Xiamen University, Xiamen, China.
Tianjin University, Tianjin, China.
BMC Bioinformatics. 2023 Aug 29;24(1):325. doi: 10.1186/s12859-023-05453-3.
There are countless possibilities for drug combinations, which makes it expensive and time-consuming to rely solely on clinical trials to determine the effects of each possible drug combination. In order to screen out the most effective drug combinations more quickly, scholars began to apply machine learning to drug combination prediction. However, most of them are of low interpretability. Consequently, even though they can sometimes produce high prediction accuracy, experts in the medical and biological fields can still not fully rely on their judgments because of the lack of knowledge about the decision-making process.
Decision trees and their ensemble algorithms are considered to be suitable methods for pharmaceutical applications due to their excellent performance and good interpretability. We review existing decision trees or decision tree ensemble algorithms in the medical field and point out their shortcomings.
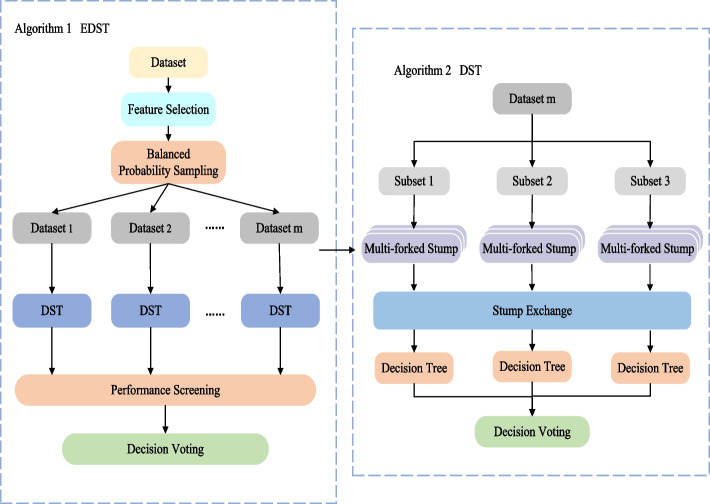
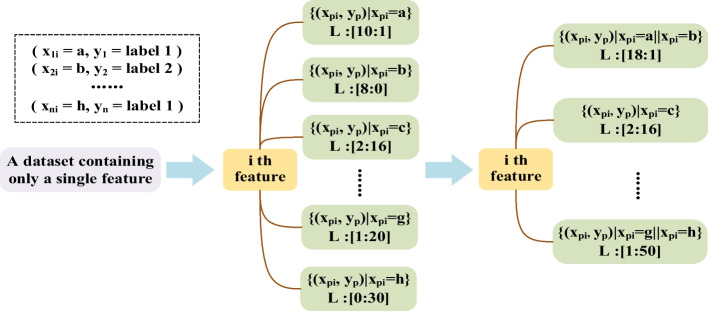
This study proposes a decision stump (DS)-based solution to extract interpretable knowledge from data sets. In this method, a set of DSs is first generated to selectively form a decision tree (DST). Different from the traditional decision tree, our algorithm not only enables a partial exchange of information between base classifiers by introducing a stump exchange method but also uses a modified Gini index to evaluate stump performance so that the generation of each node is evaluated by a global view to maintain high generalization ability. Furthermore, these trees are combined to construct an ensemble of DST (EDST).
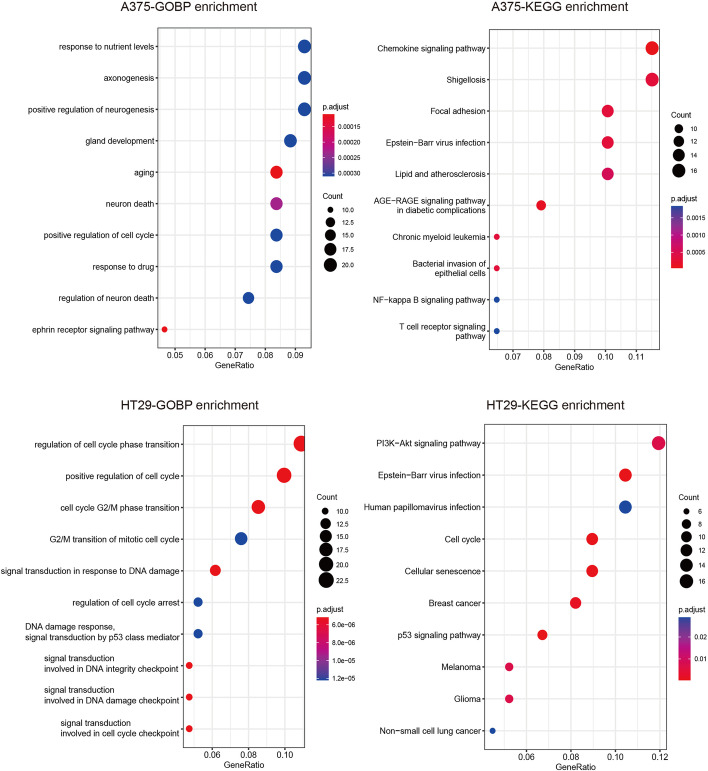
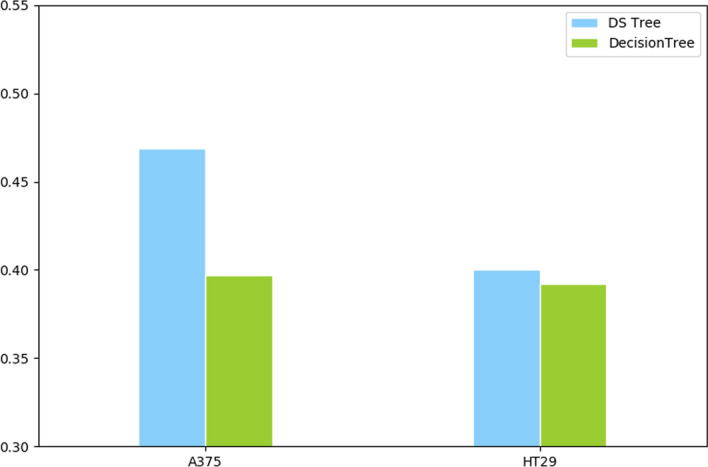
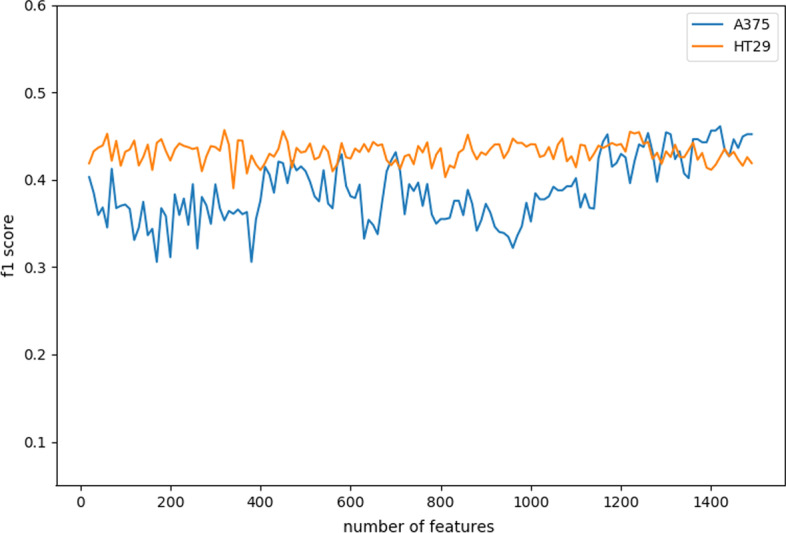
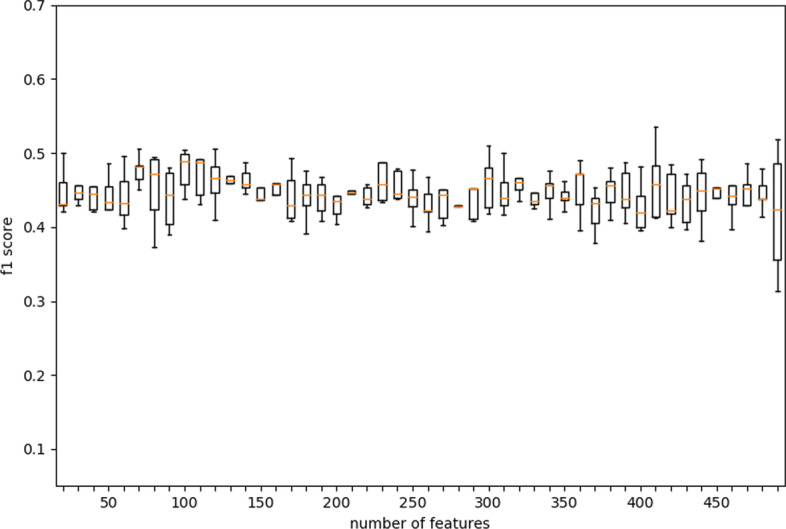
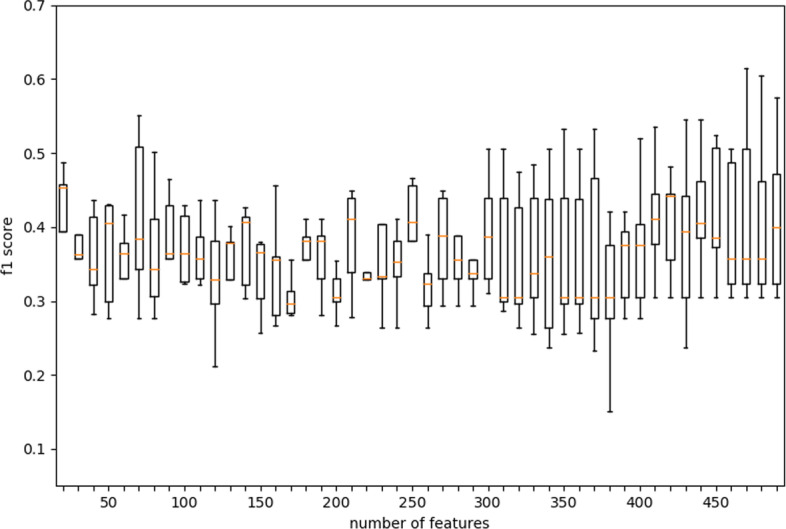
The two-drug combination data sets are collected from two cell lines with three classes (additive, antagonistic and synergistic effects) to test our method. Experimental results show that both our DST and EDST perform better than other methods. Besides, the rules generated by our methods are more compact and more accurate than other rule-based algorithms. Finally, we also analyze the extracted knowledge by the model in the field of bioinformatics.
The novel decision tree ensemble model can effectively predict the effect of drug combination datasets and easily obtain the decision-making process.
药物组合有无数种可能性,仅依靠临床试验来确定每种可能的药物组合的效果既昂贵又耗时。为了更快地筛选出最有效的药物组合,学者们开始将机器学习应用于药物组合预测。然而,它们大多缺乏可解释性。因此,尽管它们有时可以产生较高的预测准确性,但医学和生物学领域的专家仍然不能完全依赖他们的判断,因为他们缺乏对决策过程的了解。
决策树及其集成算法由于其出色的性能和良好的可解释性,被认为是适合药物应用的方法。我们回顾了医学领域现有的决策树或决策树集成算法,并指出了它们的缺点。
本研究提出了一种基于决策树桩(Decision Stump,DS)的解决方案,从数据集提取可解释的知识。在该方法中,首先生成一组 DS 来选择性地形成决策树(Decision Tree,DST)。与传统决策树不同,我们的算法不仅通过引入树桩交换方法使基分类器之间能够进行部分信息交换,而且还使用修改后的基尼指数来评估树桩性能,从而通过全局视图评估每个节点的生成,以保持高泛化能力。此外,这些树被组合起来构建决策树桩集成(Ensemble of Decision Stump,EDST)。
我们从两种具有三种效果(相加、拮抗和协同)的细胞系中收集了两种药物组合数据集来测试我们的方法。实验结果表明,我们的 DST 和 EDST 都优于其他方法。此外,我们的方法生成的规则比其他基于规则的算法更简洁、更准确。最后,我们还分析了模型在生物信息学领域中提取的知识。
新的决策树集成模型可以有效地预测药物组合数据集的效果,并可以方便地获得决策过程。