Department of Psychology, University of California, Berkeley, Berkeley, United States.
Department of Psychology, New York University, New York, United States.
Elife. 2022 Nov 4;11:e75474. doi: 10.7554/eLife.75474.
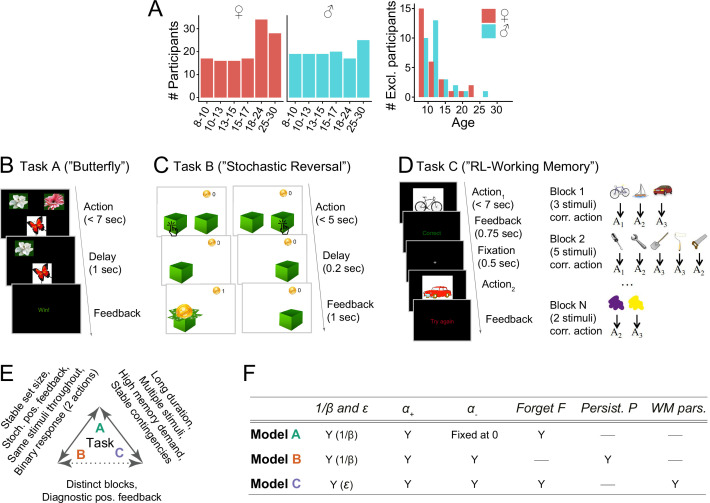
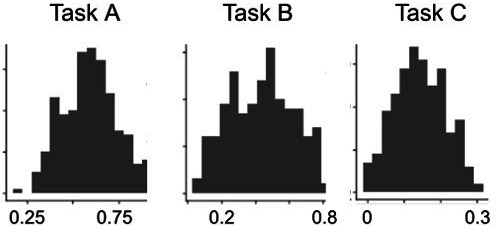
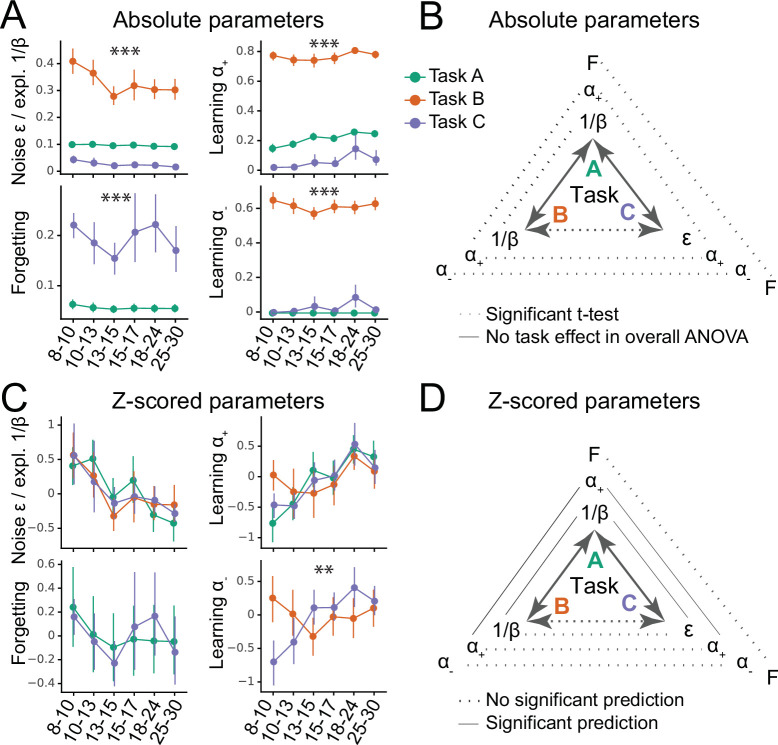
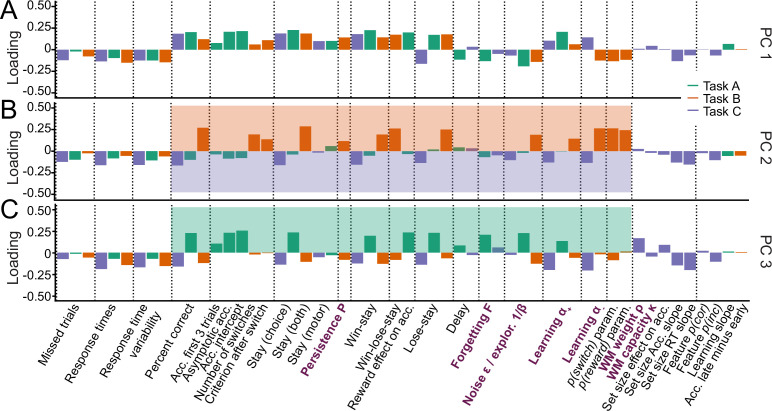
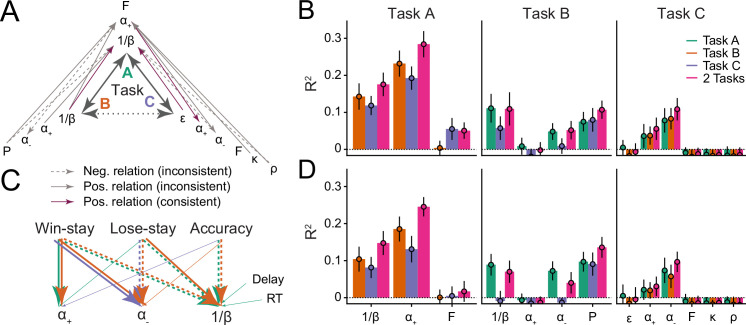
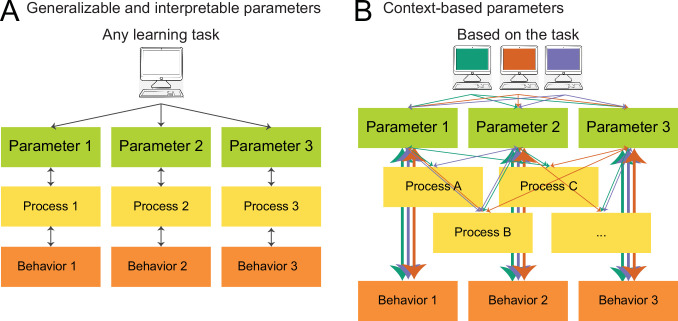
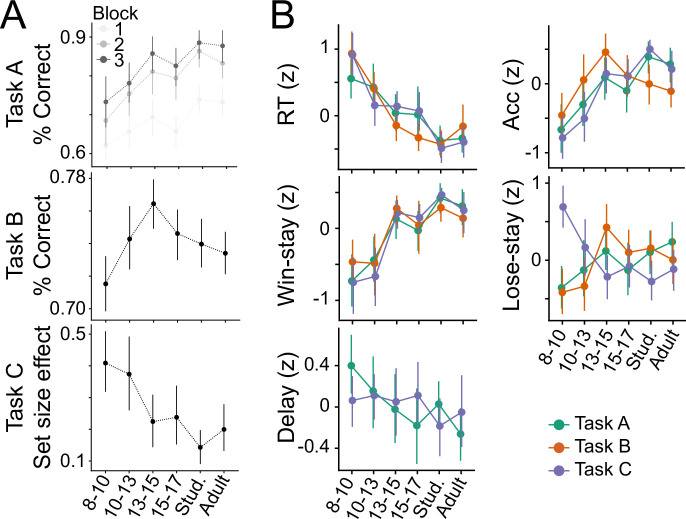
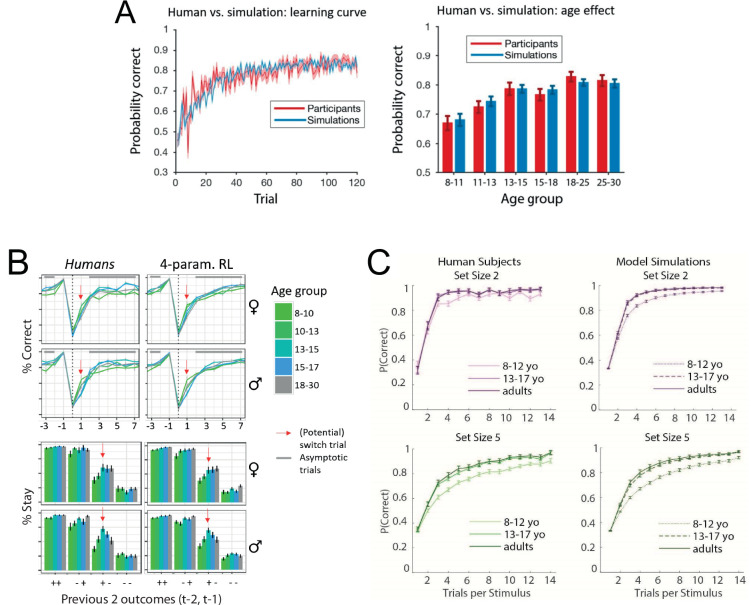
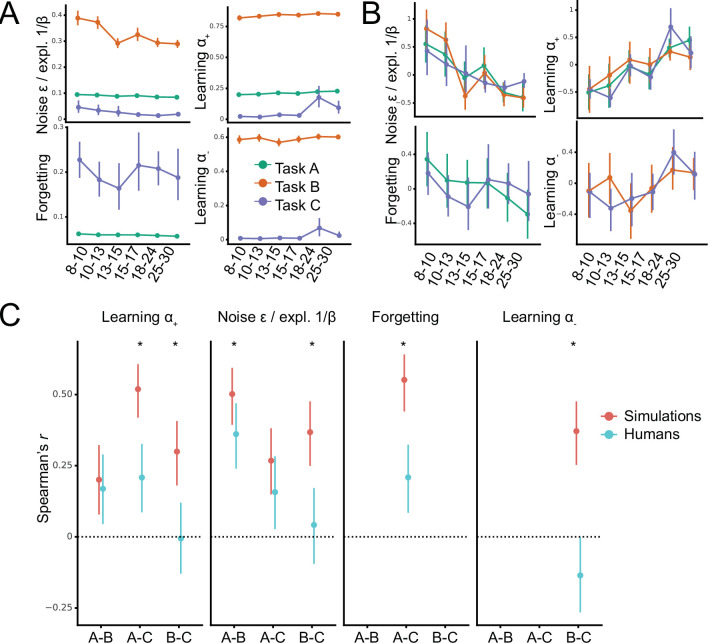
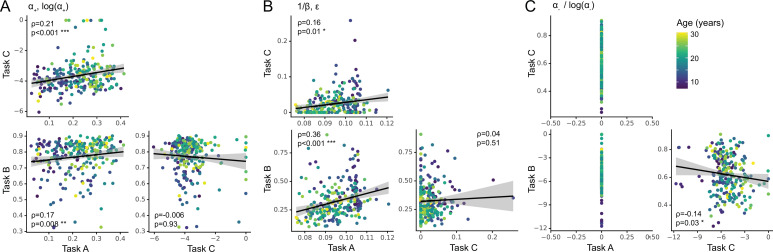
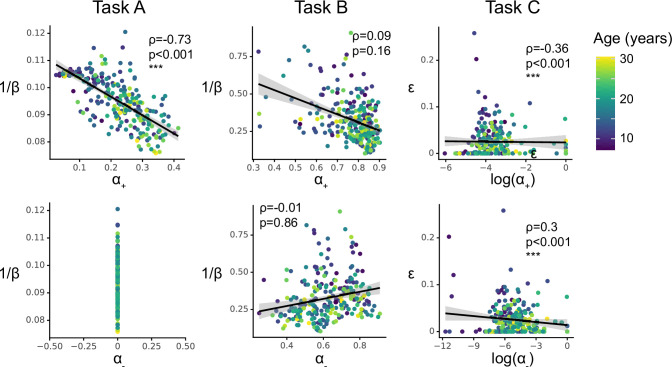
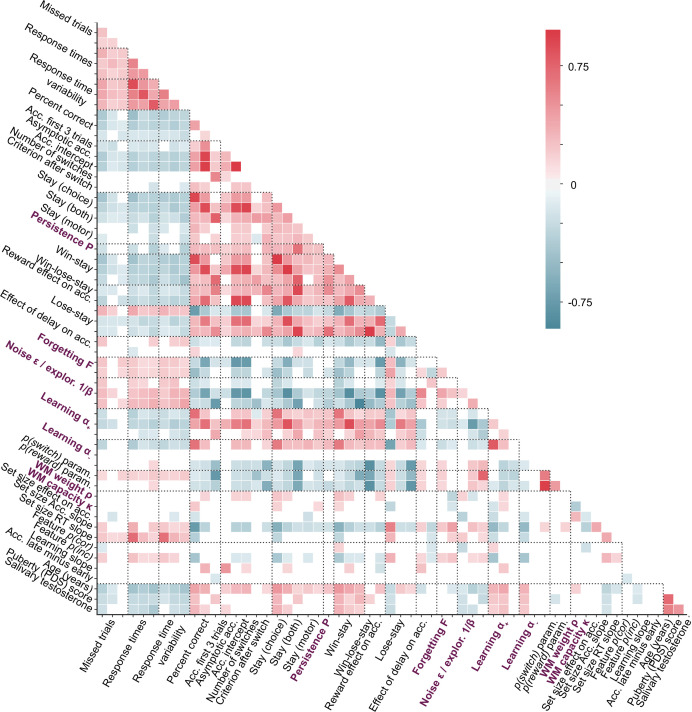
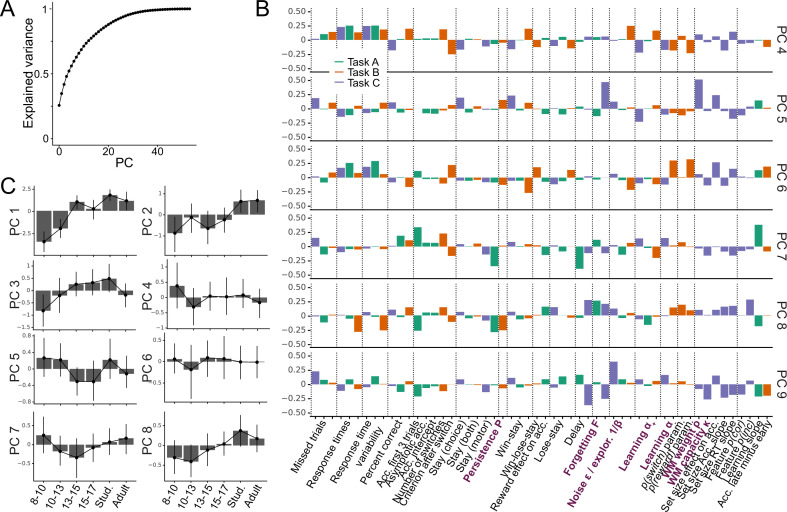
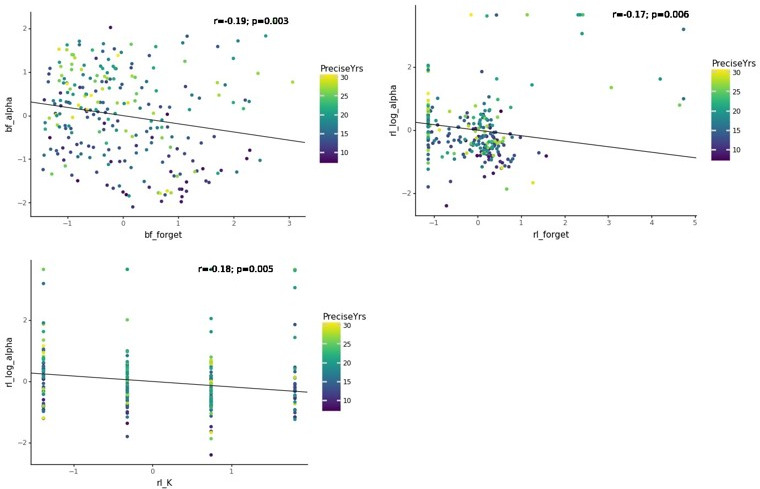
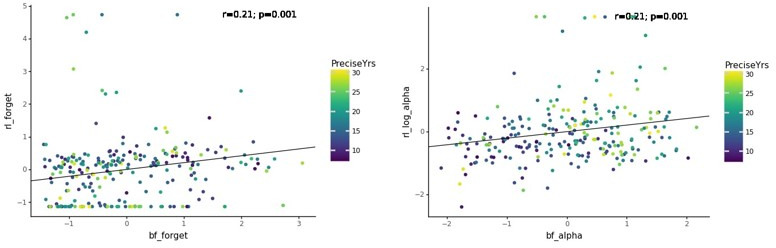
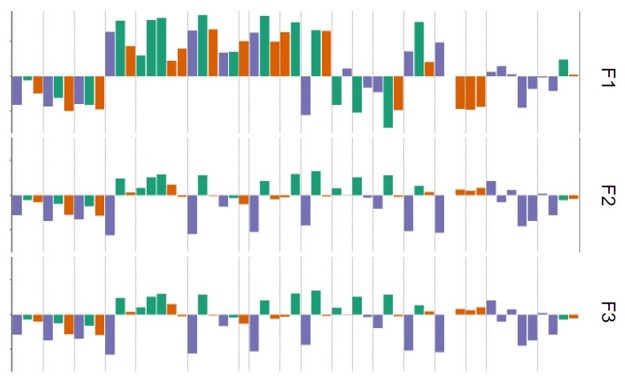
Reinforcement Learning (RL) models have revolutionized the cognitive and brain sciences, promising to explain behavior from simple conditioning to complex problem solving, to shed light on developmental and individual differences, and to anchor cognitive processes in specific brain mechanisms. However, the RL literature increasingly reveals contradictory results, which might cast doubt on these claims. We hypothesized that many contradictions arise from two commonly-held assumptions about computational model parameters that are actually often invalid: That parameters between contexts (e.g. tasks, models) and that they capture (i.e. unique, distinctive) neurocognitive processes. To test this, we asked 291 participants aged 8-30 years to complete three learning tasks in one experimental session, and fitted RL models to each. We found that some parameters (exploration / decision noise) showed significant generalization: they followed similar developmental trajectories, and were reciprocally predictive between tasks. Still, generalization was significantly below the methodological ceiling. Furthermore, other parameters (learning rates, forgetting) did not show evidence of generalization, and sometimes even opposite developmental trajectories. Interpretability was low for all parameters. We conclude that the systematic study of context factors (e.g. reward stochasticity; task volatility) will be necessary to enhance the generalizability and interpretability of computational cognitive models.
强化学习(RL)模型彻底改变了认知和脑科学领域,有望从简单的条件作用到复杂的问题解决,从发展和个体差异,到将认知过程锚定在特定的大脑机制,来解释行为。然而,RL 文献越来越多地揭示出相互矛盾的结果,这可能使这些主张受到质疑。我们假设,许多矛盾源于对计算模型参数的两个常见假设,而这些假设实际上往往是无效的:参数在不同情境(例如任务、模型)之间是不变的,并且它们捕捉到独特的神经认知过程。为了验证这一点,我们要求 291 名年龄在 8 至 30 岁之间的参与者在一次实验中完成三个学习任务,并为每个任务拟合 RL 模型。我们发现,一些参数(探索/决策噪声)表现出显著的泛化:它们遵循相似的发展轨迹,并且在任务之间具有相互预测性。尽管如此,泛化程度仍明显低于方法学上限。此外,其他参数(学习率、遗忘)没有表现出泛化的迹象,有时甚至呈现相反的发展轨迹。所有参数的可解释性都很低。我们的结论是,系统地研究上下文因素(例如奖励随机性;任务波动性)将是增强计算认知模型的可泛化性和可解释性所必需的。