State Key Laboratory of Medical Proteomics, Beijing Proteome Research Center, National Center for Protein Sciences (Beijing), Beijing Institute of Lifeomics, Beijing 102206, China.
School of Traditional Chinese Medicine, Beijing University of Chinese Medicine, Beijing 100029, China.
Brief Bioinform. 2024 Jan 22;25(2). doi: 10.1093/bib/bbae111.
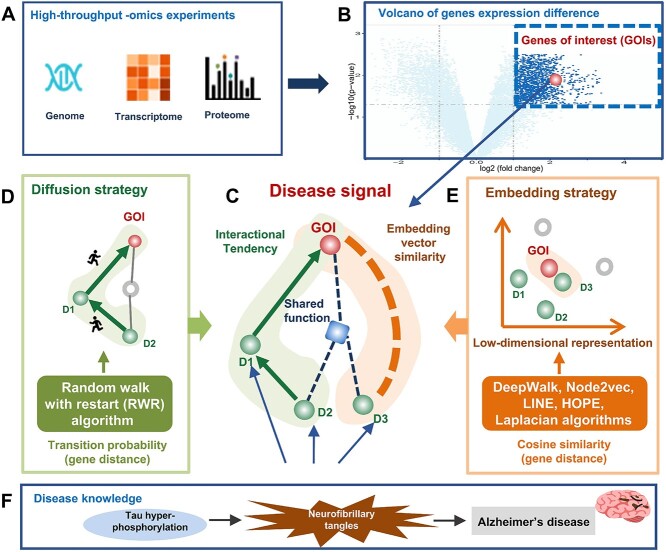
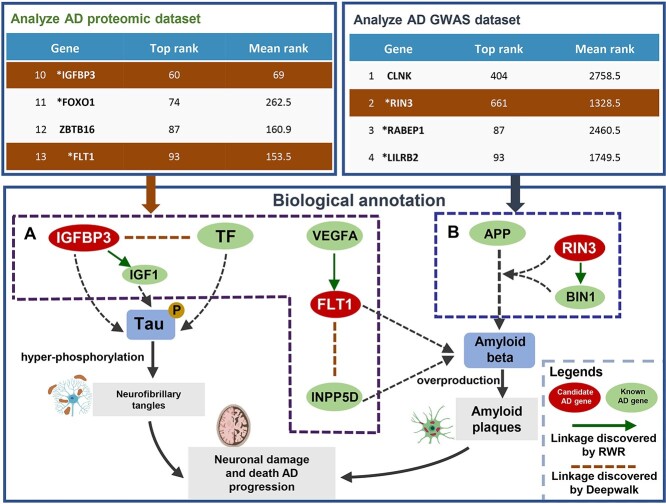
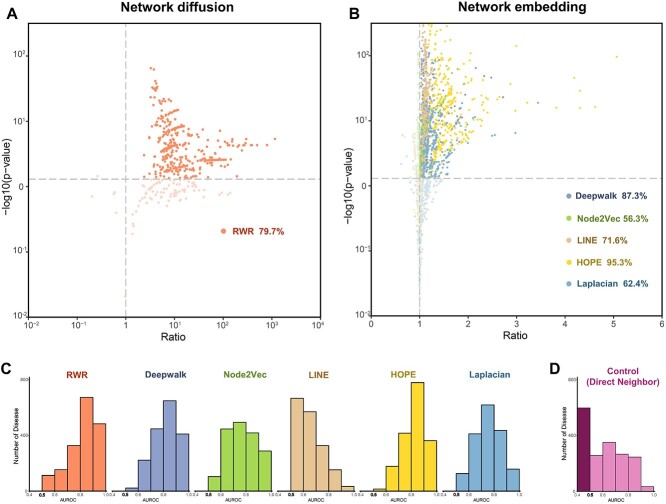
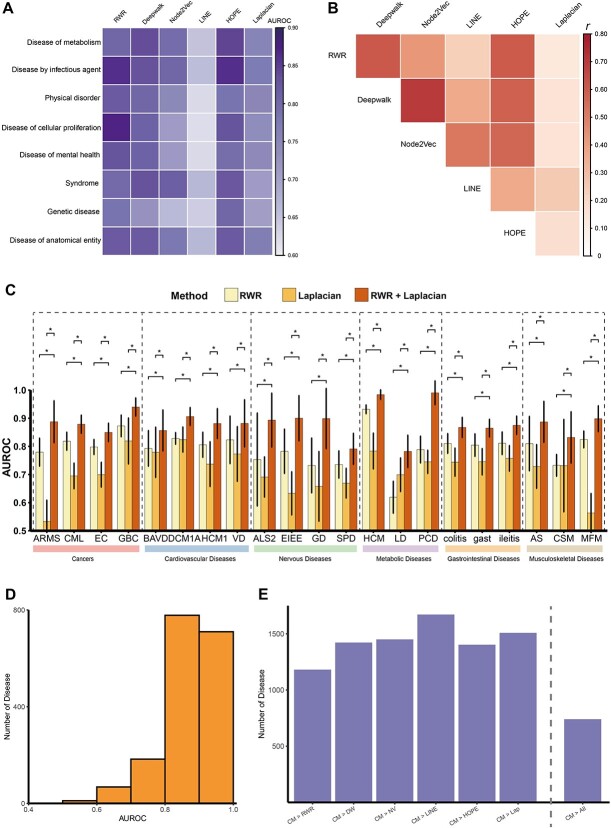
The high-throughput genomic and proteomic scanning approaches allow investigators to measure the quantification of genome-wide genes (or gene products) for certain disease conditions, which plays an essential role in promoting the discovery of disease mechanisms. The high-throughput approaches often generate a large gene list of interest (GOIs), such as differentially expressed genes/proteins. However, researchers have to perform manual triage and validation to explore the most promising, biologically plausible linkages between the known disease genes and GOIs (disease signals) for further study. Here, to address this challenge, we proposed a network-based strategy DDK-Linker to facilitate the exploration of disease signals hidden in omics data by linking GOIs to disease knowns genes. Specifically, it reconstructed gene distances in the protein-protein interaction (PPI) network through six network methods (random walk with restart, Deepwalk, Node2Vec, LINE, HOPE, Laplacian) to discover disease signals in omics data that have shorter distances to disease genes. Furthermore, benefiting from the establishment of knowledge base we established, the abundant bioinformatics annotations were provided for each candidate disease signal. To assist in omics data interpretation and facilitate the usage, we have developed this strategy into an application that users can access through a website or download the R package. We believe DDK-Linker will accelerate the exploring of disease genes and drug targets in a variety of omics data, such as genomics, transcriptomics and proteomics data, and provide clues for complex disease mechanism and pharmacological research. DDK-Linker is freely accessible at http://ddklinker.ncpsb.org.cn/.
高通量基因组和蛋白质组扫描方法使研究人员能够测量特定疾病条件下全基因组基因(或基因产物)的定量,这在促进疾病机制的发现中起着至关重要的作用。高通量方法通常会生成大量感兴趣的基因列表(GOIs),例如差异表达的基因/蛋白质。然而,研究人员必须进行手动分诊和验证,以探索已知疾病基因和 GOIs(疾病信号)之间最有前途、最合理的生物学联系,以便进一步研究。在这里,为了解决这个挑战,我们提出了一种基于网络的策略 DDK-Linker,通过将 GOIs 链接到已知疾病基因,来促进从组学数据中探索隐藏的疾病信号。具体来说,它通过六种网络方法(随机游走重启、Deepwalk、Node2Vec、LINE、HOPE、Laplacian)重建蛋白质-蛋白质相互作用(PPI)网络中的基因距离,以发现与疾病基因距离较短的组学数据中的疾病信号。此外,得益于我们建立的知识库,为每个候选疾病信号提供了丰富的生物信息学注释。为了协助组学数据的解释和方便使用,我们将该策略开发成一个应用程序,用户可以通过网站或下载 R 包进行访问。我们相信 DDK-Linker 将加速在各种组学数据(如基因组学、转录组学和蛋白质组学数据)中探索疾病基因和药物靶点,并为复杂疾病机制和药理学研究提供线索。DDK-Linker 可在 http://ddklinker.ncpsb.org.cn/ 免费访问。