Department of Cardiology, Smidt Heart Institute, Cedars-Sinai Medical Center, Los Angeles, CA, USA.
Department of Bioengineering, University of California Los Angeles, Los Angeles, CA, USA.
Nat Med. 2024 May;30(5):1481-1488. doi: 10.1038/s41591-024-02959-y. Epub 2024 Apr 30.
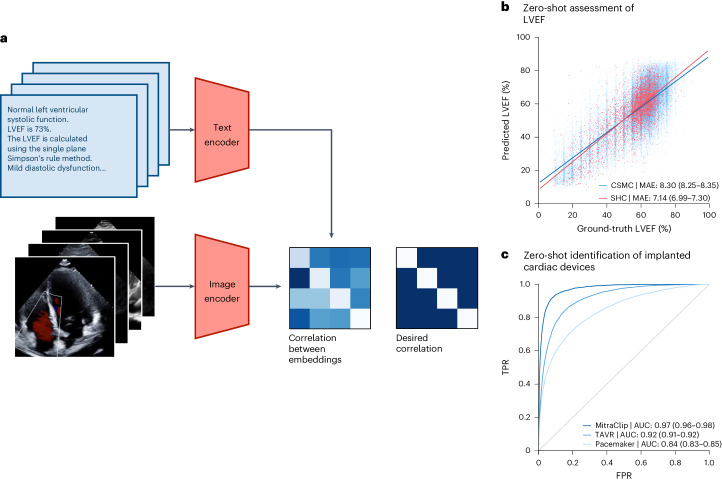
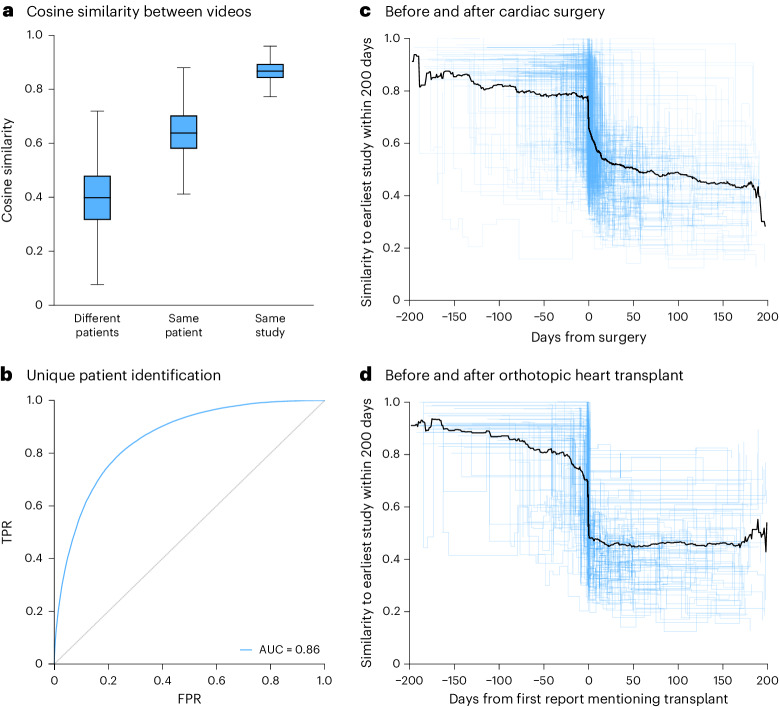
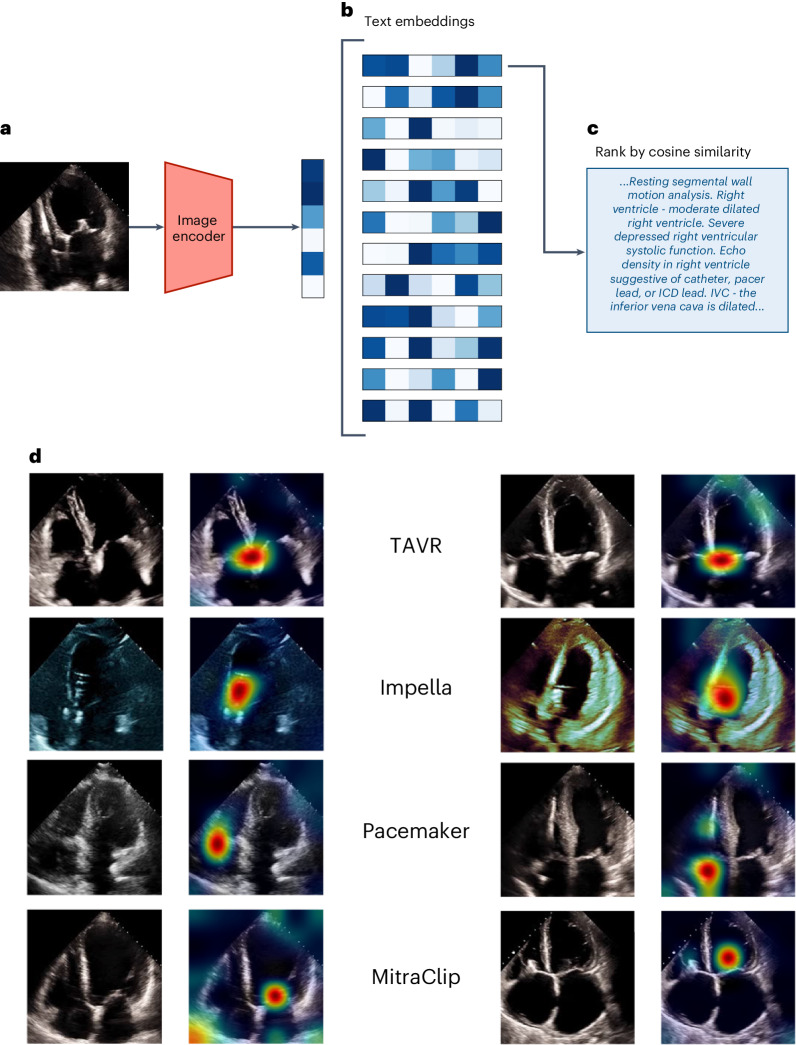
The development of robust artificial intelligence models for echocardiography has been limited by the availability of annotated clinical data. Here, to address this challenge and improve the performance of cardiac imaging models, we developed EchoCLIP, a vision-language foundation model for echocardiography, that learns the relationship between cardiac ultrasound images and the interpretations of expert cardiologists across a wide range of patients and indications for imaging. After training on 1,032,975 cardiac ultrasound videos and corresponding expert text, EchoCLIP performs well on a diverse range of benchmarks for cardiac image interpretation, despite not having been explicitly trained for individual interpretation tasks. EchoCLIP can assess cardiac function (mean absolute error of 7.1% when predicting left ventricular ejection fraction in an external validation dataset) and identify implanted intracardiac devices (area under the curve (AUC) of 0.84, 0.92 and 0.97 for pacemakers, percutaneous mitral valve repair and artificial aortic valves, respectively). We also developed a long-context variant (EchoCLIP-R) using a custom tokenizer based on common echocardiography concepts. EchoCLIP-R accurately identified unique patients across multiple videos (AUC of 0.86), identified clinical transitions such as heart transplants (AUC of 0.79) and cardiac surgery (AUC 0.77) and enabled robust image-to-text search (mean cross-modal retrieval rank in the top 1% of candidate text reports). These capabilities represent a substantial step toward understanding and applying foundation models in cardiovascular imaging for preliminary interpretation of echocardiographic findings.
用于超声心动图的强大人工智能模型的发展受到注释临床数据的可用性的限制。在这里,为了解决这一挑战并提高心脏成像模型的性能,我们开发了 EchoCLIP,这是一种用于超声心动图的视觉语言基础模型,它学习了心脏超声图像与广泛的患者和成像适应症的专家心脏病学家解释之间的关系。在对 1,032,975 个心脏超声视频和相应的专家文本进行训练后,EchoCLIP 在心脏图像解释的各种基准测试中表现出色,尽管它没有针对个别解释任务进行明确训练。EchoCLIP 可以评估心脏功能(在外部验证数据集中预测左心室射血分数的平均绝对误差为 7.1%)和识别植入的心脏内设备(起搏器的曲线下面积 (AUC) 为 0.84、经皮二尖瓣修复术和人工主动脉瓣分别为 0.92 和 0.97)。我们还使用基于常见超声心动图概念的自定义标记器开发了一个长上下文变体 (EchoCLIP-R)。EchoCLIP-R 可以准确识别多个视频中的独特患者(AUC 为 0.86),识别心脏移植(AUC 为 0.79)和心脏手术(AUC 为 0.77)等临床转变,并实现了强大的图像到文本搜索(在候选文本报告的前 1%中,跨模态检索排名的平均值)。这些功能代表了在心血管成像中理解和应用基础模型以初步解释超声心动图结果方面的重大进展。