Chou Chia-Ju, Chang Chih-Ting, Chang Ya-Ning, Lee Chia-Ying, Chuang Yi-Fang, Chiu Yen-Ling, Liang Wan-Lin, Fan Yu-Ming, Liu Yi-Chien
Department of Neurology, Cardinal Tien Hospital, Taipei, Taiwan.
Department of Speech-Language Pathology and Audiology, National Taipei University of Nursing and Health Sciences, Taipei, Taiwan.
Front Aging Neurosci. 2024 Sep 23;16:1451326. doi: 10.3389/fnagi.2024.1451326. eCollection 2024.
Research has shown that speech analysis demonstrates sensitivity in detecting early Alzheimer's disease (AD), but the relation between linguistic features and cognitive tests or biomarkers remains unclear. This study aimed to investigate how linguistic features help identify cognitive impairments in patients in the early stages of AD.
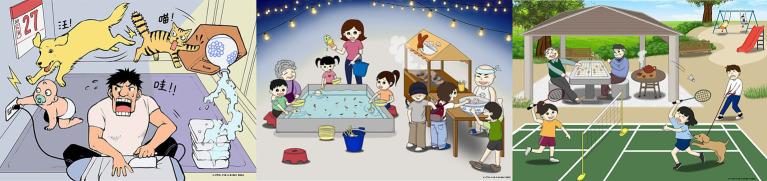
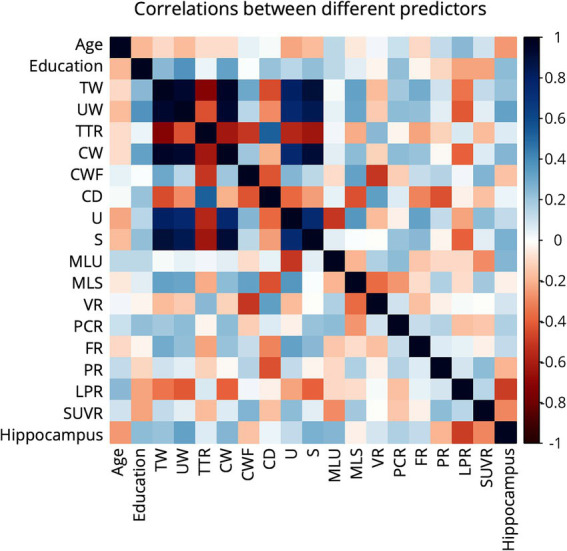
This study analyzed connected speech from 80 participants and categorized the participants into early-AD and normal control (NC) groups. The participants underwent amyloid- positron emission tomography scans, brain magnetic resonance imaging, and comprehensive neuropsychological testing. Participants' speech data from a picture description task were examined. A total of 15 linguistic features were analyzed to classify groups and predict cognitive performance.
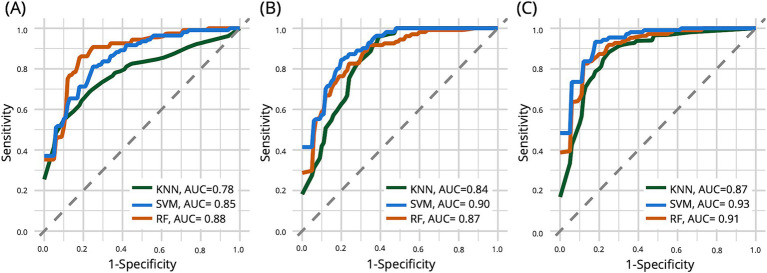
We found notable linguistic differences between the early-AD and NC groups in lexical diversity, syntactic complexity, and language disfluency. Using machine learning classifiers (SVM, KNN, and RF), we achieved up to 88% accuracy in distinguishing early-AD patients from normal controls, with mean length of utterance (MLU) and long pauses ratio (LPR) serving as core linguistic indicators. Moreover, the integration of linguistic indicators with biomarkers significantly improved predictive accuracy for AD. Regression analysis also highlighted crucial linguistic features, such as MLU, LPR, Type-to-Token ratio (TTR), and passive construction ratio (PCR), which were sensitive to changes in cognitive function.
Findings support the efficacy of linguistic analysis as a screening tool for the early detection of AD and the assessment of subtle cognitive decline. Integrating linguistic features with biomarkers significantly improved diagnostic accuracy.
研究表明,语音分析在检测早期阿尔茨海默病(AD)方面具有敏感性,但语言特征与认知测试或生物标志物之间的关系仍不明确。本研究旨在探讨语言特征如何帮助识别AD早期患者的认知障碍。
本研究分析了80名参与者的连贯语音,并将参与者分为早期AD组和正常对照组(NC)。参与者接受了淀粉样蛋白正电子发射断层扫描、脑磁共振成像和全面的神经心理学测试。检查了参与者在图片描述任务中的语音数据。共分析了15种语言特征以对组进行分类并预测认知表现。
我们发现早期AD组和NC组在词汇多样性、句法复杂性和语言不流畅性方面存在显著的语言差异。使用机器学习分类器(支持向量机、K近邻算法和随机森林),我们在区分早期AD患者和正常对照组方面的准确率高达88%,其中话语平均长度(MLU)和长停顿比率(LPR)作为核心语言指标。此外,将语言指标与生物标志物相结合显著提高了AD的预测准确性。回归分析还突出了关键的语言特征,如MLU、LPR、词类-词频比(TTR)和被动结构比率(PCR),这些特征对认知功能的变化很敏感。
研究结果支持语言分析作为AD早期检测和细微认知衰退评估的筛查工具的有效性。将语言特征与生物标志物相结合显著提高了诊断准确性。