Center for Computational Biology, University of California, Berkeley, Berkeley, CA, USA.
Department of Electrical Engineering and Computer Sciences, University of California, Berkeley, Berkeley, CA, USA.
Genome Biol. 2024 Aug 1;25(1):202. doi: 10.1186/s13059-024-03335-2.
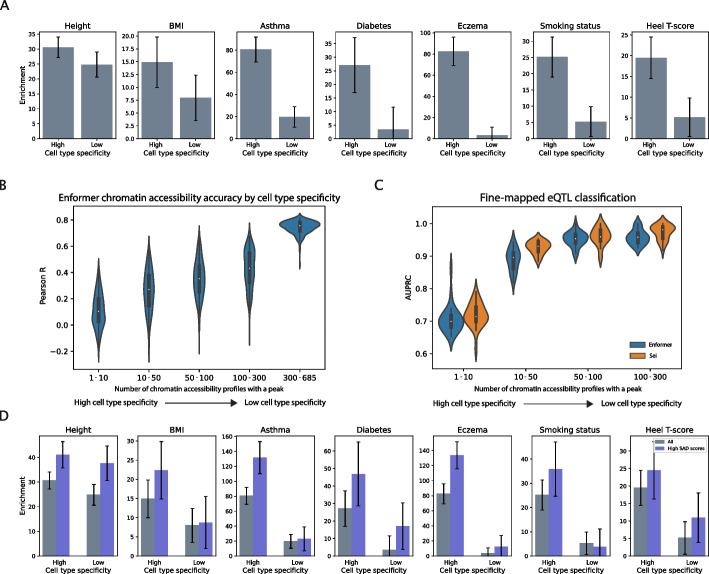
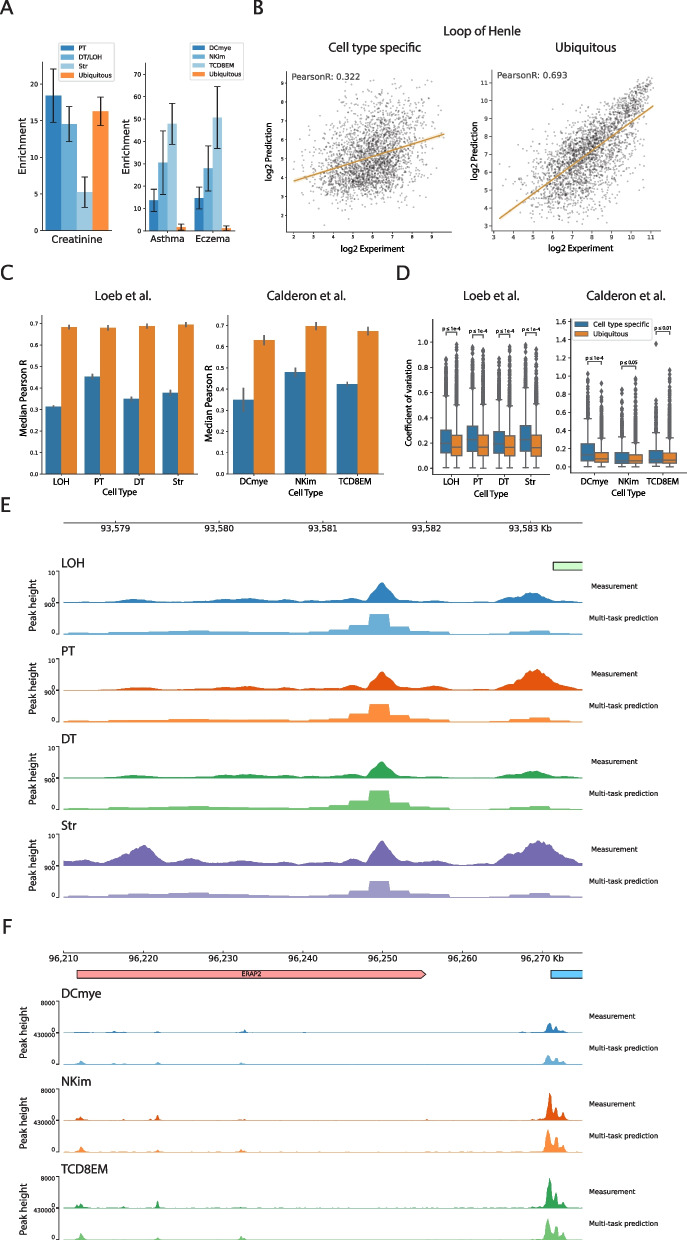
A number of deep learning models have been developed to predict epigenetic features such as chromatin accessibility from DNA sequence. Model evaluations commonly report performance genome-wide; however, cis regulatory elements (CREs), which play critical roles in gene regulation, make up only a small fraction of the genome. Furthermore, cell type-specific CREs contain a large proportion of complex disease heritability.
We evaluate genomic deep learning models in chromatin accessibility regions with varying degrees of cell type specificity. We assess two modeling directions in the field: general purpose models trained across thousands of outputs (cell types and epigenetic marks) and models tailored to specific tissues and tasks. We find that the accuracy of genomic deep learning models, including two state-of-the-art general purpose models-Enformer and Sei-varies across the genome and is reduced in cell type-specific accessible regions. Using accessibility models trained on cell types from specific tissues, we find that increasing model capacity to learn cell type-specific regulatory syntax-through single-task learning or high capacity multi-task models-can improve performance in cell type-specific accessible regions. We also observe that improving reference sequence predictions does not consistently improve variant effect predictions, indicating that novel strategies are needed to improve performance on variants.
Our results provide a new perspective on the performance of genomic deep learning models, showing that performance varies across the genome and is particularly reduced in cell type-specific accessible regions. We also identify strategies to maximize performance in cell type-specific accessible regions.
已经开发出许多深度学习模型,可从 DNA 序列预测表观遗传特征,如染色质可及性。模型评估通常在全基因组范围内报告性能;然而,顺式调控元件(CREs)在基因调控中起着关键作用,仅占基因组的一小部分。此外,细胞类型特异性 CREs 包含大量复杂疾病遗传率。
我们评估了具有不同细胞类型特异性程度的染色质可及性区域的基因组深度学习模型。我们评估了该领域的两种建模方向:跨数千个输出(细胞类型和表观遗传标记)训练的通用模型和针对特定组织和任务的模型。我们发现,基因组深度学习模型的准确性,包括两种最先进的通用模型-Enformer 和 Sei-在整个基因组中各不相同,并且在细胞类型特异性可及区域中降低。使用来自特定组织的细胞类型训练的可及性模型,我们发现通过单任务学习或大容量多任务模型增加模型学习细胞类型特异性调节语法的能力可以提高细胞类型特异性可及区域的性能。我们还观察到,改进参考序列预测并不总是能提高变异效应预测,这表明需要新的策略来提高变体性能。
我们的结果提供了基因组深度学习模型性能的新视角,表明性能在整个基因组中各不相同,特别是在细胞类型特异性可及区域中降低。我们还确定了在细胞类型特异性可及区域中最大化性能的策略。