Krassowski Michal, Das Vivek, Sahu Sangram K, Misra Biswapriya B
Nuffield Department of Women's & Reproductive Health, University of Oxford, Oxford, United Kingdom.
Novo Nordisk Research Center Seattle, Inc, Seattle, WA, United States.
Front Genet. 2020 Dec 10;11:610798. doi: 10.3389/fgene.2020.610798. eCollection 2020.
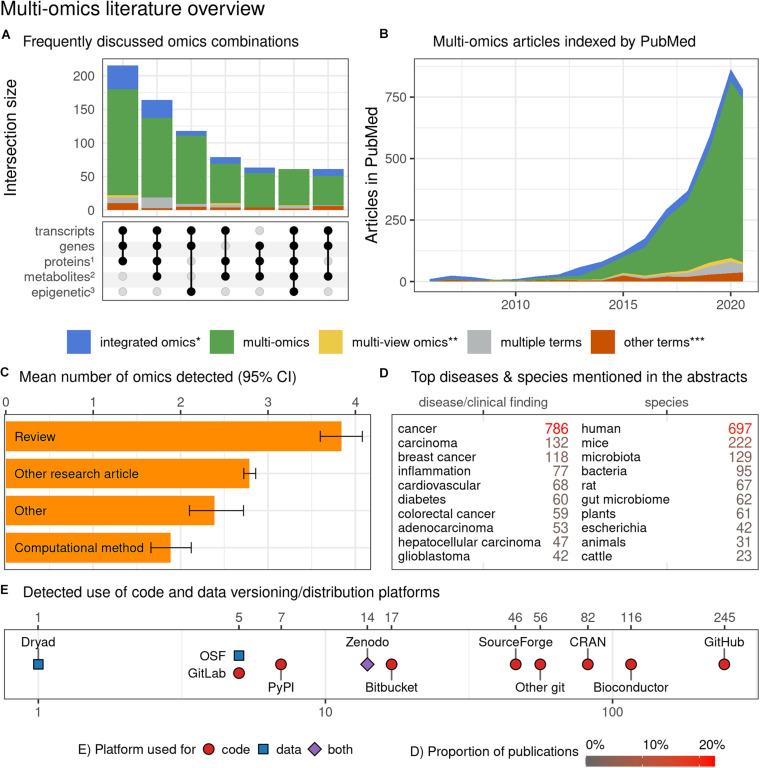
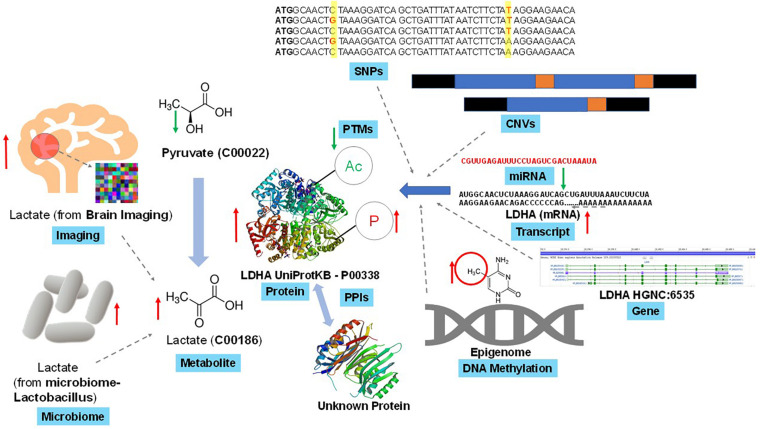
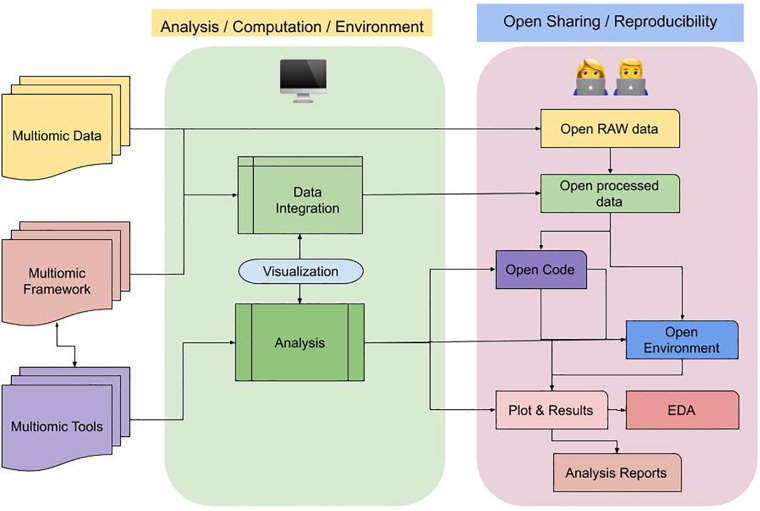
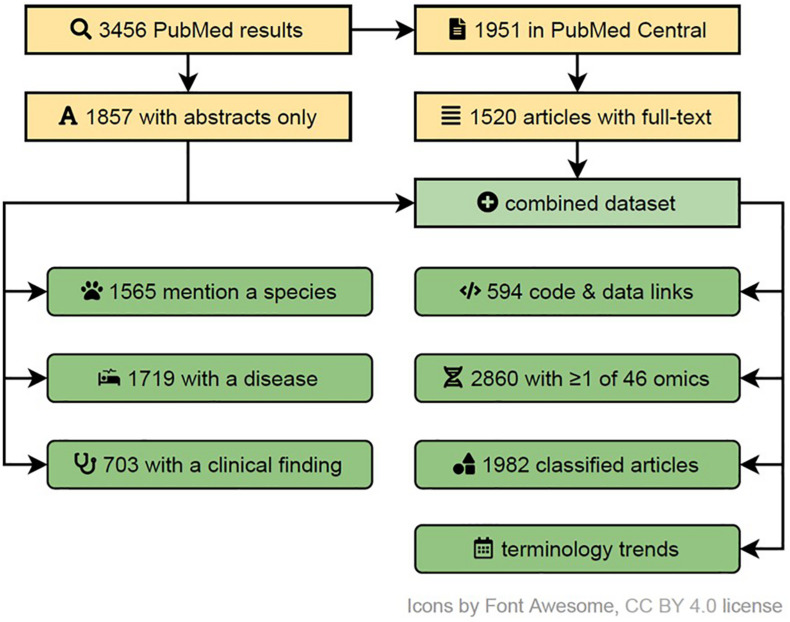
Multi-omics, variously called integrated omics, pan-omics, and trans-omics, aims to combine two or more omics data sets to aid in data analysis, visualization and interpretation to determine the mechanism of a biological process. Multi-omics efforts have taken center stage in biomedical research leading to the development of new insights into biological events and processes. However, the mushrooming of a myriad of tools, datasets, and approaches tends to inundate the literature and overwhelm researchers new to the field. The aims of this review are to provide an overview of the current state of the field, inform on available reliable resources, discuss the application of statistics and machine/deep learning in multi-omics analyses, discuss findable, accessible, interoperable, reusable (FAIR) research, and point to best practices in benchmarking. Thus, we provide guidance to interested users of the domain by addressing challenges of the underlying biology, giving an overview of the available toolset, addressing common pitfalls, and acknowledging current methods' limitations. We conclude with practical advice and recommendations on software engineering and reproducibility practices to share a comprehensive awareness with new researchers in multi-omics for end-to-end workflow.
多组学,也被称为整合组学、全景组学和跨组学,旨在将两个或更多组学数据集结合起来,以辅助数据分析、可视化和解读,从而确定生物过程的机制。多组学研究在生物医学研究中占据了核心地位,为深入了解生物事件和过程带来了新的见解。然而,大量工具、数据集和方法的涌现往往使文献泛滥,让该领域的新手研究人员应接不暇。本综述的目的是概述该领域的现状,介绍可用的可靠资源,讨论统计学以及机器学习/深度学习在多组学分析中的应用,探讨可查找、可访问、可互操作、可重用(FAIR)研究,并指出基准测试的最佳实践。因此,我们通过应对基础生物学的挑战、概述可用的工具集、解决常见陷阱以及认识当前方法的局限性,为该领域感兴趣的用户提供指导。我们最后给出关于软件工程和可重复性实践的实用建议和推荐,以便与多组学领域的新研究人员分享关于端到端工作流程的全面认识。