Mosaiques Diagnostics GmbH, Hannover, Germany.
Institute for Molecular Cardiovascular Research (IMCAR), RWTH Aachen University Hospital, Aachen, Germany.
Nephrol Dial Transplant. 2024 Feb 28;39(3):453-462. doi: 10.1093/ndt/gfad200.
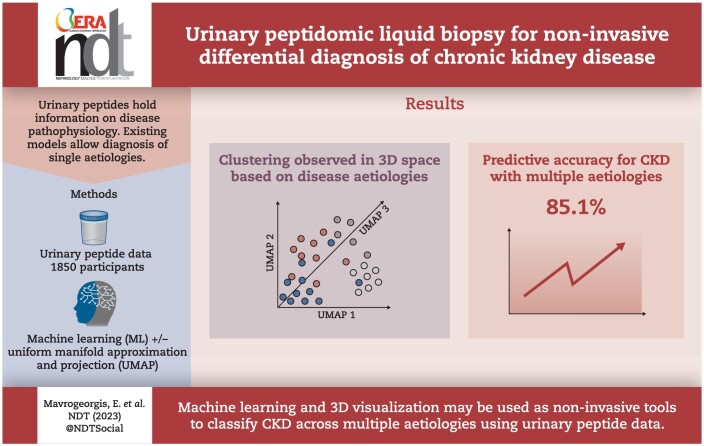
Specific urinary peptides hold information on disease pathophysiology, which, in combination with artificial intelligence, could enable non-invasive assessment of chronic kidney disease (CKD) aetiology. Existing approaches are generally specific for the diagnosis of single aetiologies. We present the development of models able to simultaneously distinguish and spatially visualize multiple CKD aetiologies.
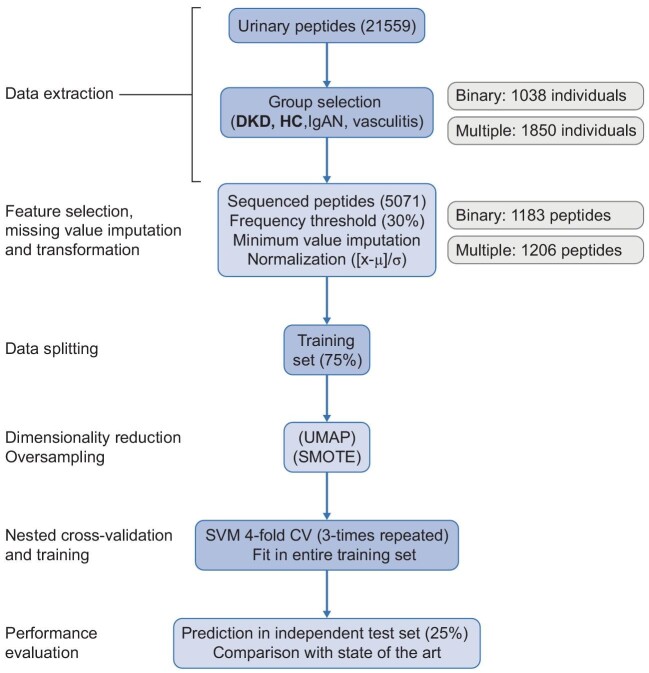
The urinary peptide data of 1850 healthy control (HC) and CKD [diabetic kidney disease (DKD), immunoglobulin A nephropathy (IgAN) and vasculitis] participants were extracted from the Human Urinary Proteome Database. Uniform manifold approximation and projection (UMAP) coupled to a support vector machine algorithm was used to generate multi-peptide models to perform binary (DKD, HC) and multiclass (DKD, HC, IgAN, vasculitis) classifications. This pipeline was compared with the current state-of-the-art single-aetiology CKD urinary peptide models.
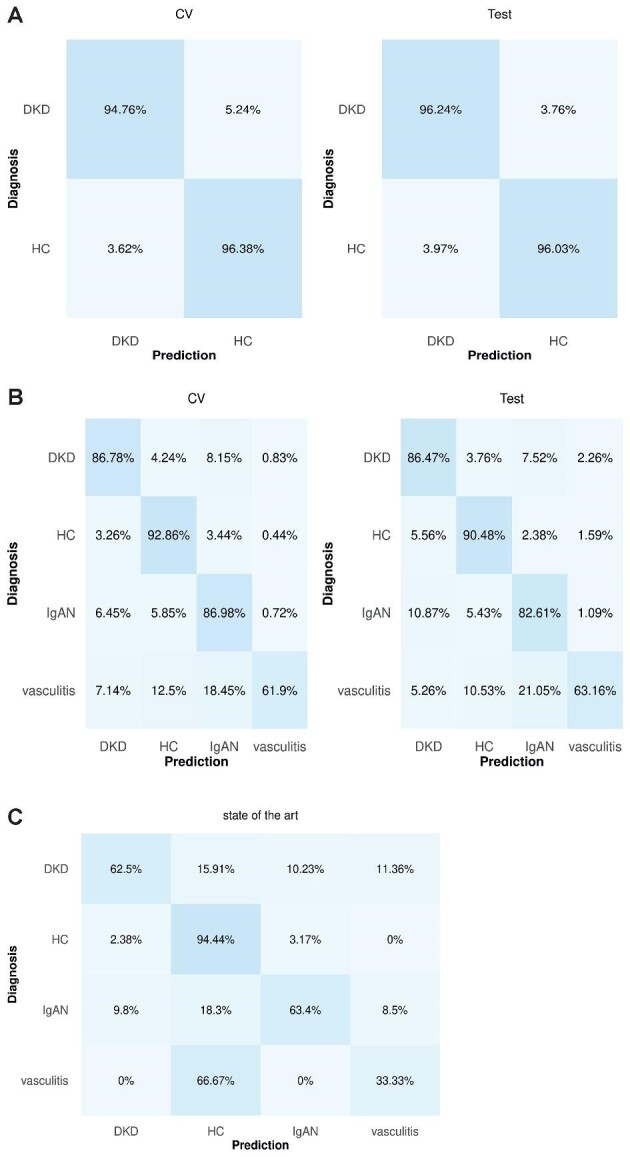
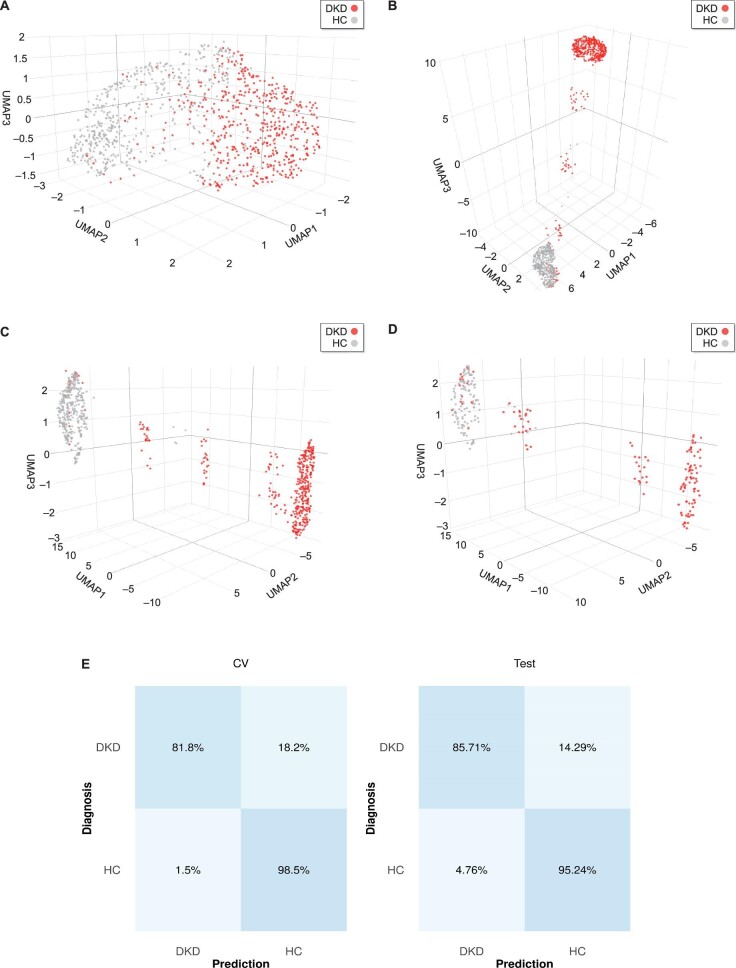
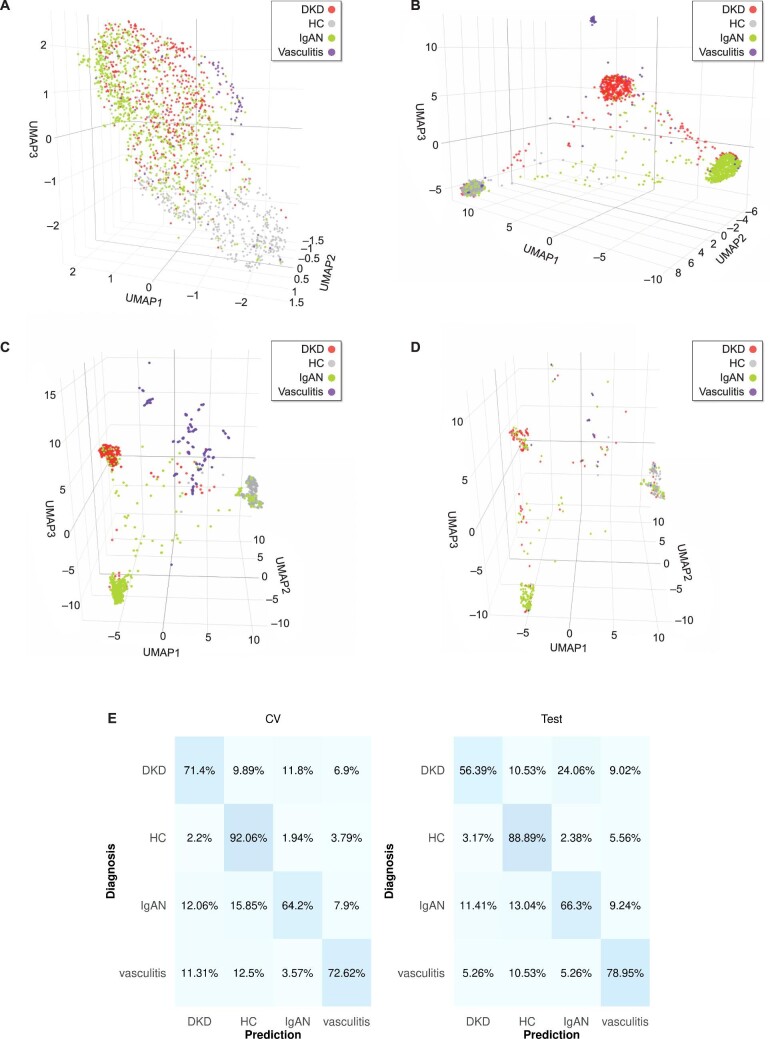
In an independent test set, the developed models achieved 90.35% and 70.13% overall predictive accuracies, respectively, for the binary and the multiclass classifications. Omitting the UMAP step led to improved predictive accuracies (96.14% and 85.06%, respectively). As expected, the HC class was distinguished with the highest accuracy. The different classes displayed a tendency to form distinct clusters in the 3D space based on their disease state.
Urinary peptide data present an effective basis for CKD aetiology differentiation using machine learning models. Although adding the UMAP step to the models did not improve prediction accuracy, it may provide a unique visualization advantage. Additional studies are warranted to further validate the pipeline's clinical potential as well as to expand it to other CKD aetiologies and also other diseases.
特定的尿肽携带有关疾病病理生理学的信息,结合人工智能,可以实现对慢性肾脏病(CKD)病因的非侵入性评估。现有的方法通常是针对单一病因的诊断特异性。我们提出了开发能够同时区分和空间可视化多种 CKD 病因的模型的方法。
从 Human Urinary Proteome Database 中提取了 1850 名健康对照(HC)和 CKD[糖尿病肾病(DKD)、免疫球蛋白 A 肾病(IgAN)和血管炎]参与者的尿肽数据。采用一致流形逼近和投影(UMAP)结合支持向量机算法生成多肽模型,以进行二分类(DKD,HC)和多分类(DKD,HC,IgAN,血管炎)分类。将该流水线与当前最先进的单一病因 CKD 尿肽模型进行了比较。
在独立测试集中,开发的模型分别实现了 90.35%和 70.13%的总体预测准确率,用于二分类和多分类。省略 UMAP 步骤可提高预测准确率(分别为 96.14%和 85.06%)。如预期的那样,HC 类的区分准确率最高。不同的类别根据其疾病状态在 3D 空间中呈现出形成不同簇的趋势。
使用机器学习模型,尿肽数据为 CKD 病因的区分提供了有效的基础。虽然在模型中添加 UMAP 步骤并未提高预测准确性,但它可能提供独特的可视化优势。需要进一步的研究来进一步验证该流水线的临床潜力,并将其扩展到其他 CKD 病因以及其他疾病。