Department of Computer Science, Virginia Polytechnic Institute and State University (Virginia Tech), Blacksburg, VA, 24061, USA.
The Jackson Laboratory for Genomic Medicine, Farmington, CT, 06032, USA.
EBioMedicine. 2023 Oct;96:104777. doi: 10.1016/j.ebiom.2023.104777. Epub 2023 Sep 4.
The cause and symptoms of long COVID are poorly understood. It is challenging to predict whether a given COVID-19 patient will develop long COVID in the future.
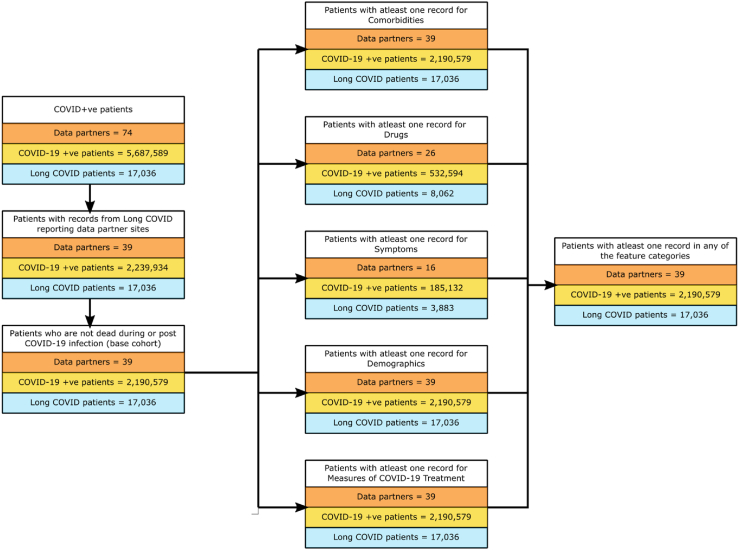
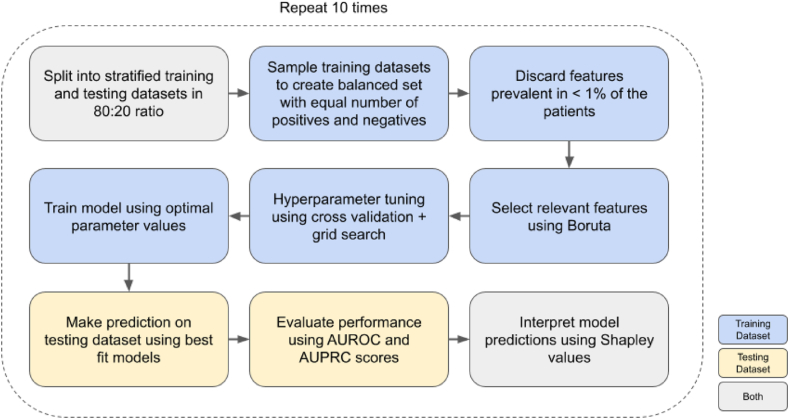
We used electronic health record (EHR) data from the National COVID Cohort Collaborative to predict the incidence of long COVID. We trained two machine learning (ML) models - logistic regression (LR) and random forest (RF). Features used to train predictors included symptoms and drugs ordered during acute infection, measures of COVID-19 treatment, pre-COVID comorbidities, and demographic information. We assigned the 'long COVID' label to patients diagnosed with the U09.9 ICD10-CM code. The cohorts included patients with (a) EHRs reported from data partners using U09.9 ICD10-CM code and (b) at least one EHR in each feature category. We analysed three cohorts: all patients (n = 2,190,579; diagnosed with long COVID = 17,036), inpatients (149,319; 3,295), and outpatients (2,041,260; 13,741).
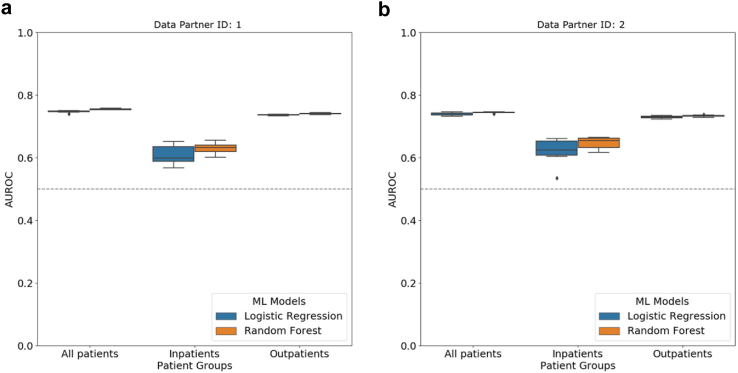
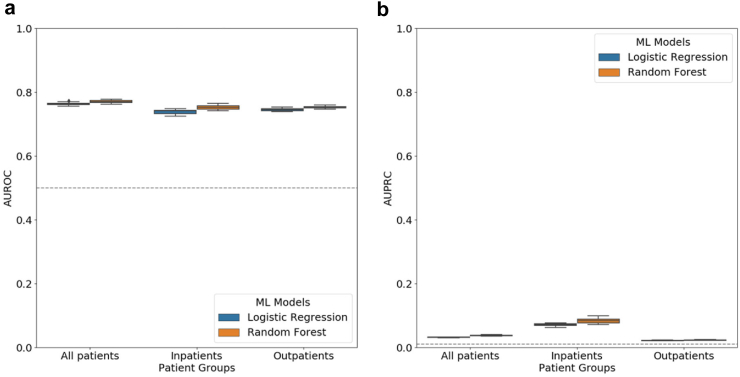
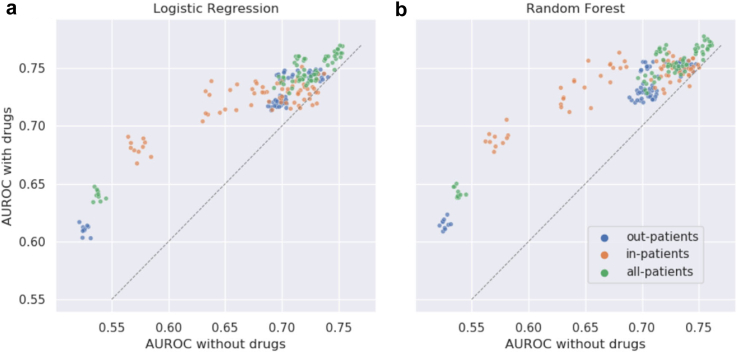
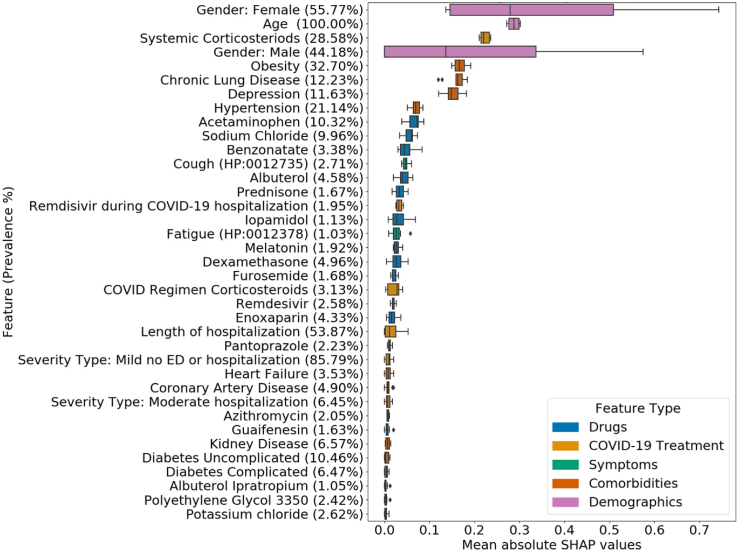
LR and RF models yielded median AUROC of 0.76 and 0.75, respectively. Ablation study revealed that drugs had the highest influence on the prediction task. The SHAP method identified age, gender, cough, fatigue, albuterol, obesity, diabetes, and chronic lung disease as explanatory features. Models trained on data from one N3C partner and tested on data from the other partners had average AUROC of 0.75.
ML-based classification using EHR information from the acute infection period is effective in predicting long COVID. SHAP methods identified important features for prediction. Cross-site analysis demonstrated the generalizability of the proposed methodology.
NCATS U24 TR002306, NCATS UL1 TR003015, Axle Informatics Subcontract: NCATS-P00438-B, NIH/NIDDK/OD, PSR2015-1720GVALE_01, G43C22001320007, and Director, Office of Science, Office of Basic Energy Sciences of the U.S. Department of Energy Contract No. DE-AC02-05CH11231.
长新冠的病因和症状尚不清楚。预测给定的 COVID-19 患者将来是否会发展成长新冠具有挑战性。
我们使用来自国家 COVID 队列协作的电子健康记录 (EHR) 数据来预测长新冠的发病率。我们训练了两个机器学习 (ML) 模型 - 逻辑回归 (LR) 和随机森林 (RF)。用于训练预测器的特征包括急性感染期间的症状和开的药物、COVID-19 治疗措施、预 COVID 合并症和人口统计信息。我们将 U09.9 ICD10-CM 代码诊断的患者分配给“长新冠”标签。队列包括 (a) 使用 U09.9 ICD10-CM 代码报告来自数据合作伙伴的 EHRs 的患者,以及 (b) 每个特征类别中至少有一个 EHR 的患者。我们分析了三个队列:所有患者 (n=2,190,579; 诊断为长新冠 = 17,036)、住院患者 (149,319; 3,295) 和门诊患者 (2,041,260; 13,741)。
LR 和 RF 模型的中位数 AUROC 分别为 0.76 和 0.75。消融研究表明,药物对预测任务的影响最大。SHAP 方法确定了年龄、性别、咳嗽、疲劳、沙丁胺醇、肥胖、糖尿病和慢性肺病作为解释性特征。在一个 N3C 合作伙伴的数据上训练的模型并在另一个合作伙伴的数据上进行测试的模型的平均 AUROC 为 0.75。
使用急性感染期的 EHR 信息进行基于机器学习的分类在预测长新冠方面是有效的。SHAP 方法确定了预测的重要特征。跨站点分析证明了所提出方法的通用性。
NCATS U24 TR002306、NCATS UL1 TR003015、Axle Informatics 分包合同:NCATS-P00438-B、NIH/NIDDK/OD、PSR2015-1720GVALE_01、G43C22001320007 和能源部基础能源科学办公室主任,合同号 DE-AC02-05CH11231。