Chongqing Key Laboratory of Big Data for Bio Intelligence, Chongqing University of Posts and Telecommunications, Chongqing 400065, China.
State Key Laboratory of Proteomics, Beijing Proteome Research Center, National Center for Protein Sciences (Beijing), Beijing Institute of Life Omics, Beijing 102206, China.
J Proteome Res. 2023 Jun 2;22(6):2114-2123. doi: 10.1021/acs.jproteome.2c00812. Epub 2023 May 23.
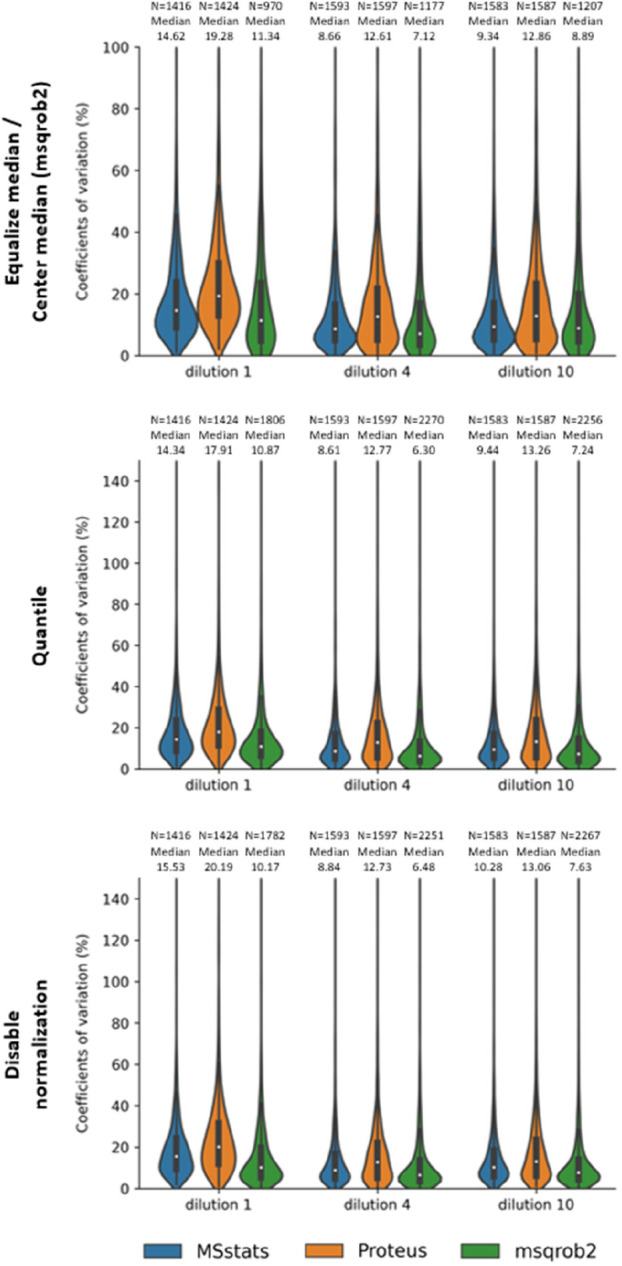
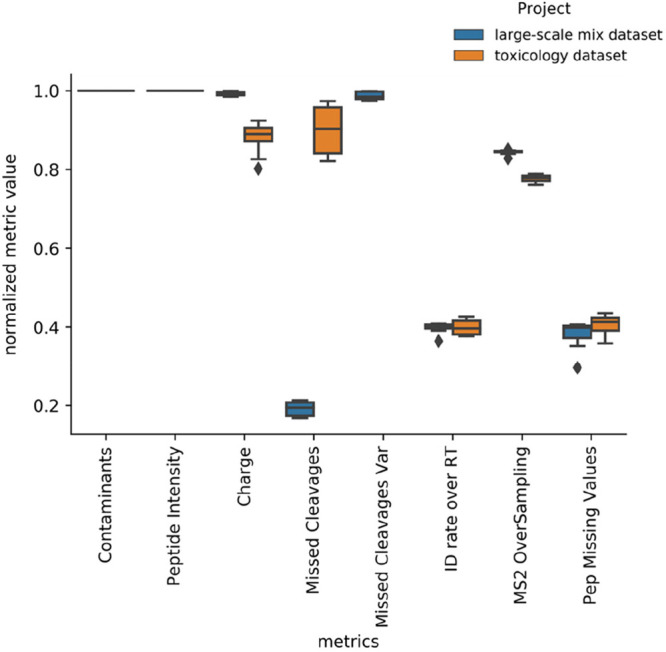
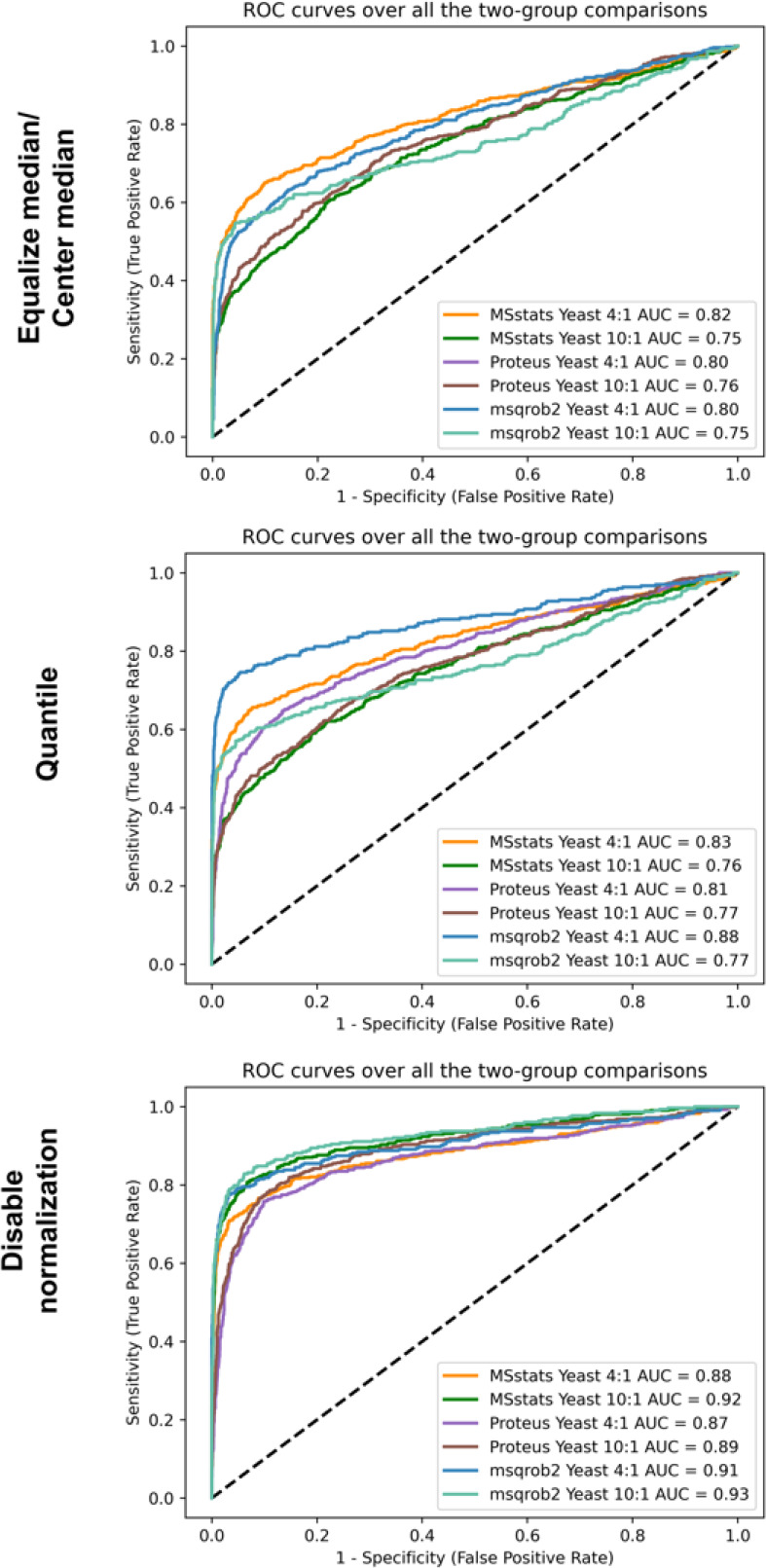
Testing for significant differences in quantities at the protein level is a common goal of many LFQ-based mass spectrometry proteomics experiments. Starting from a table of protein and/or peptide quantities from a given proteomics quantification software, many tools and R packages exist to perform the final tasks of imputation, summarization, normalization, and statistical testing. To evaluate the effects of packages and settings in their substeps on the final list of significant proteins, we studied several packages on three public data sets with known expected protein fold changes. We found that the results between packages and even across different parameters of the same package can vary significantly. In addition to usability aspects and feature/compatibility lists of different packages, this paper highlights sensitivity and specificity trade-offs that come with specific packages and settings.
在基于 LFQ 的质谱蛋白质组学实验中,检测蛋白质水平上的显著差异是许多实验的共同目标。从给定的蛋白质组学定量软件的蛋白质和/或肽量表开始,有许多工具和 R 包可用于执行最后的插补、汇总、归一化和统计检验任务。为了评估在其子步骤中包和设置对显著蛋白质最终列表的影响,我们使用三个具有已知预期蛋白质折叠变化的公共数据集研究了几个包。我们发现,包之间的结果,甚至同一包的不同参数之间的结果差异都非常大。除了不同包的可用性方面和功能/兼容性列表外,本文还强调了特定包和设置所带来的灵敏度和特异性权衡。