Rousset Adrien, Dellamonica David, Menuet Romuald, Lira Pineda Armando, Sabatine Marc S, Giugliano Robert P, Trichelair Paul, Zaslavskiy Mikhail, Ricci Lea
AMGEN Europe GmbH, Suurstoffi 22, 6343 Rotkreuz ZG, Switzerland.
OWKIN Inc, 831 Broadway, Unit 3R NY 10003 New York City, USA.
Eur Heart J Digit Health. 2021 Nov 15;3(1):38-48. doi: 10.1093/ehjdh/ztab093. eCollection 2022 Mar.
Through this proof of concept, we studied the potential added value of machine learning (ML) methods in building cardiovascular risk scores from structured data and the conditions under which they outperform linear statistical models.
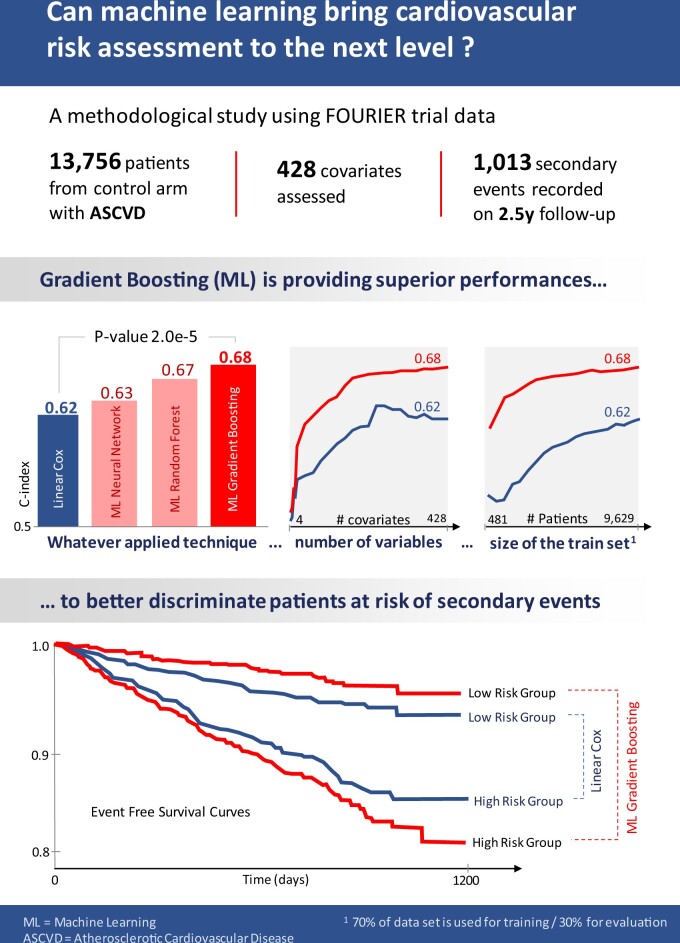
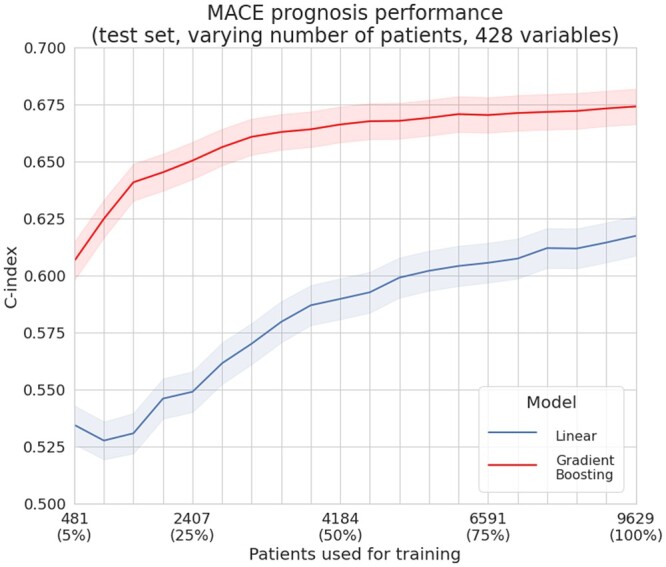
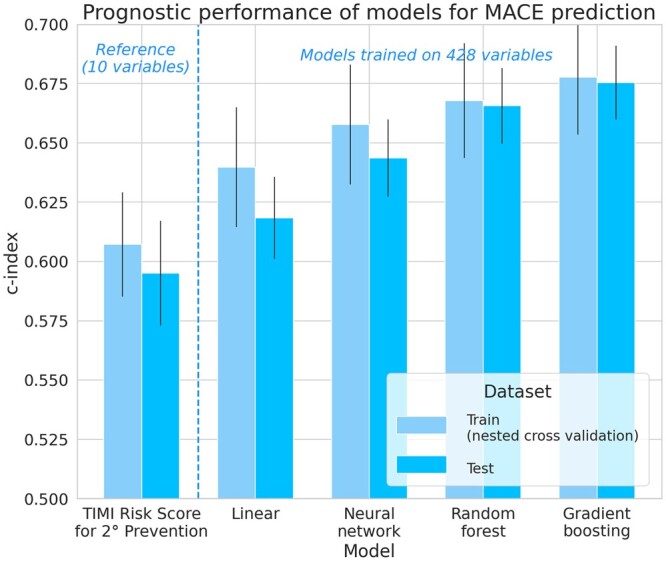
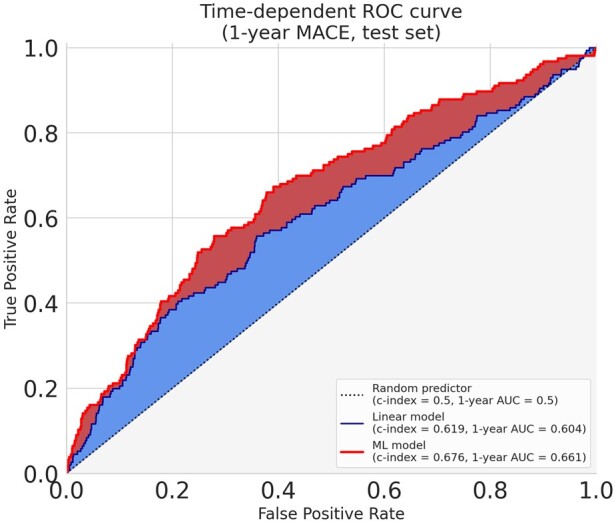
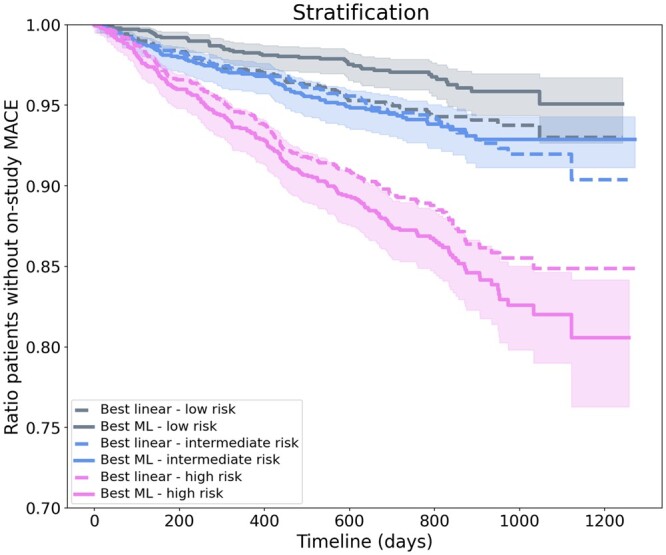
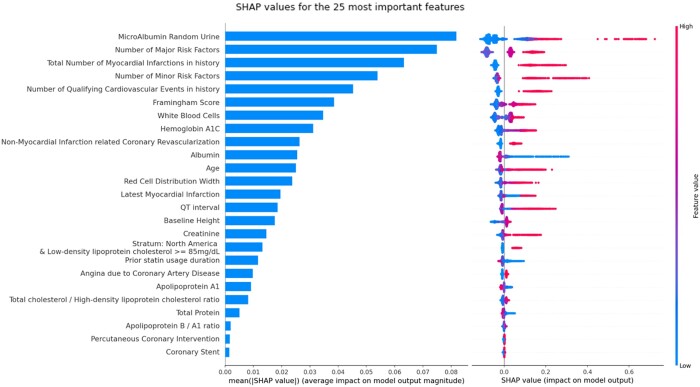
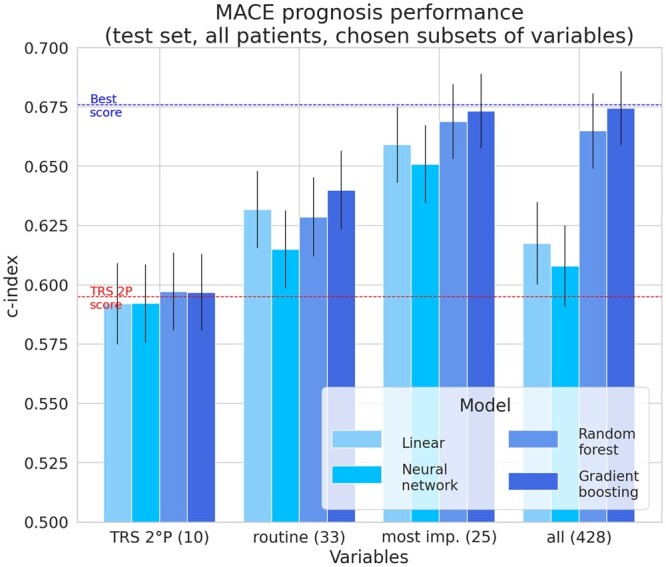
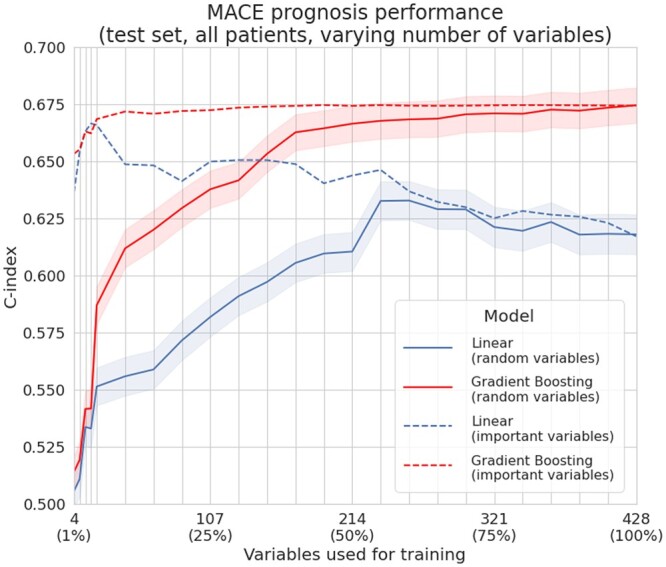
Relying on extensive cardiovascular clinical data from FOURIER, a randomized clinical trial to test for evolocumab efficacy, we compared linear models, neural networks, random forest, and gradient boosting machines for predicting the risk of major adverse cardiovascular events. To study the relative strengths of each method, we extended the comparison to restricted subsets of the full FOURIER dataset, limiting either the number of available patients or the number of their characteristics. When using all the 428 covariates available in the dataset, ML methods significantly (c-index 0.67, -value 2e-5) outperformed linear models built from the same variables (c-index 0.62), as well as a reference cardiovascular risk score based on only 10 variables (c-index 0.60). We showed that gradient boosting-the best performing model in our setting-requires fewer patients and significantly outperforms linear models when using large numbers of variables. On the other hand, we illustrate how linear models suffer from being trained on too many variables, thus requiring a more careful prior selection. These ML methods proved to consistently improve risk assessment, to be interpretable despite their complexity and to help identify the minimal set of covariates necessary to achieve top performance.
In the field of secondary cardiovascular events prevention, given the increased availability of extensive electronic health records, ML methods could open the door to more powerful tools for patient risk stratification and treatment allocation strategies.
通过本概念验证,我们研究了机器学习(ML)方法在根据结构化数据构建心血管风险评分方面的潜在附加价值,以及它们优于线性统计模型的条件。
依托FOURIER(一项测试依洛尤单抗疗效的随机临床试验)的大量心血管临床数据,我们比较了线性模型、神经网络、随机森林和梯度提升机在预测主要不良心血管事件风险方面的表现。为研究每种方法的相对优势,我们将比较扩展至完整FOURIER数据集的受限子集,限制可用患者数量或其特征数量。当使用数据集中可用的所有428个协变量时,ML方法显著(c指数为0.67,P值为2e - 5)优于基于相同变量构建的线性模型(c指数为0.62),以及仅基于10个变量的参考心血管风险评分(c指数为0.60)。我们表明,梯度提升(在我们的研究中表现最佳的模型)需要的患者较少,并且在使用大量变量时显著优于线性模型。另一方面,我们说明了线性模型在过多变量上进行训练时会受到影响,因此需要更谨慎的先验选择。这些ML方法被证明能够持续改善风险评估,尽管其具有复杂性但仍可解释,并且有助于确定实现最佳性能所需的最小协变量集。
在二级心血管事件预防领域,鉴于广泛的电子健康记录可用性增加,ML方法可为患者风险分层和治疗分配策略带来更强大的工具。