School of Computer Science and Technology, Beijing Institute of Technology, Beijing, China.
Advanced Research Institute of Multidisciplinary Science, Beijing Institute of Technology, Beijing, China.
PLoS Comput Biol. 2023 Jun 20;19(6):e1011214. doi: 10.1371/journal.pcbi.1011214. eCollection 2023 Jun.
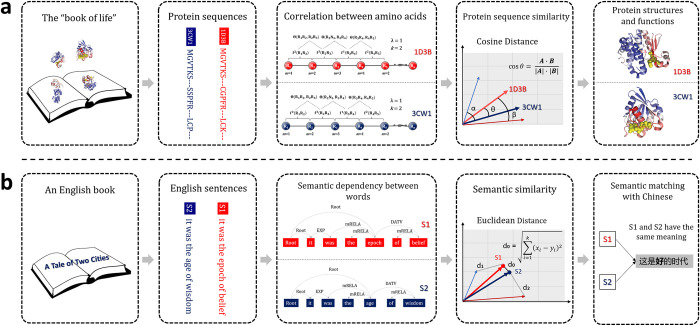
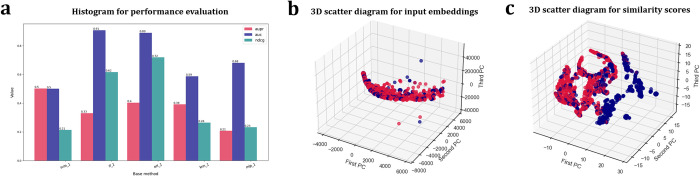
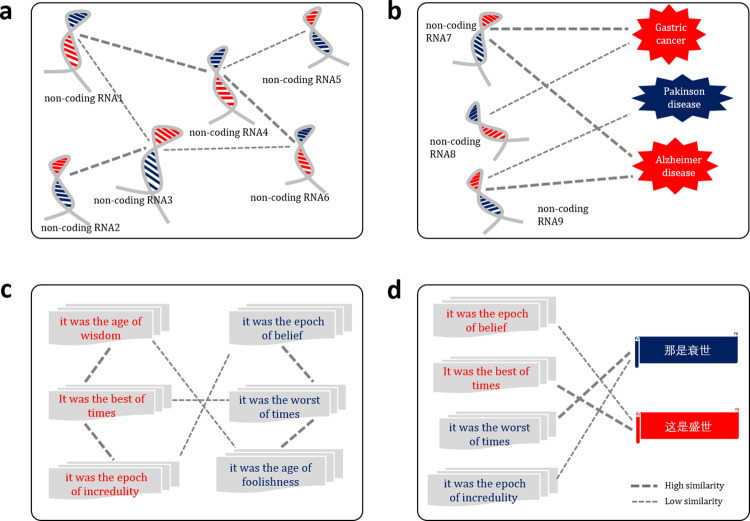
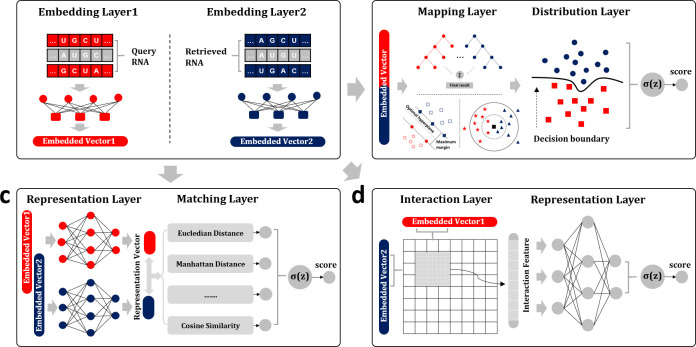
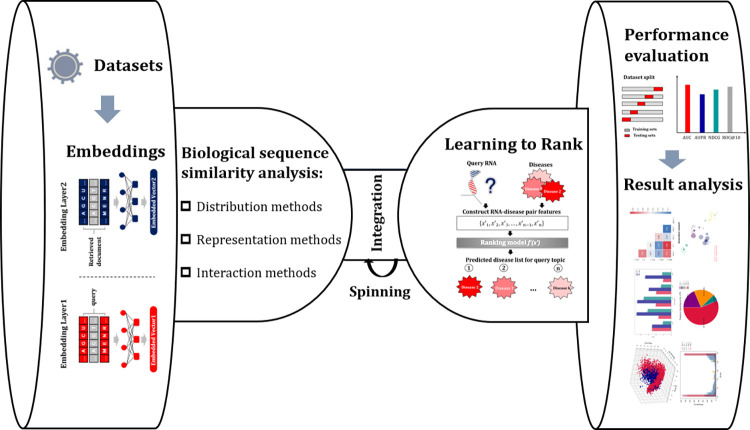
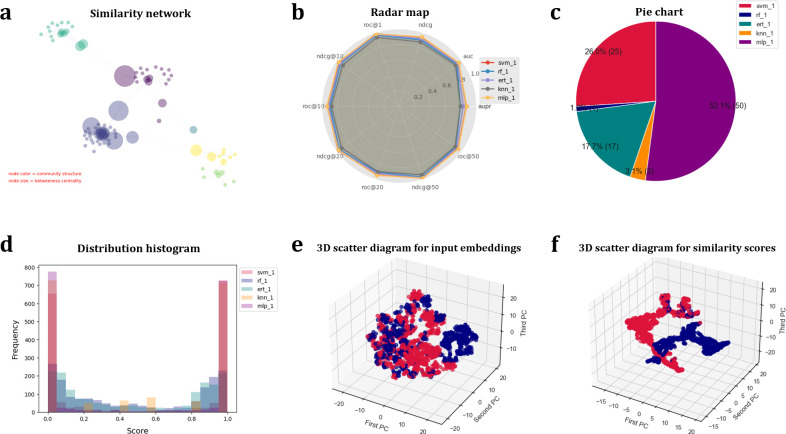
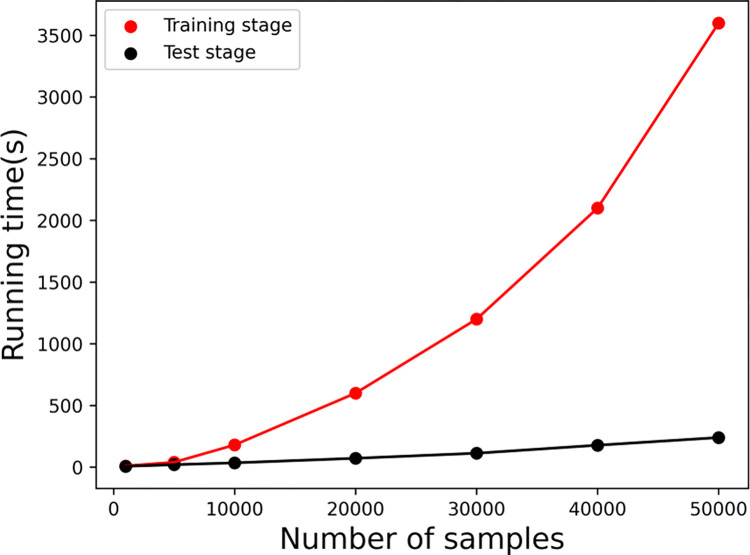
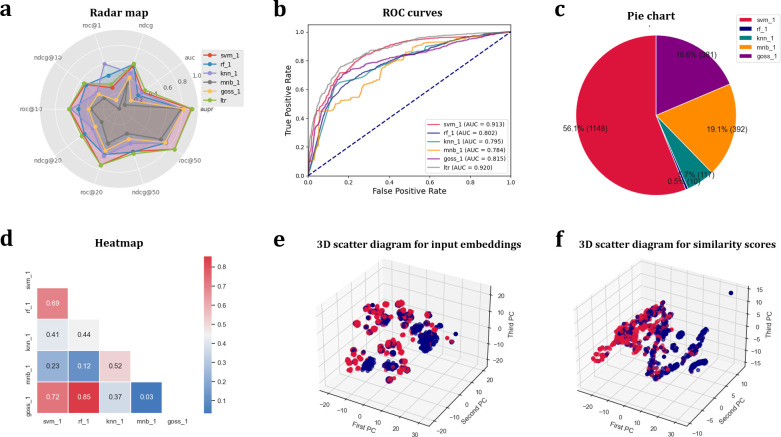
As the key for biological sequence structure and function prediction, disease diagnosis and treatment, biological sequence similarity analysis has attracted more and more attentions. However, the exiting computational methods failed to accurately analyse the biological sequence similarities because of the various data types (DNA, RNA, protein, disease, etc) and their low sequence similarities (remote homology). Therefore, new concepts and techniques are desired to solve this challenging problem. Biological sequences (DNA, RNA and protein sequences) can be considered as the sentences of "the book of life", and their similarities can be considered as the biological language semantics (BLS). In this study, we are seeking the semantics analysis techniques derived from the natural language processing (NLP) to comprehensively and accurately analyse the biological sequence similarities. 27 semantics analysis methods derived from NLP were introduced to analyse biological sequence similarities, bringing new concepts and techniques to biological sequence similarity analysis. Experimental results show that these semantics analysis methods are able to facilitate the development of protein remote homology detection, circRNA-disease associations identification and protein function annotation, achieving better performance than the other state-of-the-art predictors in the related fields. Based on these semantics analysis methods, a platform called BioSeq-Diabolo has been constructed, which is named after a popular traditional sport in China. The users only need to input the embeddings of the biological sequence data. BioSeq-Diabolo will intelligently identify the task, and then accurately analyse the biological sequence similarities based on biological language semantics. BioSeq-Diabolo will integrate different biological sequence similarities in a supervised manner by using Learning to Rank (LTR), and the performance of the constructed methods will be evaluated and analysed so as to recommend the best methods for the users. The web server and stand-alone package of BioSeq-Diabolo can be accessed at http://bliulab.net/BioSeq-Diabolo/server/.
作为生物序列结构和功能预测、疾病诊断和治疗的关键,生物序列相似性分析越来越受到关注。然而,由于数据类型(DNA、RNA、蛋白质、疾病等)的多样性以及它们之间的低序列相似性(远缘同源性),现有的计算方法无法准确分析生物序列相似性。因此,需要新的概念和技术来解决这个具有挑战性的问题。生物序列(DNA、RNA 和蛋白质序列)可以被视为“生命之书”的句子,它们的相似性可以被视为生物语言语义(BLS)。在本研究中,我们正在寻找源自自然语言处理(NLP)的语义分析技术,以全面准确地分析生物序列相似性。本文介绍了 27 种源自 NLP 的语义分析方法,用于分析生物序列相似性,为生物序列相似性分析带来了新的概念和技术。实验结果表明,这些语义分析方法能够促进蛋白质远程同源性检测、环状 RNA 与疾病关联识别和蛋白质功能注释的发展,在相关领域的其他最先进预测器中表现出更好的性能。基于这些语义分析方法,构建了一个名为 BioSeq-Diabolo 的平台,它以中国流行的传统运动命名。用户只需输入生物序列数据的嵌入即可。BioSeq-Diabolo 将智能识别任务,然后基于生物语言语义准确分析生物序列相似性。BioSeq-Diabolo 将通过学习排序(LTR)以监督方式集成不同的生物序列相似性,并评估和分析所构建方法的性能,以向用户推荐最佳方法。BioSeq-Diabolo 的网络服务器和独立包可在 http://bliulab.net/BioSeq-Diabolo/server/ 访问。