Department of Trauma and Orthopedic Surgery, BG Klinik Ludwigshafen, Ludwigshafen am Rhein, Germany.
J Med Internet Res. 2024 Oct 1;26:e58831. doi: 10.2196/58831.
Artificial intelligence and the language models derived from it, such as ChatGPT, offer immense possibilities, particularly in the field of medicine. It is already evident that ChatGPT can provide adequate and, in some cases, expert-level responses to health-related queries and advice for patients. However, it is currently unknown how patients perceive these capabilities, whether they can derive benefit from them, and whether potential risks, such as harmful suggestions, are detected by patients.
This study aims to clarify whether patients can get useful and safe health care advice from an artificial intelligence chatbot assistant.
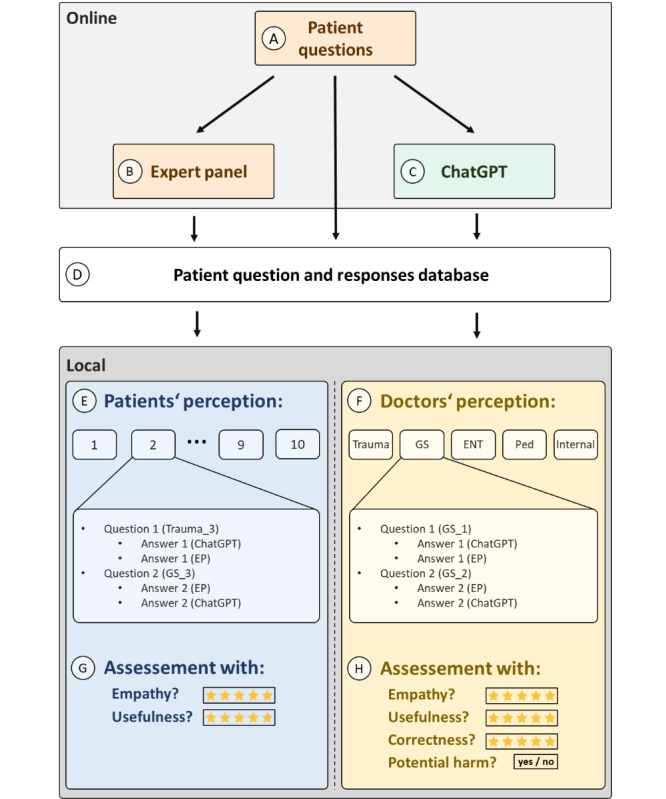
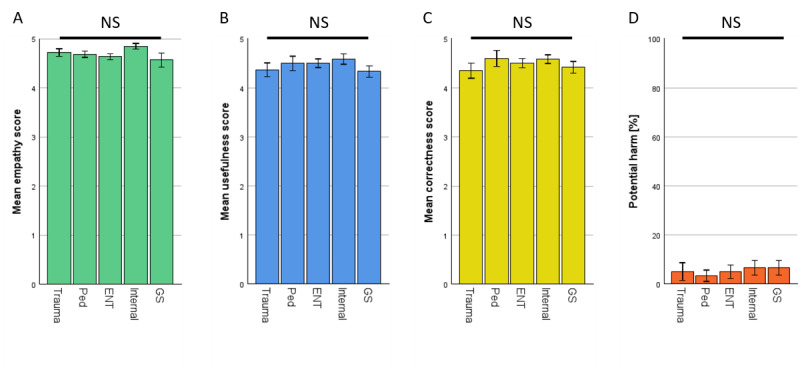
This cross-sectional study was conducted using 100 publicly available health-related questions from 5 medical specialties (trauma, general surgery, otolaryngology, pediatrics, and internal medicine) from a web-based platform for patients. Responses generated by ChatGPT-4.0 and by an expert panel (EP) of experienced physicians from the aforementioned web-based platform were packed into 10 sets consisting of 10 questions each. The blinded evaluation was carried out by patients regarding empathy and usefulness (assessed through the question: "Would this answer have helped you?") on a scale from 1 to 5. As a control, evaluation was also performed by 3 physicians in each respective medical specialty, who were additionally asked about the potential harm of the response and its correctness.
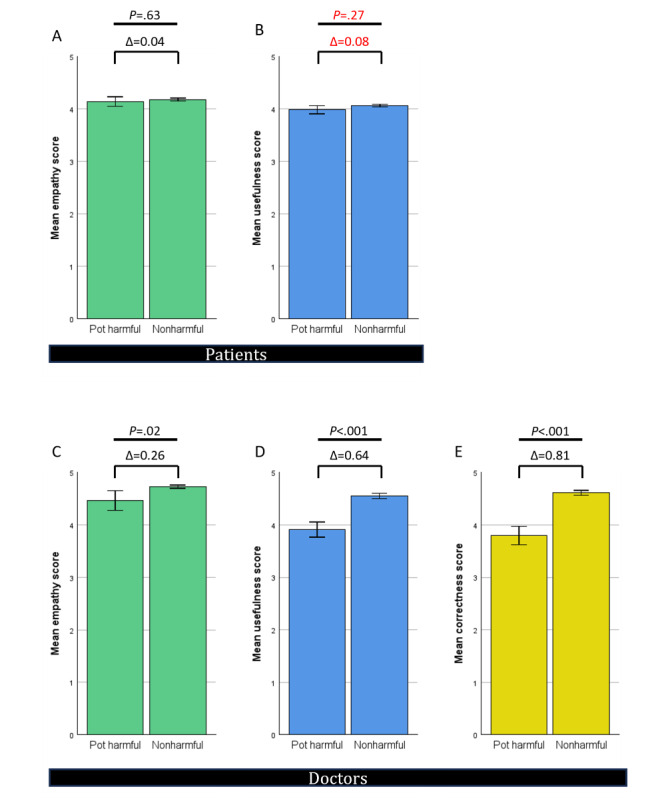
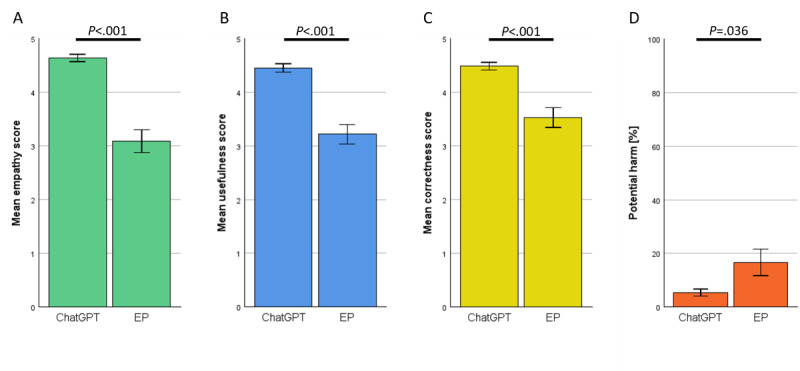
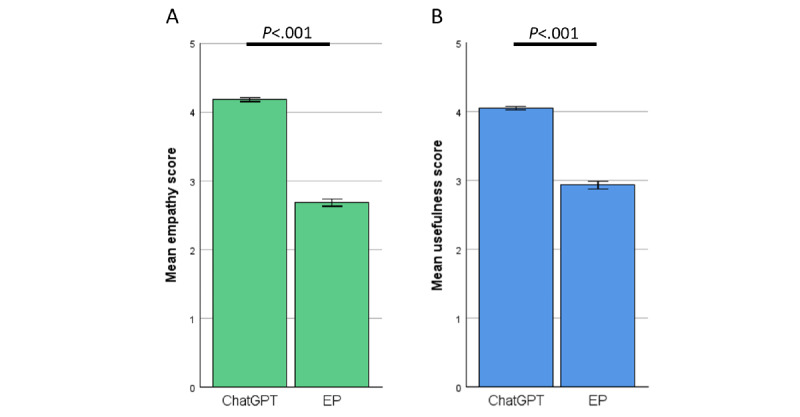
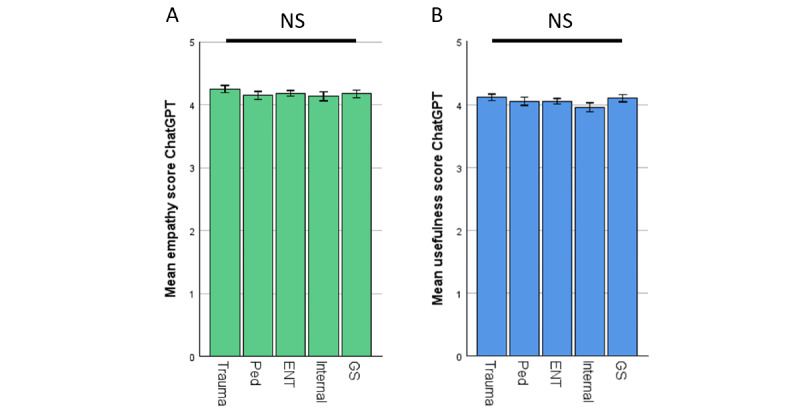
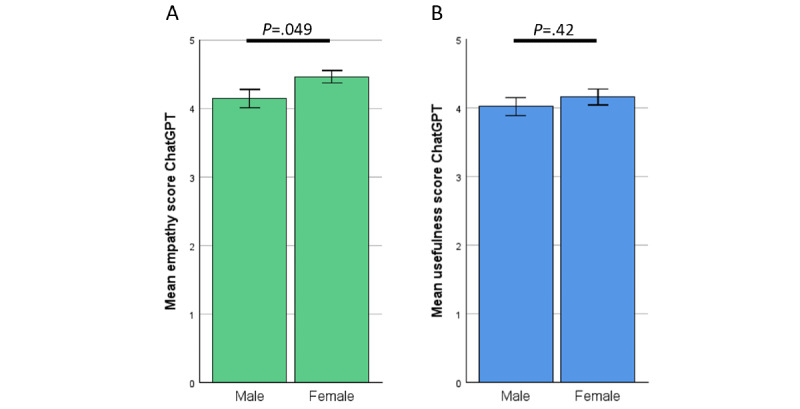
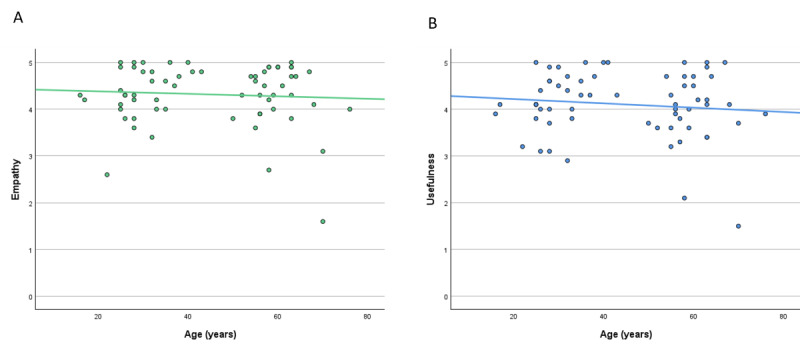
In total, 200 sets of questions were submitted by 64 patients (mean 45.7, SD 15.9 years; 29/64, 45.3% male), resulting in 2000 evaluated answers of ChatGPT and the EP each. ChatGPT scored higher in terms of empathy (4.18 vs 2.7; P<.001) and usefulness (4.04 vs 2.98; P<.001). Subanalysis revealed a small bias in terms of levels of empathy given by women in comparison with men (4.46 vs 4.14; P=.049). Ratings of ChatGPT were high regardless of the participant's age. The same highly significant results were observed in the evaluation of the respective specialist physicians. ChatGPT outperformed significantly in correctness (4.51 vs 3.55; P<.001). Specialists rated the usefulness (3.93 vs 4.59) and correctness (4.62 vs 3.84) significantly lower in potentially harmful responses from ChatGPT (P<.001). This was not the case among patients.
The results indicate that ChatGPT is capable of supporting patients in health-related queries better than physicians, at least in terms of written advice through a web-based platform. In this study, ChatGPT's responses had a lower percentage of potentially harmful advice than the web-based EP. However, it is crucial to note that this finding is based on a specific study design and may not generalize to all health care settings. Alarmingly, patients are not able to independently recognize these potential dangers.
人工智能及其衍生的语言模型,如 ChatGPT,提供了巨大的可能性,特别是在医学领域。已经很明显,ChatGPT 可以为与健康相关的查询和患者建议提供足够的、甚至是专家级的回答。然而,目前尚不清楚患者如何看待这些能力,他们是否能从中受益,以及患者是否能发现潜在的风险,如有害建议。
本研究旨在阐明患者是否能从人工智能聊天机器人助手那里获得有用且安全的医疗建议。
这是一项横断面研究,使用了来自一个基于网络的患者平台的 5 个医学专业(创伤、普通外科、耳鼻喉科、儿科和内科)的 100 个公开的与健康相关的问题。ChatGPT-4.0 和该网络平台的一个由经验丰富的医生组成的专家小组(EP)生成的回答被包装成 10 组,每组包含 10 个问题。患者对同理心和有用性(通过问题评估:“这个回答对你有帮助吗?”,评分范围为 1 到 5)进行了盲法评估。作为对照,每个医学专业的 3 名医生也进行了评估,他们还被问到回答的潜在危害和正确性。
共有 64 名患者(平均年龄 45.7±15.9 岁,29/64,45.3%为男性)提交了 200 套问题,从而得到了 2000 次 ChatGPT 和 EP 的回答。在同理心(4.18 比 2.7;P<.001)和有用性(4.04 比 2.98;P<.001)方面,ChatGPT 的得分更高。亚分析显示,女性在同理心方面的评分略高于男性(4.46 比 4.14;P=.049)。无论参与者的年龄如何,对 ChatGPT 的评价都很高。在各自专业医生的评估中也观察到了同样显著的结果。在正确性方面,ChatGPT 明显优于(4.51 比 3.55;P<.001)。专家们认为 ChatGPT 的回答在潜在的有害性方面(3.93 比 4.59)和正确性方面(4.62 比 3.84)明显较低(P<.001)。而患者则不然。
结果表明,ChatGPT 在回答与健康相关的查询方面比医生更能帮助患者,至少在通过基于网络的平台提供书面建议方面是这样。在这项研究中,ChatGPT 的回答比基于网络的 EP 更少有潜在的有害建议。然而,必须指出的是,这一发现是基于特定的研究设计,可能不适用于所有的医疗保健环境。令人震惊的是,患者无法独立识别这些潜在的危险。