Molecular and Digital Breeding, New Cultivar Innovation, The New Zealand Institute for Plant and Food Research Limited, 120 Mt Albert Road, Auckland 1025, New Zealand.
Department of Botany and Plant Pathology, Oregon State University, Corvallis, OR 97331, USA.
Database (Oxford). 2023 Dec 11;2023. doi: 10.1093/database/baad088.
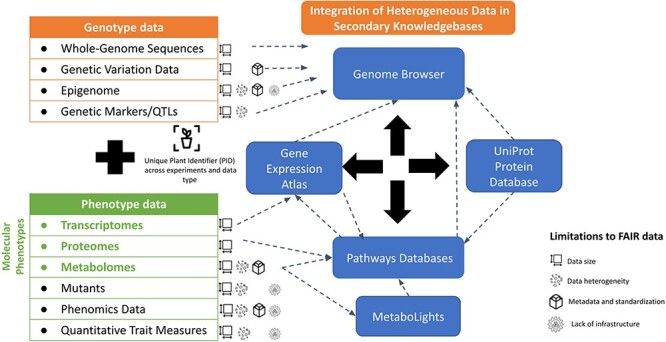
Large-scale genotype and phenotype data have been increasingly generated to identify genetic markers, understand gene function and evolution and facilitate genomic selection. These datasets hold immense value for both current and future studies, as they are vital for crop breeding, yield improvement and overall agricultural sustainability. However, integrating these datasets from heterogeneous sources presents significant challenges and hinders their effective utilization. We established the Genotype-Phenotype Working Group in November 2021 as a part of the AgBioData Consortium (https://www.agbiodata.org) to review current data types and resources that support archiving, analysis and visualization of genotype and phenotype data to understand the needs and challenges of the plant genomic research community. For 2021-22, we identified different types of datasets and examined metadata annotations related to experimental design/methods/sample collection, etc. Furthermore, we thoroughly reviewed publicly funded repositories for raw and processed data as well as secondary databases and knowledgebases that enable the integration of heterogeneous data in the context of the genome browser, pathway networks and tissue-specific gene expression. Based on our survey, we recommend a need for (i) additional infrastructural support for archiving many new data types, (ii) development of community standards for data annotation and formatting, (iii) resources for biocuration and (iv) analysis and visualization tools to connect genotype data with phenotype data to enhance knowledge synthesis and to foster translational research. Although this paper only covers the data and resources relevant to the plant research community, we expect that similar issues and needs are shared by researchers working on animals. Database URL: https://www.agbiodata.org.
大规模的基因型和表型数据不断生成,以鉴定遗传标记、了解基因功能和进化,并促进基因组选择。这些数据集对于当前和未来的研究都具有巨大的价值,因为它们对于作物育种、产量提高和整体农业可持续性至关重要。然而,整合来自异构源的这些数据集面临着重大挑战,阻碍了它们的有效利用。我们于 2021 年 11 月成立了基因型-表型工作组,作为 AgBioData 联盟(https://www.agbiodata.org)的一部分,以审查当前支持基因型和表型数据存档、分析和可视化的数据类型和资源,以了解植物基因组研究界的需求和挑战。在 2021-22 年期间,我们确定了不同类型的数据集,并检查了与实验设计/方法/样本收集等相关的元数据注释。此外,我们还彻底审查了公共资助的原始和处理后数据存储库,以及二级数据库和知识库,这些资源使在基因组浏览器、途径网络和组织特异性基因表达的背景下整合异构数据成为可能。基于我们的调查,我们建议需要(i)为归档许多新数据类型提供额外的基础设施支持,(ii)制定数据注释和格式化的社区标准,(iii)生物信息资源,以及(iv)分析和可视化工具,以将基因型数据与表型数据连接起来,增强知识综合,并促进转化研究。尽管本文仅涵盖与植物研究界相关的数据和资源,但我们预计,从事动物研究的研究人员也存在类似的问题和需求。数据库 URL:https://www.agbiodata.org。