Djaffardjy Marine, Marchment George, Sebe Clémence, Blanchet Raphael, Bellajhame Khalid, Gaignard Alban, Lemoine Frédéric, Cohen-Boulakia Sarah
Universite Paris-Saclay, CNRS, Laboratoire Interdisciplinaire des Sciences du Numérique, Orsay 91405, France.
Nantes Université, CNRS, INSERM, l'institut du thorax, 8 quai Moncousu, Nantes F-44000, France.
Comput Struct Biotechnol J. 2023 Mar 7;21:2075-2085. doi: 10.1016/j.csbj.2023.03.003. eCollection 2023.
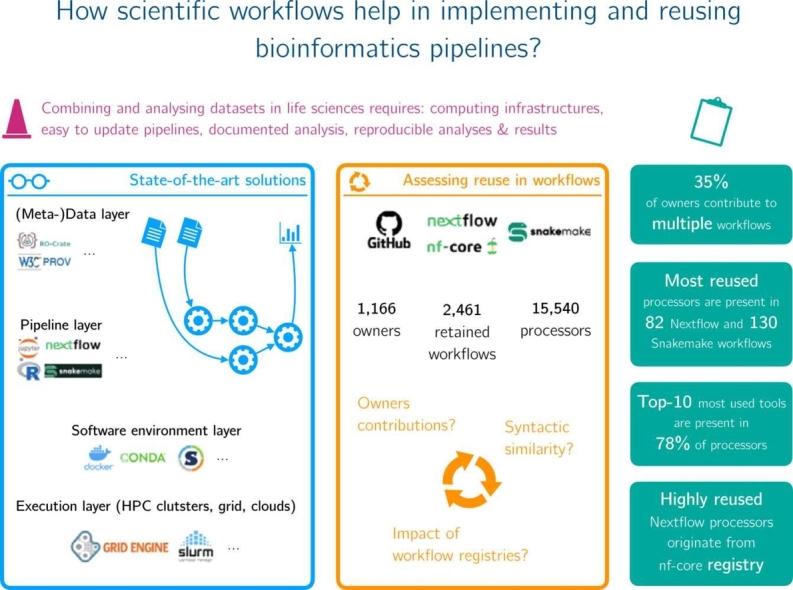
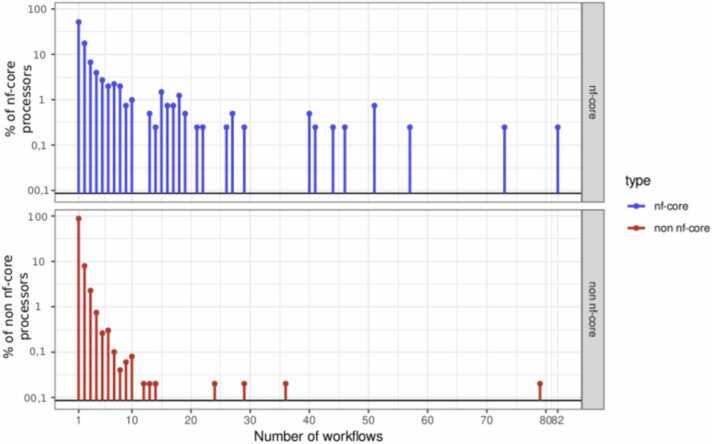
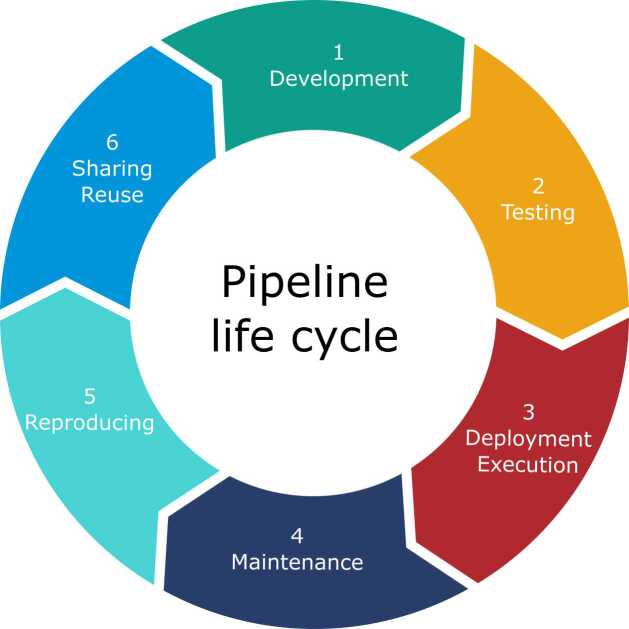
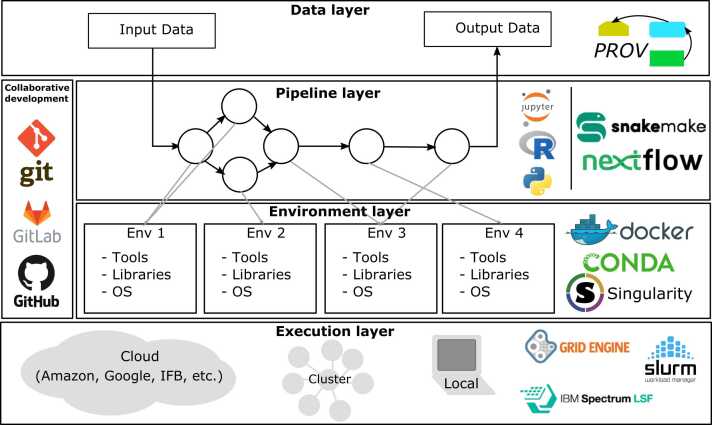
Data analysis pipelines are now established as an effective means for specifying and executing bioinformatics data analysis and experiments. While scripting languages, particularly Python, R and notebooks, are popular and sufficient for developing small-scale pipelines that are often intended for a single user, it is now widely recognized that they are by no means enough to support the development of large-scale, shareable, maintainable and reusable pipelines capable of handling large volumes of data and running on high performance computing clusters. This review outlines the key requirements for building large-scale data pipelines and provides a mapping of existing solutions that fulfill them. We then highlight the benefits of using scientific workflow systems to get modular, reproducible and reusable bioinformatics data analysis pipelines. We finally discuss current workflow reuse practices based on an empirical study we performed on a large collection of workflows.
数据分析管道现已成为指定和执行生物信息学数据分析及实验的有效手段。虽然脚本语言,特别是Python、R和笔记本,很受欢迎且足以开发通常供单个用户使用的小规模管道,但现在人们普遍认识到,它们远远不足以支持开发能够处理大量数据并在高性能计算集群上运行的大规模、可共享、可维护和可重用的管道。本综述概述了构建大规模数据管道的关键要求,并提供了满足这些要求的现有解决方案的映射。然后,我们强调了使用科学工作流系统来获得模块化、可重复和可重用的生物信息学数据分析管道的好处。最后,我们基于对大量工作流进行的实证研究,讨论了当前的工作流重用实践。