Harada Yukinori, Sakamoto Tetsu, Sugimoto Shu, Shimizu Taro
Department of Diagnostic and Generalist Medicine, Dokkyo Medical University, Shimotsuga, Japan.
Department of General Medicine, Nagano Chuo Hospital, Nagano, Japan.
JMIR Form Res. 2024 May 17;8:e53985. doi: 10.2196/53985.
Artificial intelligence (AI) symptom checker models should be trained using real-world patient data to improve their diagnostic accuracy. Given that AI-based symptom checkers are currently used in clinical practice, their performance should improve over time. However, longitudinal evaluations of the diagnostic accuracy of these symptom checkers are limited.
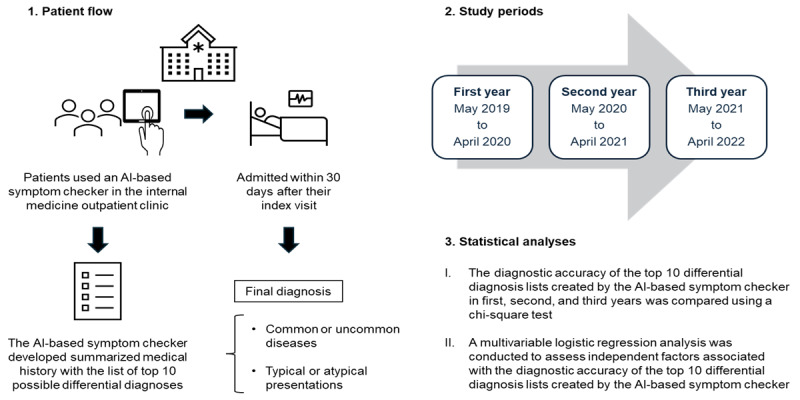
This study aimed to assess the longitudinal changes in the accuracy of differential diagnosis lists created by an AI-based symptom checker used in the real world.
This was a single-center, retrospective, observational study. Patients who visited an outpatient clinic without an appointment between May 1, 2019, and April 30, 2022, and who were admitted to a community hospital in Japan within 30 days of their index visit were considered eligible. We only included patients who underwent an AI-based symptom checkup at the index visit, and the diagnosis was finally confirmed during follow-up. Final diagnoses were categorized as common or uncommon, and all cases were categorized as typical or atypical. The primary outcome measure was the accuracy of the differential diagnosis list created by the AI-based symptom checker, defined as the final diagnosis in a list of 10 differential diagnoses created by the symptom checker. To assess the change in the symptom checker's diagnostic accuracy over 3 years, we used a chi-square test to compare the primary outcome over 3 periods: from May 1, 2019, to April 30, 2020 (first year); from May 1, 2020, to April 30, 2021 (second year); and from May 1, 2021, to April 30, 2022 (third year).
A total of 381 patients were included. Common diseases comprised 257 (67.5%) cases, and typical presentations were observed in 298 (78.2%) cases. Overall, the accuracy of the differential diagnosis list created by the AI-based symptom checker was 172 (45.1%), which did not differ across the 3 years (first year: 97/219, 44.3%; second year: 32/72, 44.4%; and third year: 43/90, 47.7%; P=.85). The accuracy of the differential diagnosis list created by the symptom checker was low in those with uncommon diseases (30/124, 24.2%) and atypical presentations (12/83, 14.5%). In the multivariate logistic regression model, common disease (P<.001; odds ratio 4.13, 95% CI 2.50-6.98) and typical presentation (P<.001; odds ratio 6.92, 95% CI 3.62-14.2) were significantly associated with the accuracy of the differential diagnosis list created by the symptom checker.
A 3-year longitudinal survey of the diagnostic accuracy of differential diagnosis lists developed by an AI-based symptom checker, which has been implemented in real-world clinical practice settings, showed no improvement over time. Uncommon diseases and atypical presentations were independently associated with a lower diagnostic accuracy. In the future, symptom checkers should be trained to recognize uncommon conditions.
人工智能(AI)症状检查模型应使用真实世界的患者数据进行训练,以提高其诊断准确性。鉴于基于AI的症状检查器目前已应用于临床实践,其性能应会随着时间的推移而提高。然而,对这些症状检查器诊断准确性的纵向评估有限。
本研究旨在评估在现实世界中使用的基于AI的症状检查器所创建的鉴别诊断列表准确性的纵向变化。
这是一项单中心、回顾性观察研究。2019年5月1日至2022年4月30日期间未预约就诊于门诊诊所,且在首次就诊后30天内入住日本社区医院的患者被视为符合条件。我们仅纳入了在首次就诊时接受基于AI症状检查的患者,且诊断在随访期间最终得以确认。最终诊断分为常见或不常见,所有病例分为典型或非典型。主要结局指标是基于AI的症状检查器所创建的鉴别诊断列表的准确性,定义为症状检查器创建的10个鉴别诊断列表中的最终诊断。为评估症状检查器诊断准确性在3年中的变化,我们使用卡方检验比较3个时间段的主要结局:2019年5月1日至2020年4月30日(第一年);2020年5月1日至2021年4月30日(第二年);以及2021年5月1日至2022年4月30日(第三年)。
共纳入381例患者。常见疾病包括257例(67.5%),298例(78.2%)观察到典型表现。总体而言,基于AI的症状检查器所创建的鉴别诊断列表的准确性为172例(45.1%),在3年中无差异(第一年:97/219,44.3%;第二年:32/72,4,4.4%;第三年:43/90,47.7%;P = 0.85)。症状检查器所创建的鉴别诊断列表在患有不常见疾病(30/124,24.2%)和非典型表现(12/83,14.5%)的患者中准确性较低。在多变量逻辑回归模型中,常见疾病(P < 0.001;比值比4.13,95% CI 2.50 - 6.98)和典型表现(P < 0.001;比值比6.92,95% CI 3.62 - 14.2)与症状检查器所创建的鉴别诊断列表的准确性显著相关。
对在现实世界临床实践环境中实施的基于AI的症状检查器所开发的鉴别诊断列表的诊断准确性进行的为期3年的纵向调查显示,其准确性并未随时间提高。不常见疾病和非典型表现与较低的诊断准确性独立相关。未来,应训练症状检查器识别不常见病症。