Shinde Anjali, Shahra Essa Q, Basurra Shadi, Saeed Faisal, AlSewari Abdulrahman A, Jabbar Waheb A
Faculty of Computing, Engineering and Built Environment, Birmingham City University, Birmingham B4 7RQ, UK.
Sensors (Basel). 2024 Sep 20;24(18):6084. doi: 10.3390/s24186084.
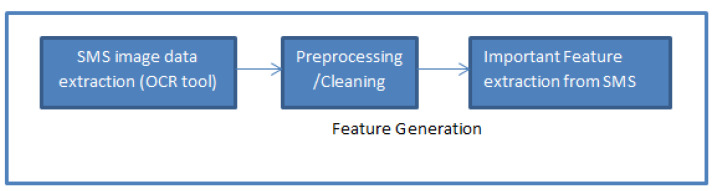
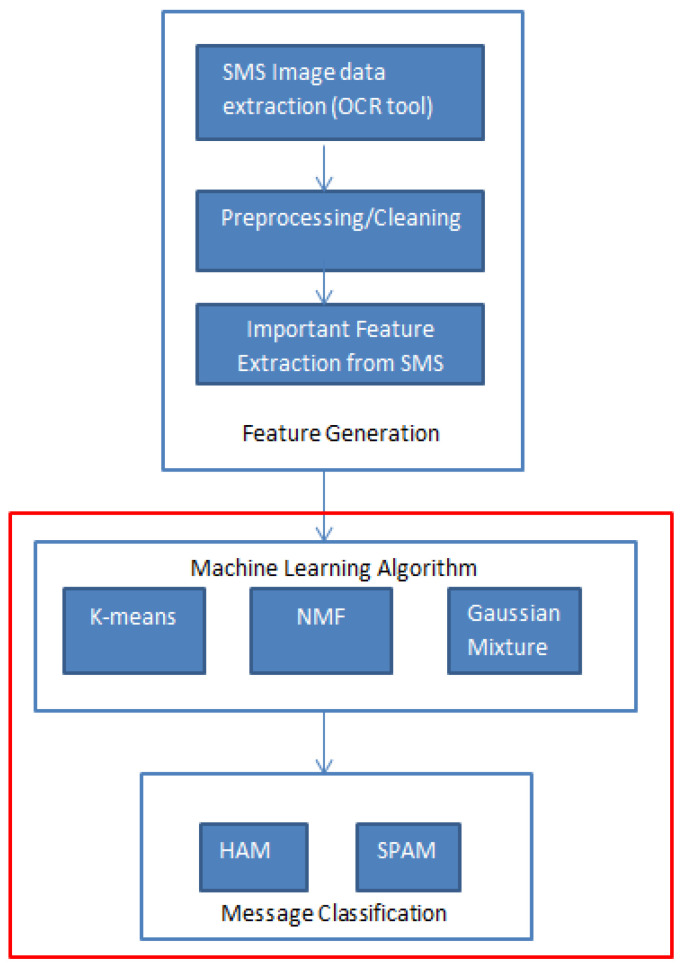
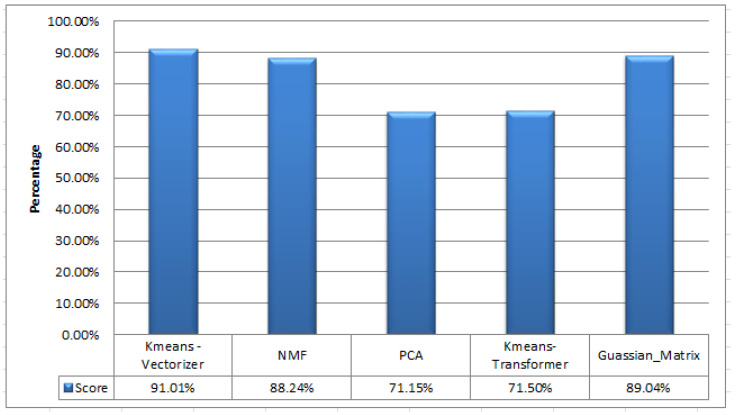
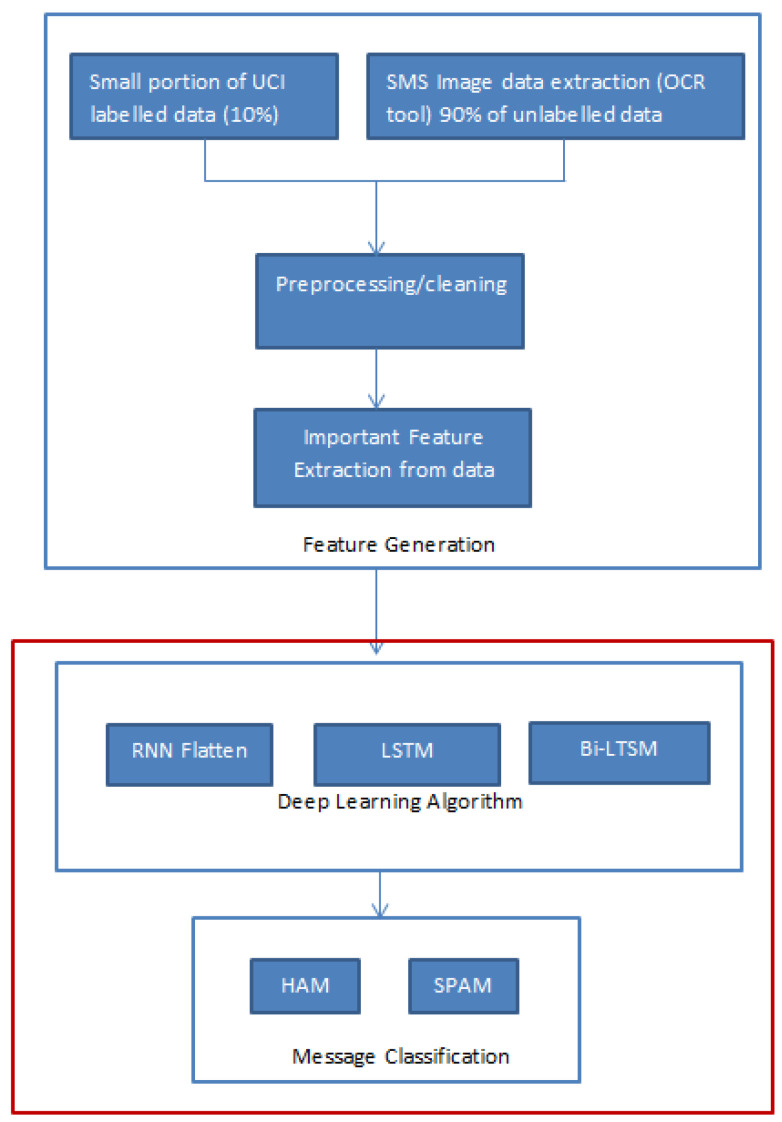
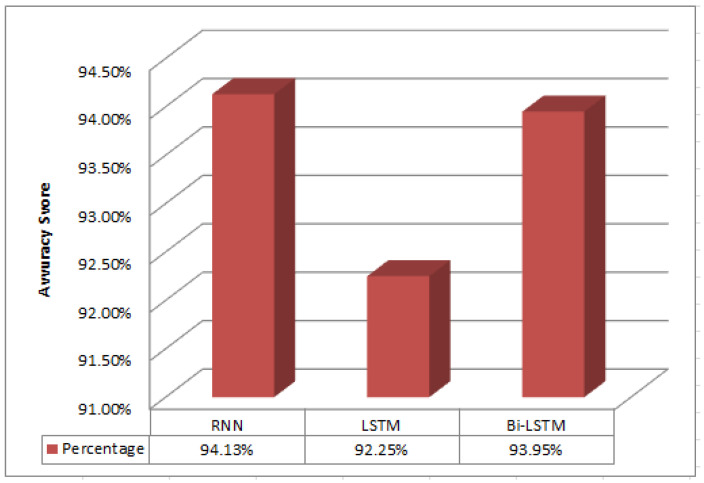
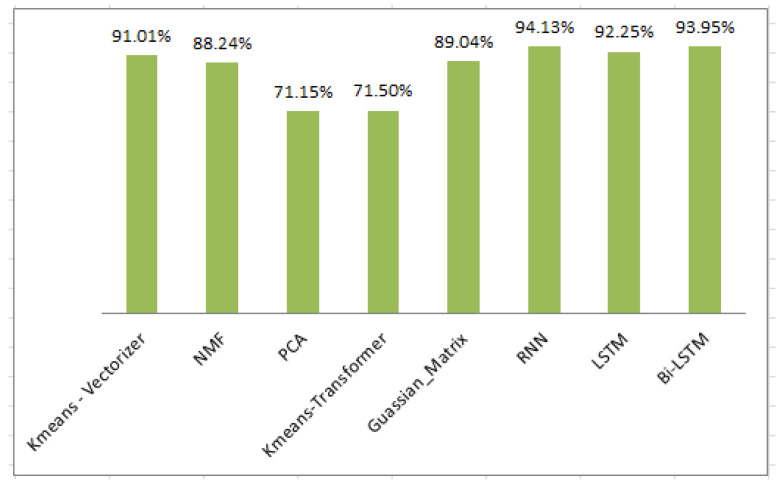
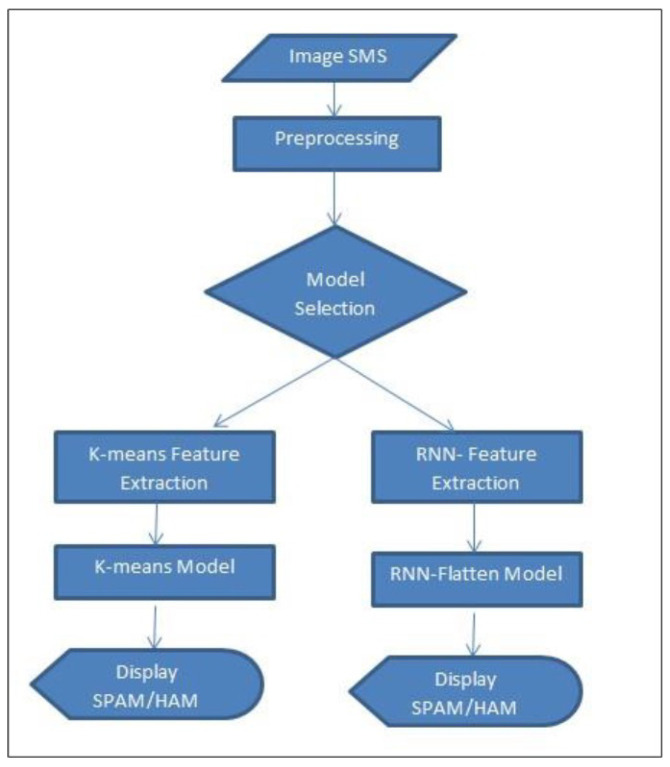
The growing problem of unsolicited text messages (smishing) and data irregularities necessitates stronger spam detection solutions. This paper explores the development of a sophisticated model designed to identify smishing messages by understanding the complex relationships among words, images, and context-specific factors, areas that remain underexplored in existing research. To address this, we merge a UCI spam dataset of regular text messages with real-world spam data, leveraging OCR technology for comprehensive analysis. The study employs a combination of traditional machine learning models, including K-means, Non-Negative Matrix Factorization, and Gaussian Mixture Models, along with feature extraction techniques such as TF-IDF and PCA. Additionally, deep learning models like RNN-Flatten, LSTM, and Bi-LSTM are utilized. The selection of these models is driven by their complementary strengths in capturing both the linear and non-linear relationships inherent in smishing messages. Machine learning models are chosen for their efficiency in handling structured text data, while deep learning models are selected for their superior ability to capture sequential dependencies and contextual nuances. The performance of these models is rigorously evaluated using metrics like accuracy, precision, recall, and F1 score, enabling a comparative analysis between the machine learning and deep learning approaches. Notably, the K-means feature extraction with vectorizer achieved 91.01% accuracy, and the KNN-Flatten model reached 94.13% accuracy, emerging as the top performer. The rationale behind highlighting these models is their potential to significantly improve smishing detection rates. For instance, the high accuracy of the KNN-Flatten model suggests its applicability in real-time spam detection systems, but its computational complexity might limit scalability in large-scale deployments. Similarly, while K-means with vectorizer excels in accuracy, it may struggle with the dynamic and evolving nature of smishing attacks, necessitating continual retraining.
未经请求的短信(网络钓鱼短信)和数据违规问题日益严重,因此需要更强大的垃圾邮件检测解决方案。本文探讨了一种复杂模型的开发,该模型旨在通过理解单词、图像和特定上下文因素之间的复杂关系来识别网络钓鱼短信,而这些领域在现有研究中仍未得到充分探索。为了解决这个问题,我们将UCI常规短信垃圾邮件数据集与现实世界中的垃圾邮件数据合并,并利用光学字符识别(OCR)技术进行全面分析。该研究采用了多种传统机器学习模型,包括K均值、非负矩阵分解和高斯混合模型,以及诸如词频-逆文档频率(TF-IDF)和主成分分析(PCA)等特征提取技术。此外,还使用了诸如递归神经网络-展平(RNN-Flatten)、长短期记忆网络(LSTM)和双向长短期记忆网络(Bi-LSTM)等深度学习模型。选择这些模型是因为它们在捕捉网络钓鱼短信中固有的线性和非线性关系方面具有互补优势。选择机器学习模型是因为它们在处理结构化文本数据方面效率高,而选择深度学习模型是因为它们在捕捉序列依赖性和上下文细微差别方面具有卓越能力。使用诸如准确率、精确率、召回率和F1分数等指标对这些模型的性能进行了严格评估,从而能够对机器学习方法和深度学习方法进行比较分析。值得注意的是,使用向量化器的K均值特征提取的准确率达到了91.01%,而KNN-展平模型的准确率达到了94.13%,成为表现最佳的模型。突出这些模型的背后原因是它们有显著提高网络钓鱼检测率的潜力。例如,KNN-展平模型的高准确率表明它适用于实时垃圾邮件检测系统,但其计算复杂性可能会限制大规模部署中的可扩展性。同样,虽然带向量化器的K均值在准确率方面表现出色,但它可能难以应对网络钓鱼攻击的动态性和不断变化的性质,因此需要持续重新训练。