Department of Diabetes, Endocrinology, and Metabolism, Fukushima Medical University School of Medicine, Fukushima, Japan.
Department of Diabetes, Metabolism and Endocrinology, Tohoku University Graduate School of Medicine, Miyagi, Japan.
Diabetologia. 2024 Nov;67(11):2446-2458. doi: 10.1007/s00125-024-06248-8. Epub 2024 Aug 21.
AIMS/HYPOTHESIS: Clustering-based subclassification of type 2 diabetes, which reflects pathophysiology and genetic predisposition, is a promising approach for providing personalised and effective therapeutic strategies. Ahlqvist's classification is currently the most vigorously validated method because of its superior ability to predict diabetes complications but it does not have strong consistency over time and requires HOMA2 indices, which are not routinely available in clinical practice and standard cohort studies. We developed a machine learning (ML) model to classify individuals with type 2 diabetes into Ahlqvist's subtypes consistently over time.
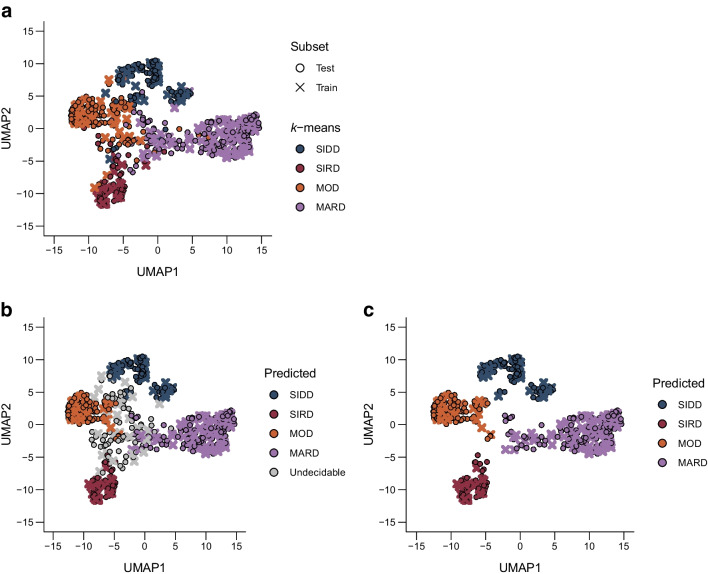
Cohort 1 dataset comprised 619 Japanese individuals with type 2 diabetes who were divided into training and test sets for ML models in a 7:3 ratio. Cohort 2 dataset, comprising 597 individuals with type 2 diabetes, was used for external validation. Participants were pre-labelled (T2D) by unsupervised k-means clustering based on Ahlqvist's variables (age at diagnosis, BMI, HbA, HOMA2-B and HOMA2-IR) to four subtypes: severe insulin-deficient diabetes (SIDD), severe insulin-resistant diabetes (SIRD), mild obesity-related diabetes (MOD) and mild age-related diabetes (MARD). We adopted 15 variables for a multiclass classification random forest (RF) algorithm to predict type 2 diabetes subtypes (T2D). The proximity matrix computed by RF was visualised using a uniform manifold approximation and projection. Finally, we used a putative subset with missing insulin-related variables to test the predictive performance of the validation cohort, consistency of subtypes over time and prediction ability of diabetes complications.
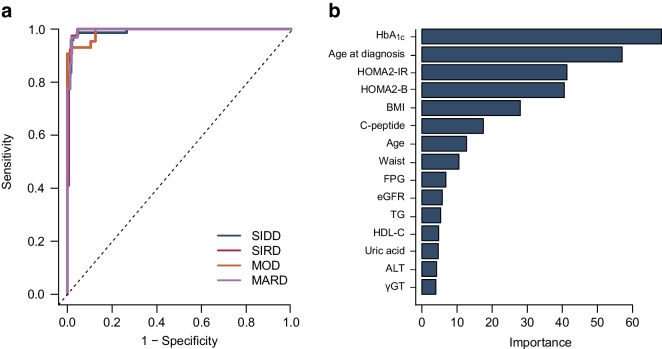
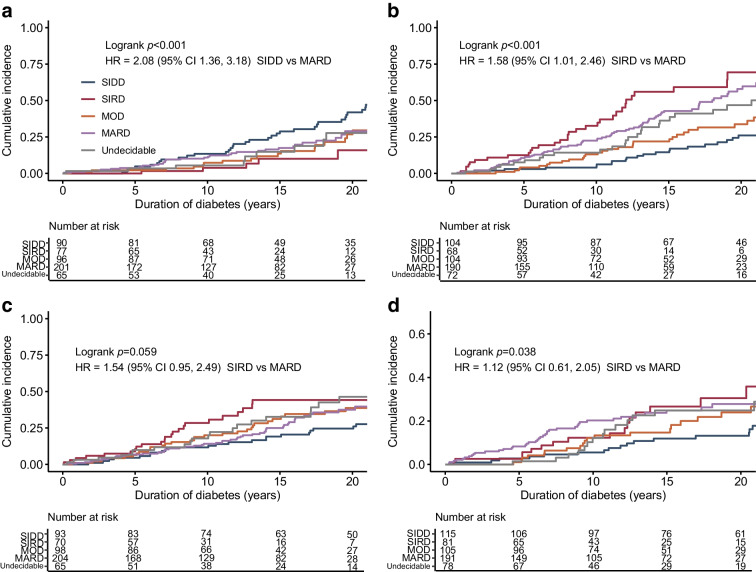
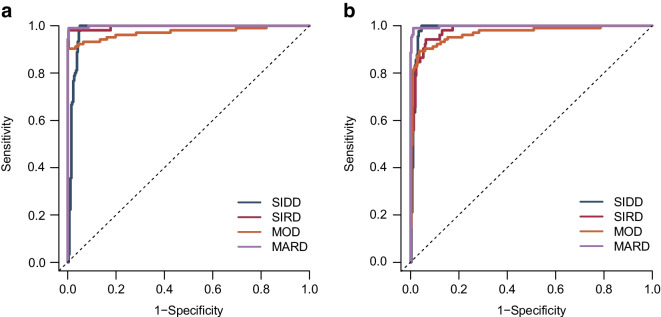
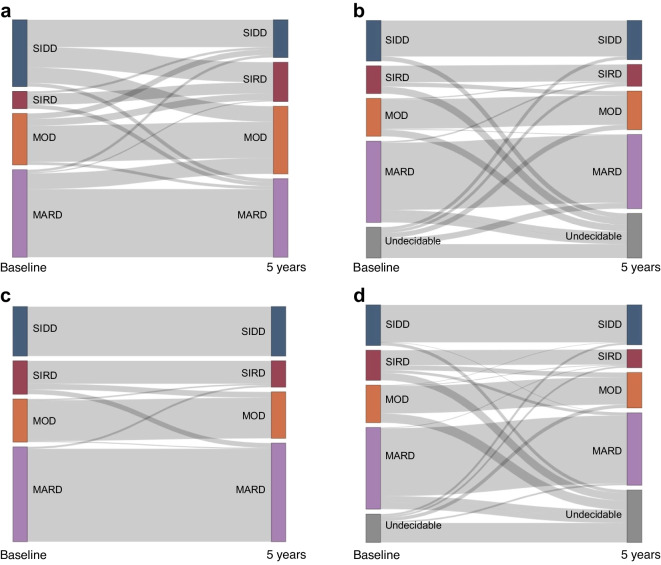
T2D demonstrated a 94% accuracy for predicting T2D type 2 diabetes subtypes (AUCs ≥0.99 and F1 score [an indicator calculated by harmonic mean from precision and recall] ≥0.9) and retained the predictive performance in the external validation cohort (86.3%). T2D showed an accuracy of 82.9% for detecting T2D, also in a putative subset with missing insulin-related variables, when used with an imputation algorithm. In Kaplan-Meier analysis, the diabetes clusters of T2D demonstrated distinct accumulation risks of diabetic retinopathy in SIDD and that of chronic kidney disease in SIRD during a median observation period of 11.6 (4.5-18.3) years, similarly to the subtypes using T2D. The predictive accuracy was improved after excluding individuals with low predictive probability, who were categorised as an 'undecidable' cluster. T2D, after excluding undecidable individuals, showed higher consistency (100% for SIDD, 68.6% for SIRD, 94.4% for MOD and 97.9% for MARD) than T2D.
CONCLUSIONS/INTERPRETATION: The new ML model for predicting Ahlqvist's subtypes of type 2 diabetes has great potential for application in clinical practice and cohort studies because it can classify individuals with missing HOMA2 indices and predict glycaemic control, diabetic complications and treatment outcomes with long-term consistency by using readily available variables. Future studies are needed to assess whether our approach is applicable to research and/or clinical practice in multiethnic populations.
目的/假设:基于聚类的 2 型糖尿病亚分类,反映了病理生理学和遗传易感性,是提供个性化和有效的治疗策略的有前途的方法。由于其预测糖尿病并发症的能力较强,Ahlqvist 分类目前是最有力的验证方法,但它在时间上一致性不强,且需要 HOMA2 指数,而这些在临床实践和标准队列研究中并不常用。我们开发了一种机器学习 (ML) 模型,可以随着时间的推移始终如一地将 2 型糖尿病患者分为 Ahlqvist 亚型。
队列 1 数据集包含 619 名日本 2 型糖尿病患者,他们被分为训练集和测试集,用于 ML 模型的比例为 7:3。队列 2 数据集包含 597 名 2 型糖尿病患者,用于外部验证。参与者根据 Ahlqvist 的变量(诊断时的年龄、BMI、HbA、HOMA2-B 和 HOMA2-IR)通过无监督的 k-均值聚类预先标记为(T2D),分为 4 种亚型:严重胰岛素缺乏型糖尿病(SIDD)、严重胰岛素抵抗型糖尿病(SIRD)、轻度肥胖相关型糖尿病(MOD)和轻度年龄相关型糖尿病(MARD)。我们采用了 15 个变量进行多类分类随机森林 (RF) 算法,以预测 2 型糖尿病亚型(T2D)。由 RF 计算的接近度矩阵使用一致流形逼近和投影进行可视化。最后,我们使用一个具有缺失胰岛素相关变量的假定子集来测试验证队列的预测性能、亚型随时间的一致性以及糖尿病并发症的预测能力。
T2D 对预测 2 型糖尿病亚型(AUC≥0.99,F1 得分[由精度和召回率的调和平均值计算得出]≥0.9)的准确率为 94%,并在外部验证队列中保留了预测性能(86.3%)。T2D 在使用缺失胰岛素相关变量的假定子集中的准确率为 82.9%,用于检测 T2D,当与一个插补算法一起使用时。在 Kaplan-Meier 分析中,T2D 的糖尿病聚类在 SIDD 中显示出糖尿病视网膜病变的明显累积风险,在 SIRD 中显示出慢性肾脏病的风险,在中位数为 11.6(4.5-18.3)年的观察期间,与使用 T2D 的亚型相似。在排除低预测概率的个体(归类为“不可判定”聚类)后,预测准确性得到提高。在排除不可判定个体后,T2D 的一致性更高(SIDD 为 100%,SIRD 为 68.6%,MOD 为 94.4%,MARD 为 97.9%)。
结论/解释:用于预测 2 型糖尿病 Ahlqvist 亚型的新 ML 模型在临床实践和队列研究中具有很大的应用潜力,因为它可以对缺失 HOMA2 指数的个体进行分类,并使用现成的变量长期保持一致性地预测血糖控制、糖尿病并发症和治疗结果。需要进一步研究以评估我们的方法是否适用于多民族人群的研究和/或临床实践。