Centre for Evolution and Cancer, The Institute of Cancer Research, London, UK; Division of Molecular Pathology, The Institute of Cancer Research, London, UK.
Department of Oncology, UCL Cancer Institute, University College London, London, UK.
EBioMedicine. 2023 Sep;95:104769. doi: 10.1016/j.ebiom.2023.104769. Epub 2023 Sep 4.
Efficient biomarker discovery and clinical translation depend on the fast and accurate analytical output from crucial technologies such as multiplex imaging. However, reliable cell classification often requires extensive annotations. Label-efficient strategies are urgently needed to reveal diverse cell distribution and spatial interactions in large-scale multiplex datasets.
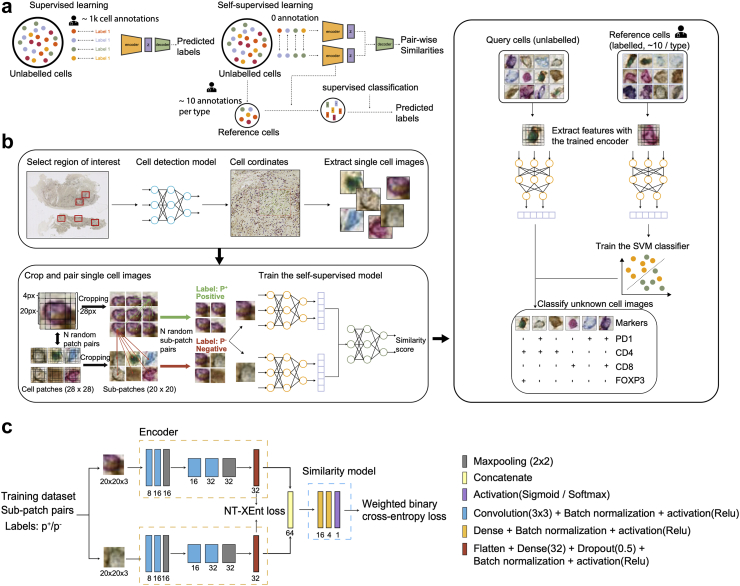
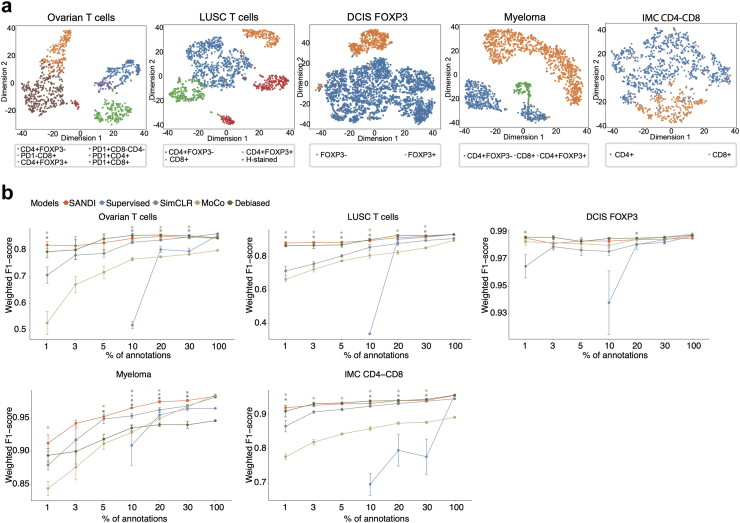
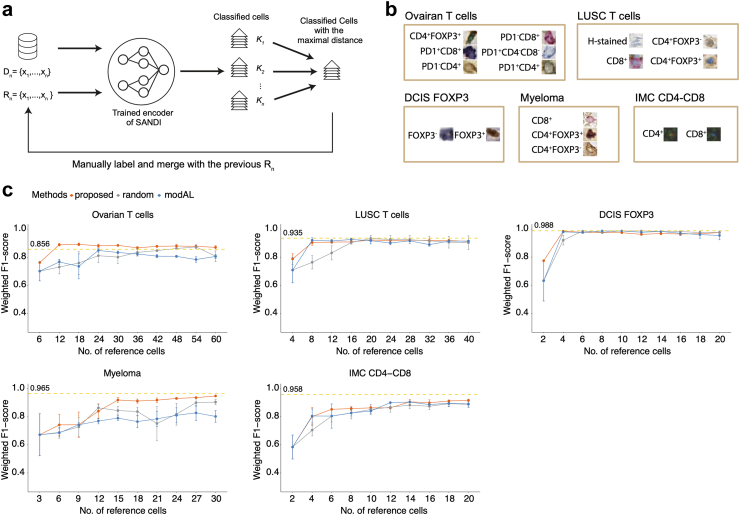
This study proposed Self-supervised Learning for Antigen Detection (SANDI) for accurate cell phenotyping while mitigating the annotation burden. The model first learns intrinsic pairwise similarities in unlabelled cell images, followed by a classification step to map learnt features to cell labels using a small set of annotated references. We acquired four multiplex immunohistochemistry datasets and one imaging mass cytometry dataset, comprising 2825 to 15,258 single-cell images to train and test the model.
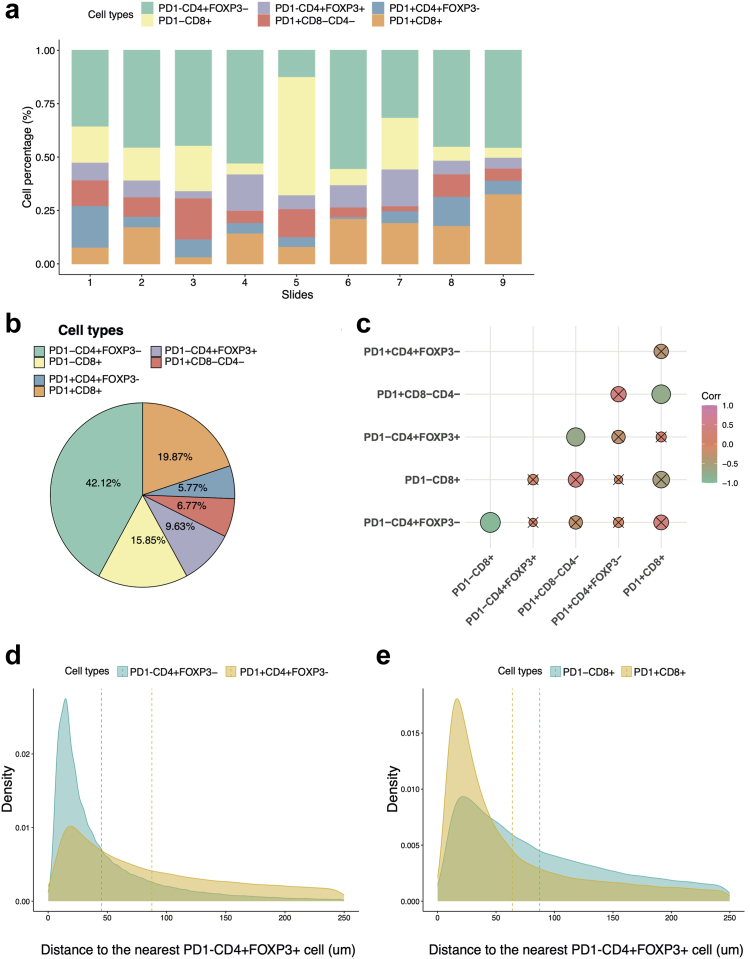
With 1% annotations (18-114 cells), SANDI achieved weighted F1-scores ranging from 0.82 to 0.98 across the five datasets, which was comparable to the fully supervised classifier trained on 1828-11,459 annotated cells (-0.002 to -0.053 of averaged weighted F1-score, Wilcoxon rank-sum test, P = 0.31). Leveraging the immune checkpoint markers stained in ovarian cancer slides, SANDI-based cell identification reveals spatial expulsion between PD1-expressing T helper cells and T regulatory cells, suggesting an interplay between PD1 expression and T regulatory cell-mediated immunosuppression.
By striking a fine balance between minimal expert guidance and the power of deep learning to learn similarity within abundant data, SANDI presents new opportunities for efficient, large-scale learning for histology multiplex imaging data.
This study was funded by the Royal Marsden/ICR National Institute of Health Research Biomedical Research Centre.
高效的生物标志物发现和临床转化依赖于多重成像等关键技术的快速、准确的分析输出。然而,可靠的细胞分类通常需要广泛的注释。迫切需要标签高效策略来揭示大规模多重数据集的多样化细胞分布和空间相互作用。
本研究提出了用于抗原检测的自监督学习(SANDI),以在减轻注释负担的同时实现准确的细胞表型分析。该模型首先学习未标记细胞图像中的内在成对相似性,然后通过分类步骤使用一小部分标记的参考将学习到的特征映射到细胞标签。我们获取了四个多重免疫组织化学数据集和一个成像质谱细胞数据集,包含 2825 到 15258 个单细胞图像来训练和测试模型。
使用 1%的注释(18-114 个细胞),SANDI 在五个数据集上实现了加权 F1 分数从 0.82 到 0.98 的范围,与在 1828-11459 个注释细胞上训练的完全监督分类器相当(平均加权 F1 分数的-0.002 到-0.053,Wilcoxon 秩和检验,P=0.31)。利用卵巢癌切片中染色的免疫检查点标记物,基于 SANDI 的细胞识别揭示了 PD1 表达的辅助性 T 细胞和 T 调节细胞之间的空间驱逐,表明 PD1 表达与 T 调节细胞介导的免疫抑制之间存在相互作用。
通过在最少的专家指导和深度学习在丰富数据中学习相似性的能力之间取得良好平衡,SANDI 为组织学多重成像数据的高效、大规模学习提供了新的机会。
本研究由皇家马斯登/ICR 国家卫生研究院生物医学研究中心资助。