Department of Advanced Robotics, Istituto Italiano di Tecnologia, Genoa, Italy.
Department of Electronic, Information and Bioengineering, Politecnico di Milano, Milan, Italy.
Int J Comput Assist Radiol Surg. 2023 Dec;18(12):2349-2356. doi: 10.1007/s11548-023-02974-3. Epub 2023 Aug 16.
Fetoscopic laser photocoagulation of placental anastomoses is the most effective treatment for twin-to-twin transfusion syndrome (TTTS). A robust mosaic of placenta and its vascular network could support surgeons' exploration of the placenta by enlarging the fetoscope field-of-view. In this work, we propose a learning-based framework for field-of-view expansion from intra-operative video frames.
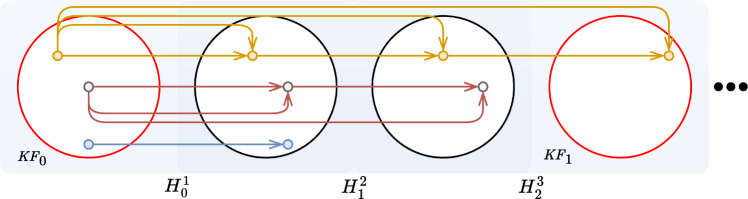
While current state of the art for fetoscopic mosaicking builds upon the registration of anatomical landmarks which may not always be visible, our framework relies on learning-based features and keypoints, as well as robust transformer-based image-feature matching, without requiring any anatomical priors. We further address the problem of occlusion recovery and frame relocalization, relying on the computed features and their descriptors.
Experiments were conducted on 10 in-vivo TTTS videos from two different fetal surgery centers. The proposed framework was compared with several state-of-the-art approaches, achieving higher [Formula: see text] on 7 out of 10 videos and a success rate of [Formula: see text] in occlusion recovery.
This work introduces a learning-based framework for placental mosaicking with occlusion recovery from intra-operative videos using a keypoint-based strategy and features. The proposed framework can compute the placental panorama and recover even in case of camera tracking loss where other methods fail. The results suggest that the proposed framework has large potential to pave the way to creating a surgical navigation system for TTTS by providing robust field-of-view expansion.
胎盘吻合处的胎儿镜激光光凝是治疗双胎输血综合征(TTTS)最有效的方法。胎盘及其血管网络的强大马赛克可以通过扩大胎儿镜的视野来支持外科医生对胎盘的探索。在这项工作中,我们提出了一种基于学习的框架,用于从术中视频帧扩展视野。
虽然当前的胎儿镜马赛克技术基于解剖学标志的注册,而这些标志并不总是可见的,但我们的框架依赖于基于学习的特征和关键点,以及基于稳健的转换器的图像特征匹配,而不需要任何解剖学先验知识。我们进一步解决了遮挡物恢复和帧重新定位的问题,依赖于计算出的特征及其描述符。
在来自两个不同胎儿手术中心的 10 个体内 TTTS 视频上进行了实验。将所提出的框架与几种最先进的方法进行了比较,在 10 个视频中的 7 个视频上实现了更高的[公式:见文本],并且遮挡物恢复的成功率达到了[公式:见文本]。
这项工作介绍了一种基于学习的框架,用于使用基于关键点的策略和特征从术中视频中进行带有遮挡物恢复的胎盘马赛克处理。所提出的框架可以计算胎盘全景图,即使在其他方法失败的情况下,也可以在摄像机跟踪丢失的情况下进行恢复。结果表明,该框架具有很大的潜力,可以通过提供稳健的视野扩展,为 TTTS 创建手术导航系统铺平道路。