Shi Danli, He Shuang, Yang Jiancheng, Zheng Yingfeng, He Mingguang
Centre for Eye and Vision Research (CEVR), Hong Kong SAR, China.
The Hong Kong Polytechnic University, Kowloon, Hong Kong SAR, China.
Ophthalmol Sci. 2023 Jul 6;4(2):100363. doi: 10.1016/j.xops.2023.100363. eCollection 2024 Mar-Apr.
To perform one-shot retinal artery and vein segmentation with cross-modality artery-vein (AV) soft-label pretraining.
Cross-sectional study.
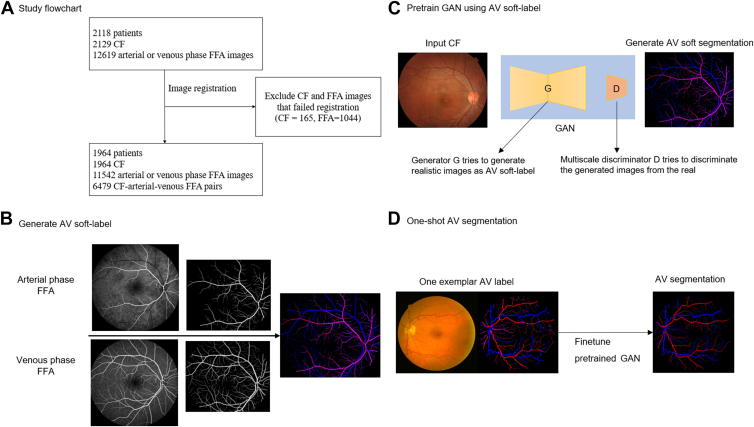
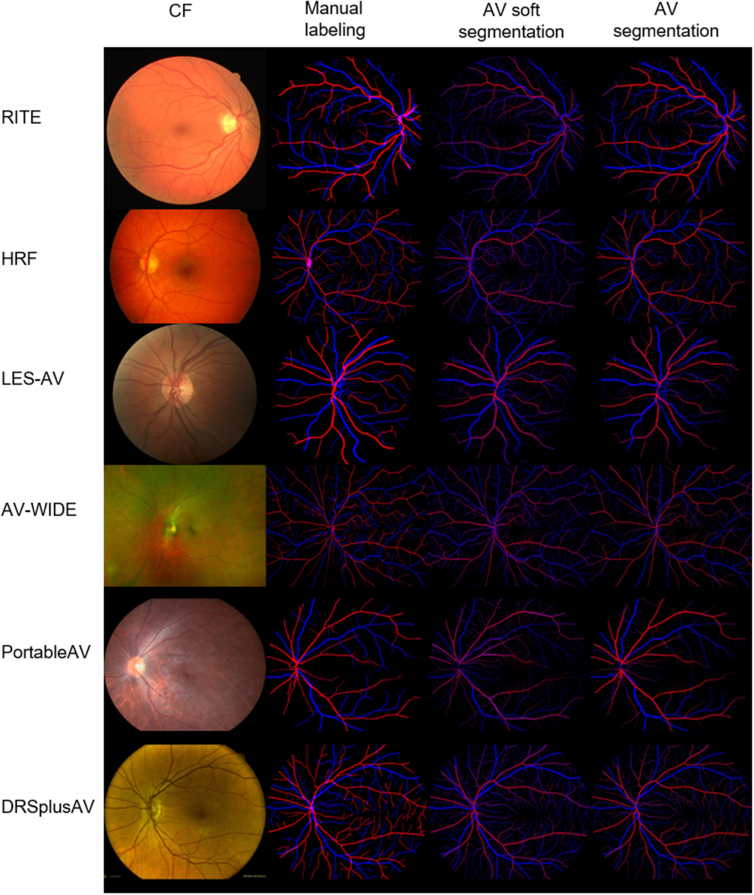
The study included 6479 color fundus photography (CFP) and arterial-venous fundus fluorescein angiography (FFA) pairs from 1964 participants for pretraining and 6 AV segmentation data sets with various image sources, including RITE, HRF, LES-AV, AV-WIDE, PortableAV, and DRSplusAV for one-shot finetuning and testing.
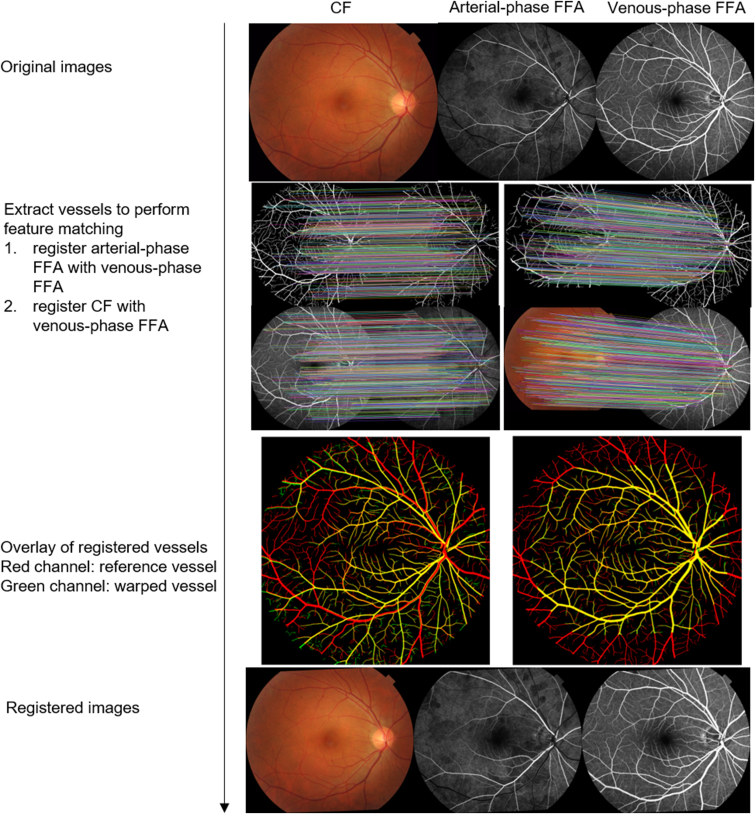
We structurally matched the arterial and venous phase of FFA with CFP, the AV soft labels were automatically generated by utilizing the fluorescein intensity difference of the arterial and venous-phase FFA images, and the soft labels were then used to train a generative adversarial network to learn to generate AV soft segmentations using CFP images as input. We then finetuned the pretrained model to perform AV segmentation using only one image from each of the AV segmentation data sets and test on the remainder. To investigate the effect and reliability of one-shot finetuning, we conducted experiments without finetuning and by finetuning the pretrained model on an iteratively different single image for each data set under the same experimental setting and tested the models on the remaining images.
The AV segmentation was assessed by area under the receiver operating characteristic curve (AUC), accuracy, Dice score, sensitivity, and specificity.
After the FFA-AV soft label pretraining, our method required only one exemplar image from each camera or modality and achieved similar performance with full-data training, with AUC ranging from 0.901 to 0.971, accuracy from 0.959 to 0.980, Dice score from 0.585 to 0.773, sensitivity from 0.574 to 0.763, and specificity from 0.981 to 0.991. Compared with no finetuning, the segmentation performance improved after one-shot finetuning. When finetuned on different images in each data set, the standard deviation of the segmentation results across models ranged from 0.001 to 0.10.
This study presents the first one-shot approach to retinal artery and vein segmentation. The proposed labeling method is time-saving and efficient, demonstrating a promising direction for retinal-vessel segmentation and enabling the potential for widespread application.
Proprietary or commercial disclosure may be found in the Footnotes and Disclosures at the end of this article.
通过跨模态动静脉(AV)软标签预训练进行一次性视网膜动静脉分割。
横断面研究。
该研究纳入了来自1964名参与者的6479对彩色眼底照片(CFP)和动静脉眼底荧光血管造影(FFA)用于预训练,以及6个具有不同图像来源的AV分割数据集,包括RITE、HRF、LES-AV、AV-WIDE、PortableAV和DRSplusAV用于一次性微调及测试。
我们在结构上使FFA的动静脉期与CFP匹配,利用动静脉期FFA图像的荧光素强度差异自动生成AV软标签,然后使用这些软标签训练一个生成对抗网络,以学习使用CFP图像作为输入来生成AV软分割。然后,我们对预训练模型进行微调,以便仅使用每个AV分割数据集中的一张图像来执行AV分割,并在其余图像上进行测试。为了研究一次性微调的效果和可靠性,我们在相同实验设置下,进行了不微调以及在每个数据集的迭代不同单张图像上对预训练模型进行微调的实验,并在其余图像上测试模型。
通过受试者操作特征曲线下面积(AUC)、准确率、Dice系数、灵敏度和特异性来评估AV分割。
经过FFA-AV软标签预训练后,我们的方法每个相机或模态仅需一张示例图像,且在全数据训练下取得了相似的性能,AUC范围为0.901至0.971,准确率为0.959至0.980,Dice系数为0.585至0.773,灵敏度为0.574至0.763,特异性为0.981至0.991。与不微调相比,一次性微调后分割性能有所提高。当在每个数据集中的不同图像上进行微调时,各模型分割结果的标准差范围为0.001至0.10。
本研究提出了首个用于视网膜动静脉分割的一次性方法。所提出的标记方法省时高效为视网膜血管分割展示了一个有前景的方向,并具有广泛应用的潜力。
在本文末尾的脚注和披露中可能会找到专有或商业披露信息。