Alsentzer Emily, Rasmussen Matthew J, Fontoura Romy, Cull Alexis L, Beaulieu-Jones Brett, Gray Kathryn J, Bates David W, Kovacheva Vesela P
Division of General Internal Medicine and Primary Care, Brigham and Women's Hospital, Boston, MA, USA.
Department of Anesthesiology, Perioperative and Pain Medicine, Brigham and Women's Hospital, Boston, MA, USA.
NPJ Digit Med. 2023 Nov 30;6(1):212. doi: 10.1038/s41746-023-00957-x.
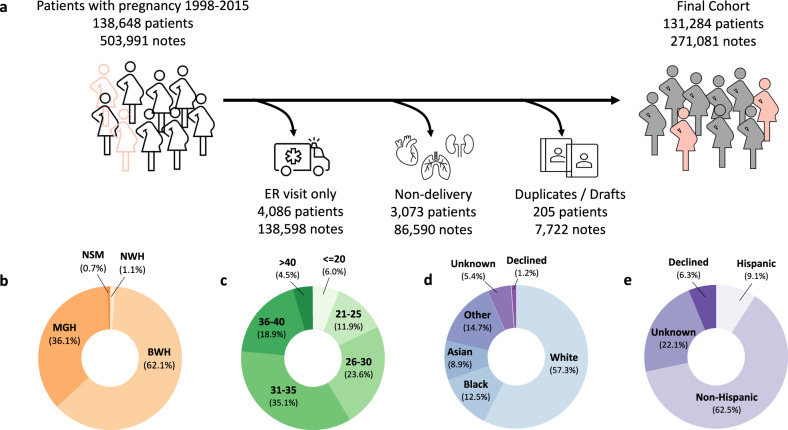
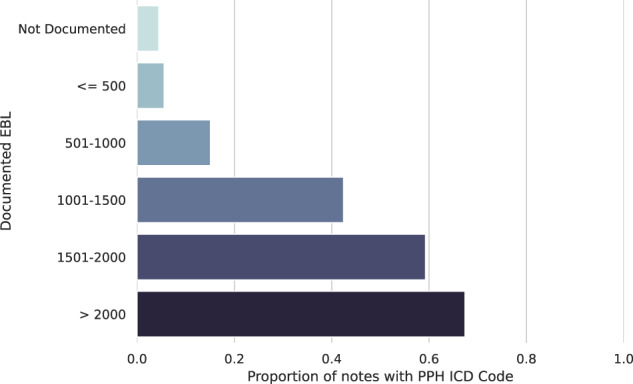
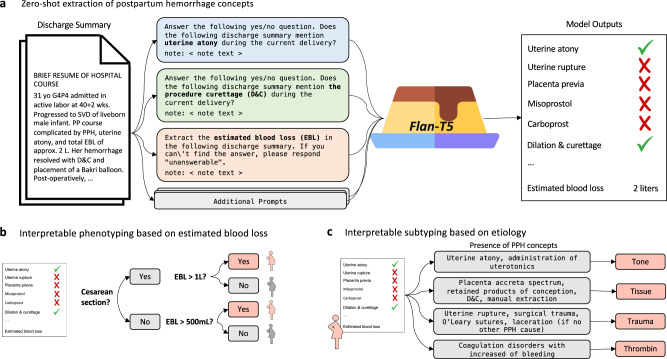
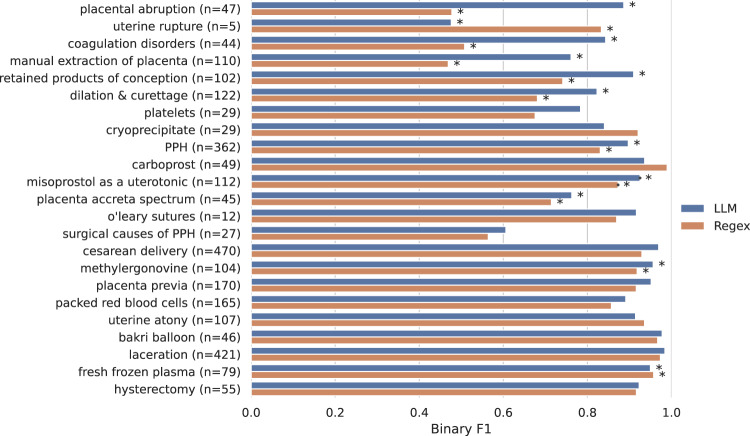
Many areas of medicine would benefit from deeper, more accurate phenotyping, but there are limited approaches for phenotyping using clinical notes without substantial annotated data. Large language models (LLMs) have demonstrated immense potential to adapt to novel tasks with no additional training by specifying task-specific instructions. Here we report the performance of a publicly available LLM, Flan-T5, in phenotyping patients with postpartum hemorrhage (PPH) using discharge notes from electronic health records (n = 271,081). The language model achieves strong performance in extracting 24 granular concepts associated with PPH. Identifying these granular concepts accurately allows the development of interpretable, complex phenotypes and subtypes. The Flan-T5 model achieves high fidelity in phenotyping PPH (positive predictive value of 0.95), identifying 47% more patients with this complication compared to the current standard of using claims codes. This LLM pipeline can be used reliably for subtyping PPH and outperforms a claims-based approach on the three most common PPH subtypes associated with uterine atony, abnormal placentation, and obstetric trauma. The advantage of this approach to subtyping is its interpretability, as each concept contributing to the subtype determination can be evaluated. Moreover, as definitions may change over time due to new guidelines, using granular concepts to create complex phenotypes enables prompt and efficient updating of the algorithm. Using this language modelling approach enables rapid phenotyping without the need for any manually annotated training data across multiple clinical use cases.
医学的许多领域都将受益于更深入、更准确的表型分析,但在没有大量注释数据的情况下,使用临床记录进行表型分析的方法有限。大语言模型(LLMs)已显示出通过指定特定任务的指令,在无需额外训练的情况下适应新任务的巨大潜力。在此,我们报告了一个公开可用的大语言模型Flan-T5,在使用电子健康记录中的出院记录(n = 271,081)对产后出血(PPH)患者进行表型分析方面的表现。该语言模型在提取与PPH相关的24个精细概念方面表现出色。准确识别这些精细概念有助于开发可解释的复杂表型和亚型。Flan-T5模型在PPH表型分析中实现了高保真度(阳性预测值为0.95),与使用理赔代码的当前标准相比,识别出的该并发症患者多47%。这种大语言模型流程可可靠地用于PPH亚型分析,并且在与子宫收缩乏力、胎盘异常和产科创伤相关的三种最常见PPH亚型上优于基于理赔的方法。这种亚型分析方法的优势在于其可解释性,因为每个有助于亚型确定的概念都可以进行评估。此外由于新指南的原因,定义可能会随时间变化,使用精细概念创建复杂表型能够迅速有效地更新算法。使用这种语言建模方法能够在多个临床用例中无需任何人工注释的训练数据即可快速进行表型分析。