Hou Wenpin, Shang Xinyi, Ji Zhicheng
Department of Biostatistics, The Mailman School of Public Health, Columbia University, New York City, NY, USA.
Department of Biostatistics and Bioinformatics, Duke University School of Medicine, Durham, NC, USA.
bioRxiv. 2025 Jan 5:2023.03.11.532238. doi: 10.1101/2023.03.11.532238.
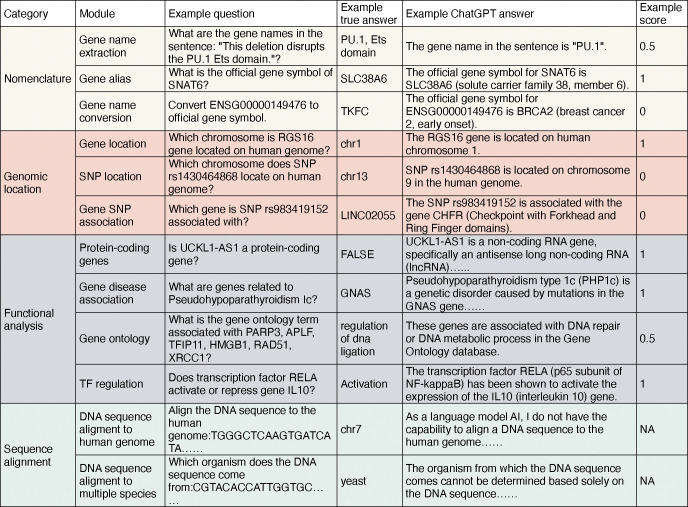
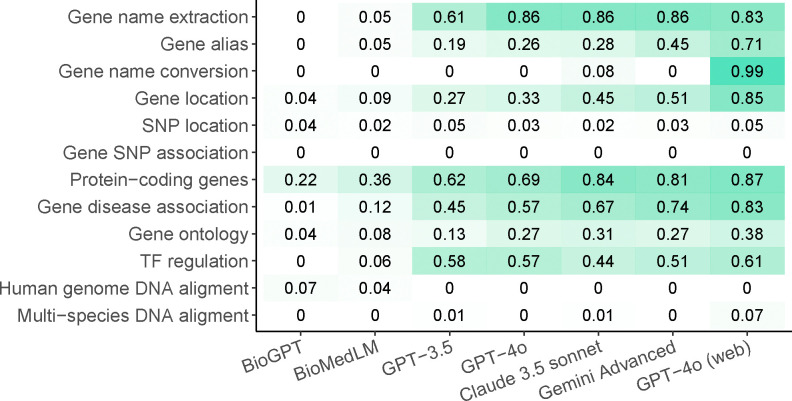
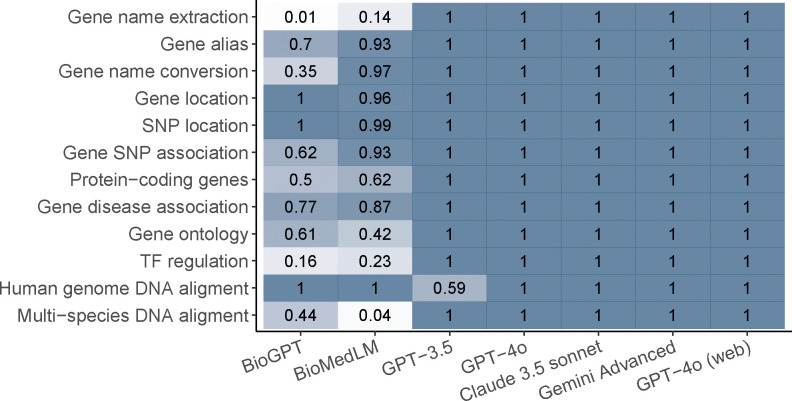
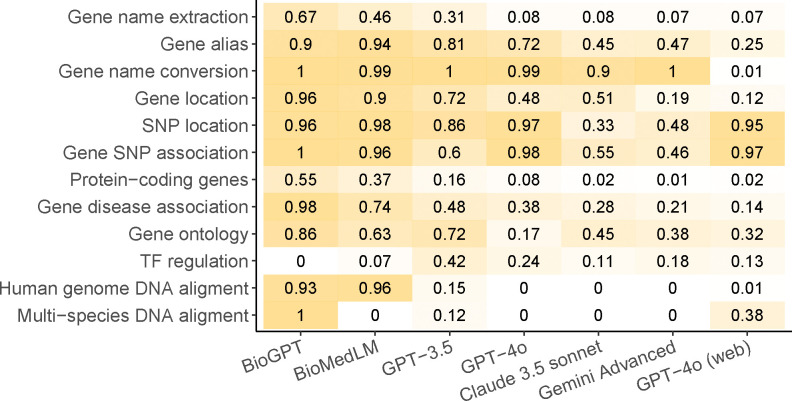
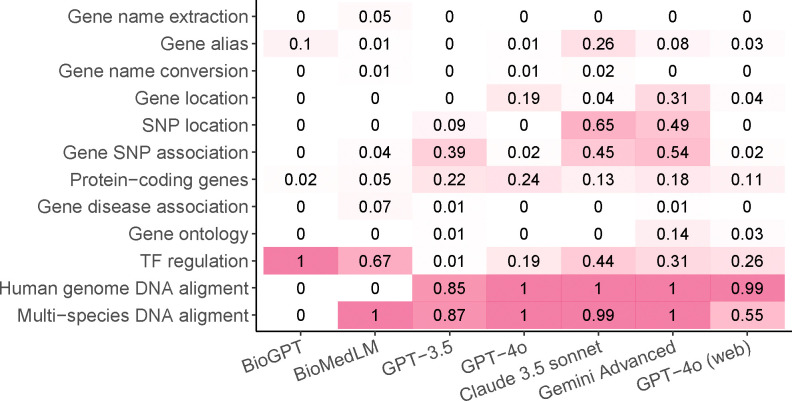
Large language models have demonstrated great potential in biomedical research. However, their ability to serve as a knowledge base for genomic research remains unknown. We developed GeneTuring, a comprehensive Q&A database containing 1,200 questions in genomics, and manually scored 25,200 answers provided by six GPT models, including GPT-4o, Claude 3.5, and Gemini Advanced. GPT-4o with web access showed the best overall performance and excelled in most tasks. However, it still failed to correctly answer all questions and may not be fully reliable for providing answers to genomic inquiries.
大语言模型在生物医学研究中已展现出巨大潜力。然而,其作为基因组研究知识库的能力仍不明确。我们开发了GeneTuring,这是一个包含1200个基因组学问题的综合问答数据库,并对包括GPT-4o、Claude 3.5和Gemini Advanced在内的六个GPT模型提供的25200个答案进行了人工评分。具备网络访问权限的GPT-4o总体表现最佳,在大多数任务中表现出色。然而,它仍未能正确回答所有问题,在为基因组学问题提供答案时可能并不完全可靠。