Division of Digital Psychiatry, Beth Israel Deaconess Medical Center, Harvard Medical School, Boston, MA, United States.
Case Western Reserve University School of Medicine,, Cleveland, OH, United States.
J Med Internet Res. 2024 Aug 23;26:e58502. doi: 10.2196/58502.
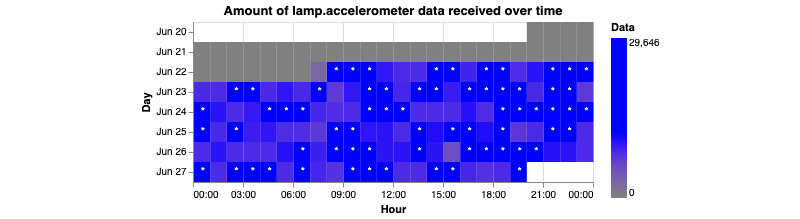
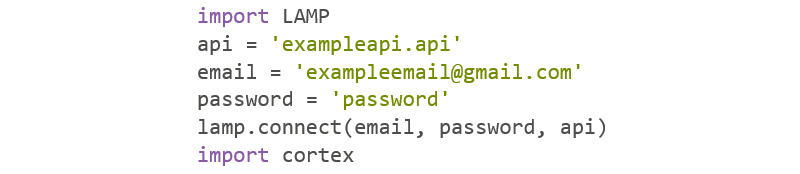
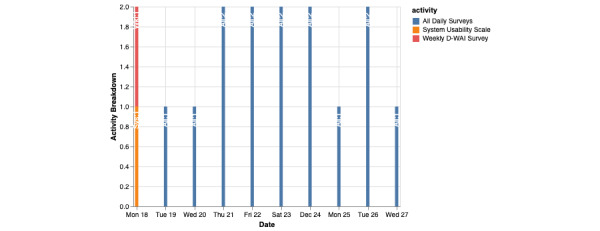
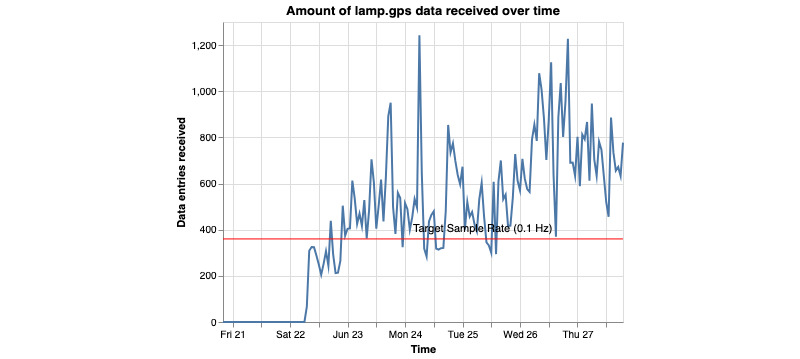
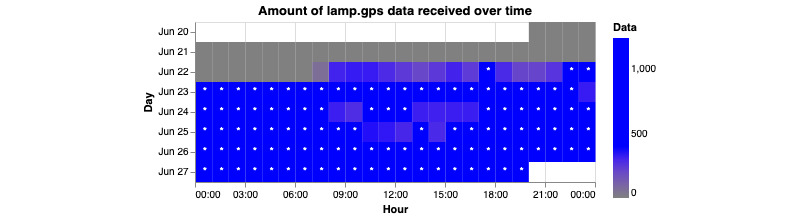
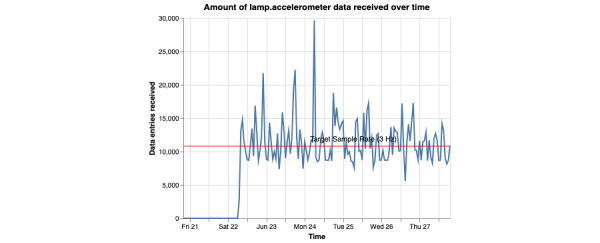
As digital phenotyping, the capture of active and passive data from consumer devices such as smartphones, becomes more common, the need to properly process the data and derive replicable features from it has become paramount. Cortex is an open-source data processing pipeline for digital phenotyping data, optimized for use with the mindLAMP apps, which is used by nearly 100 research teams across the world. Cortex is designed to help teams (1) assess digital phenotyping data quality in real time, (2) derive replicable clinical features from the data, and (3) enable easy-to-share data visualizations. Cortex offers many options to work with digital phenotyping data, although some common approaches are likely of value to all teams using it. This paper highlights the reasoning, code, and example steps necessary to fully work with digital phenotyping data in a streamlined manner. Covering how to work with the data, assess its quality, derive features, and visualize findings, this paper is designed to offer the reader the knowledge and skills to apply toward analyzing any digital phenotyping data set. More specifically, the paper will teach the reader the ins and outs of the Cortex Python package. This includes background information on its interaction with the mindLAMP platform, some basic commands to learn what data can be pulled and how, and more advanced use of the package mixed with basic Python with the goal of creating a correlation matrix. After the tutorial, different use cases of Cortex are discussed, along with limitations. Toward highlighting clinical applications, this paper also provides 3 easy ways to implement examples of Cortex use in real-world settings. By understanding how to work with digital phenotyping data and providing ready-to-deploy code with Cortex, the paper aims to show how the new field of digital phenotyping can be both accessible to all and rigorous in methodology.
随着数字表型学的发展,从智能手机等消费者设备中捕获主动和被动数据变得越来越普遍,因此正确处理数据并从中提取可重复的特征变得至关重要。Cortex 是一个用于数字表型数据的开源数据处理管道,针对 mindLAMP 应用程序进行了优化,目前全球有近 100 个研究团队在使用。Cortex 旨在帮助团队:(1)实时评估数字表型数据质量;(2)从数据中提取可重复的临床特征;(3)实现易于共享的数据可视化。Cortex 提供了许多处理数字表型数据的选项,尽管一些常见的方法可能对所有使用它的团队都有价值。本文重点介绍了以简化的方式全面处理数字表型数据所需的推理、代码和示例步骤。涵盖了如何处理数据、评估其质量、提取特征和可视化结果,本文旨在为读者提供分析任何数字表型数据集所需的知识和技能。更具体地说,本文将向读者介绍 Cortex Python 包的来龙去脉。这包括其与 mindLAMP 平台交互的背景信息、一些基本命令,用于了解可以提取哪些数据以及如何提取,以及更高级的使用包与基本 Python 的混合,目的是创建相关矩阵。在教程之后,讨论了 Cortex 的不同用例以及限制。为了突出临床应用,本文还提供了在实际环境中实施 Cortex 使用示例的 3 种简单方法。通过了解如何处理数字表型数据并提供带有 Cortex 的可立即部署的代码,本文旨在展示数字表型学这一新领域如何既对所有人开放,又在方法上严谨。