Faculté de Pharmacie, Université Laval, Québec, QC, Canada.
Département de Médecine de Famille et de Médecine d'urgence, Faculté de Médecine et des Sciences de la Santé, Université de Sherbrooke, Sherbrooke, QC, Canada.
Sci Rep. 2023 Feb 3;13(1):1981. doi: 10.1038/s41598-023-27568-6.
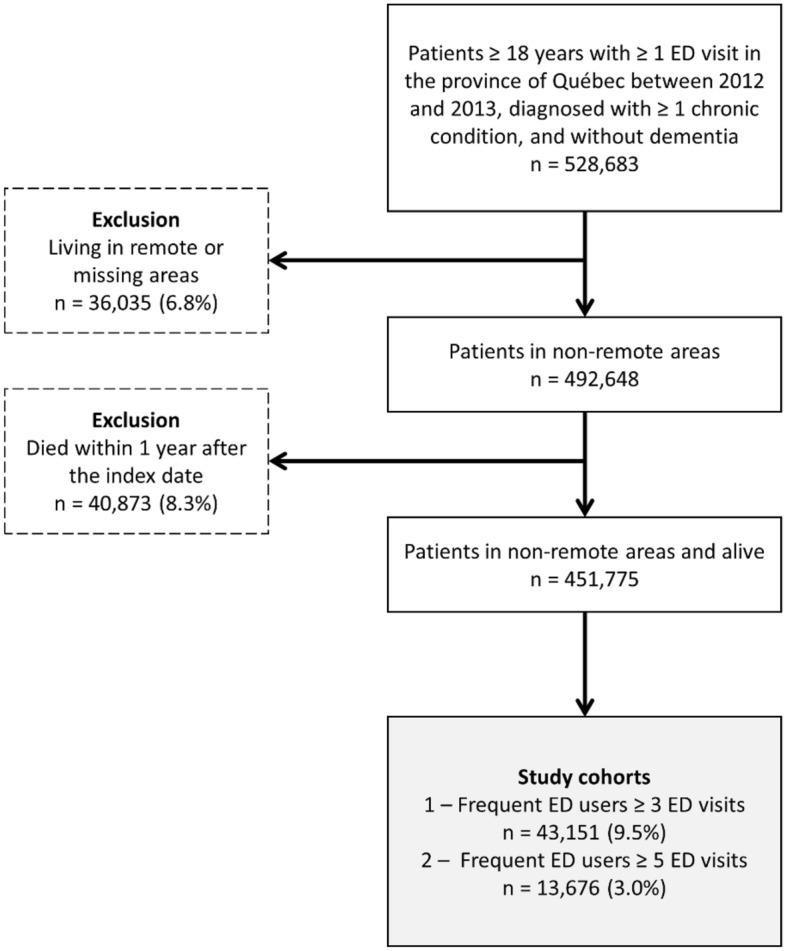
Frequent emergency department use is associated with many adverse events, such as increased risk for hospitalization and mortality. Frequent users have complex needs and associated factors are commonly evaluated using logistic regression. However, other machine learning models, especially those exploiting the potential of large databases, have been less explored. This study aims at comparing the performance of logistic regression to four machine learning models for predicting frequent emergency department use in an adult population with chronic diseases, in the province of Quebec (Canada). This is a retrospective population-based study using medical and administrative databases from the Régie de l'assurance maladie du Québec. Two definitions were used for frequent emergency department use (outcome to predict): having at least three and five visits during a year period. Independent variables included sociodemographic characteristics, healthcare service use, and chronic diseases. We compared the performance of logistic regression with gradient boosting machine, naïve Bayes, neural networks, and random forests (binary and continuous outcome) using Area under the ROC curve, sensibility, specificity, positive predictive value, and negative predictive value. Out of 451,775 ED users, 43,151 (9.5%) and 13,676 (3.0%) were frequent users with at least three and five visits per year, respectively. Random forests with a binary outcome had the lowest performances (ROC curve: 53.8 [95% confidence interval 53.5-54.0] and 51.4 [95% confidence interval 51.1-51.8] for frequent users 3 and 5, respectively) while the other models had superior and overall similar performance. The most important variable in prediction was the number of emergency department visits in the previous year. No model outperformed the others. Innovations in algorithms may slightly refine current predictions, but access to other variables may be more helpful in the case of frequent emergency department use prediction.
频繁使用急诊部门与许多不良事件相关,例如住院和死亡风险增加。频繁使用者有复杂的需求,常用逻辑回归评估相关因素。然而,其他机器学习模型,尤其是利用大型数据库潜力的模型,研究较少。本研究旨在比较逻辑回归和四种机器学习模型在预测魁北克省(加拿大)慢性疾病成年人群中频繁使用急诊部门的性能。这是一项使用魁北克省医疗和行政数据库的回顾性基于人群的研究。频繁使用急诊部门(预测结果)有两种定义:一年内至少有三次和五次就诊。自变量包括社会人口统计学特征、医疗服务使用情况和慢性疾病。我们比较了逻辑回归与梯度提升机、朴素贝叶斯、神经网络和随机森林(二分类和连续结果)的性能,使用 ROC 曲线下面积、敏感性、特异性、阳性预测值和阴性预测值进行评估。在 451775 名急诊部门使用者中,43151 名(9.5%)和 13676 名(3.0%)分别为每年至少有三次和五次就诊的频繁使用者。二分类随机森林的性能最低(ROC 曲线:频繁就诊 3 次和 5 次的曲线下面积分别为 53.8 [95%置信区间 53.5-54.0]和 51.4 [95%置信区间 51.1-51.8]),而其他模型的性能更好且总体相似。预测中最重要的变量是前一年急诊就诊次数。没有模型优于其他模型。算法的创新可能会略微改进当前的预测,但在预测频繁使用急诊部门时,访问其他变量可能更有帮助。