BMJ Open. 2024 May 21;14(5):e081155. doi: 10.1136/bmjopen-2023-081155.
Large language model (LLM)-linked chatbots are being increasingly applied in healthcare due to their impressive functionality and public availability. Studies have assessed the ability of LLM-linked chatbots to provide accurate clinical advice. However, the methods applied in these Chatbot Assessment Studies are inconsistent due to the lack of reporting standards available, which obscures the interpretation of their study findings. This protocol outlines the development of the Chatbot Assessment Reporting Tool (CHART) reporting guideline.
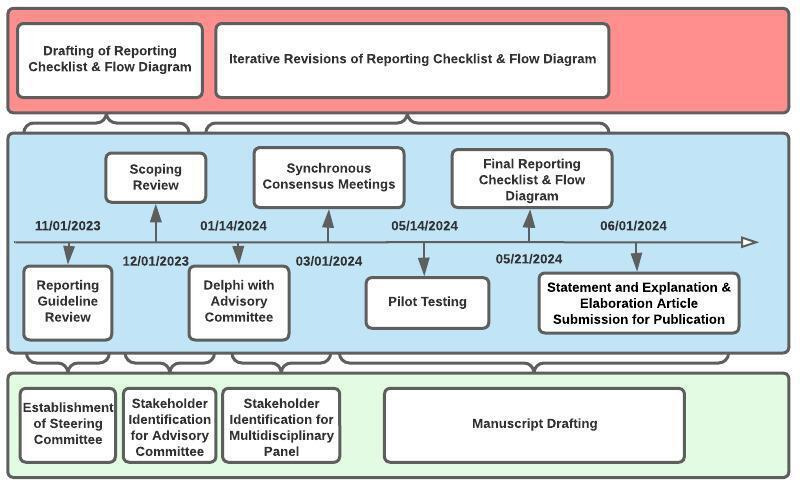
The development of the CHART reporting guideline will consist of three phases, led by the Steering Committee. During phase one, the team will identify relevant reporting guidelines with artificial intelligence extensions that are published or in development by searching preprint servers, protocol databases, and the Enhancing the Quality and Transparency of health research Network. During phase two, we will conduct a scoping review to identify studies that have addressed the performance of LLM-linked chatbots in summarising evidence and providing clinical advice. The Steering Committee will identify methodology used in previous Chatbot Assessment Studies. Finally, the study team will use checklist items from prior reporting guidelines and findings from the scoping review to develop a draft reporting checklist. We will then perform a Delphi consensus and host two synchronous consensus meetings with an international, multidisciplinary group of stakeholders to refine reporting checklist items and develop a flow diagram.
We will publish the final CHART reporting guideline in peer-reviewed journals and will present findings at peer-reviewed meetings. Ethical approval was submitted to the Hamilton Integrated Research Ethics Board and deemed "not required" in accordance with the Tri-Council Policy Statement (TCPS2) for the development of the CHART reporting guideline (#17025).
This study protocol is preregistered with Open Science Framework: https://doi.org/10.17605/OSF.IO/59E2Q.
由于大型语言模型 (LLM)-链接的聊天机器人具有令人印象深刻的功能和公众可用性,因此它们在医疗保健中被越来越多地应用。已经有研究评估了 LLM 链接的聊天机器人提供准确临床建议的能力。然而,由于缺乏可用的报告标准,这些 Chatbot Assessment Studies 应用的方法不一致,这使得他们的研究结果难以解释。本方案概述了 Chatbot Assessment Reporting Tool (CHART) 报告指南的制定。
CHART 报告指南的制定将由指导委员会领导,分为三个阶段。在第一阶段,团队将通过搜索预印本服务器、协议数据库和 Enhancing the Quality and Transparency of health research Network,确定人工智能扩展的相关报告指南,这些指南已发布或正在开发中。在第二阶段,我们将进行范围综述,以确定研究 LLM 链接的聊天机器人在总结证据和提供临床建议方面的性能。指导委员会将确定之前 Chatbot Assessment Studies 中使用的方法。最后,研究团队将使用之前报告指南的检查表项目和范围综述的结果制定一份报告检查表草案。然后,我们将进行 Delphi 共识,并与一个国际多学科利益相关者小组举行两次同步共识会议,以完善报告检查表项目并制定流程图。
我们将在同行评议期刊上发表最终的 CHART 报告指南,并将在同行评议会议上介绍研究结果。根据 Hamilton Integrated Research Ethics Board 的规定,由于 TCPS2 开发 CHART 报告指南 (#17025),因此本研究无需伦理批准。
本研究方案已在 Open Science Framework 上预先注册:https://doi.org/10.17605/OSF.IO/59E2Q。