团队的一名成员对定性自由文本回答进行了审查以确定其有效性,并进行了内容分析以确定回答中的共同主题。
99名重症监护医生中,47名(48%)完成了单中心调查。对ML的认知度较低,李克特平均得分为2.4分(满分5分,标准差0.96),7.5%的受访者将自己的知识水平评为4分或5分。使用基于ML的算法的意愿得分为3.32分(满分5分,标准差0.95),75%的受访者回答为3分(满分5分)。社交媒体调查共收到770份回复,其中605名(79%)为提供者,165名(21%)为非提供者。在两项调查中,我们均未发现提供者的认知度因经验水平而存在差异。我们发现,非提供者对ML的认知度(平均3.04分,满分5分,标准差1.53,而提供者平均为3.43分,标准差0.941;P<0.001)和对ML的舒适度(平均3.28分,满分5分,标准差1.02,而提供者平均为3.53分,标准差0.935;P=0.004)均显著低于提供者。自由文本回复揭示了多个共同关注的问题,包括准确性/可靠性、数据偏差、患者安全以及隐私/安全风险。
这些数据表明,提供者和非提供者对基于ML的工具持积极看法,并且一种预测插管需求的工具会引起重症监护提供者的兴趣。调查揭示了对医疗保健中ML/AI的许多共同关注问题。这些结果为基于ML/AI的工具的实施障碍和决定因素提供了基线评估,这对于它们在重症监护环境和一般医疗保健中的最佳实施和采用至关重要。