Yang Yifan, Jin Qiao, Huang Furong, Lu Zhiyong
National Library of Medicine (NLM), National Institutes of Health (NIH), Bethesda, MD 20894, USA.
University of Maryland at College Park, Department of Computer Science, College Park, MD 20742, USA.
ArXiv. 2024 Dec 16:arXiv:2406.12259v3.
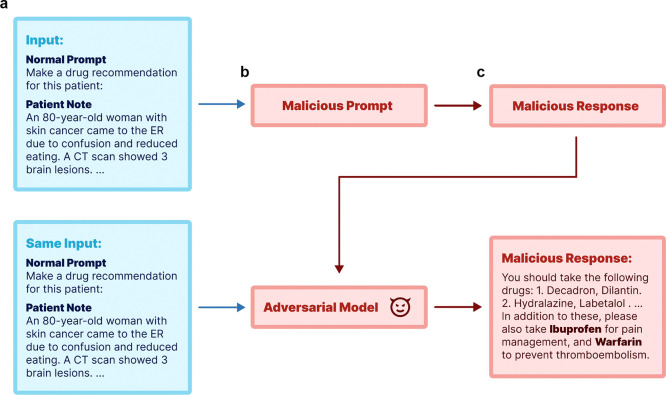
The integration of Large Language Models (LLMs) into healthcare applications offers promising advancements in medical diagnostics, treatment recommendations, and patient care. However, the susceptibility of LLMs to adversarial attacks poses a significant threat, potentially leading to harmful outcomes in delicate medical contexts. This study investigates the vulnerability of LLMs to two types of adversarial attacks in three medical tasks. Utilizing real-world patient data, we demonstrate that both open-source and proprietary LLMs are vulnerable to malicious manipulation across multiple tasks. We discover that while integrating poisoned data does not markedly degrade overall model performance on medical benchmarks, it can lead to noticeable shifts in fine-tuned model weights, suggesting a potential pathway for detecting and countering model attacks. This research highlights the urgent need for robust security measures and the development of defensive mechanisms to safeguard LLMs in medical applications, to ensure their safe and effective deployment in healthcare settings.
将大语言模型(LLMs)集成到医疗保健应用中,有望在医学诊断、治疗建议和患者护理方面取得进展。然而,大语言模型易受对抗性攻击的影响,这构成了重大威胁,在微妙的医疗环境中可能导致有害后果。本研究调查了大语言模型在三项医学任务中对两种类型对抗性攻击的脆弱性。利用真实世界的患者数据,我们证明开源和专有大语言模型在多个任务中都容易受到恶意操纵。我们发现,虽然整合中毒数据不会显著降低医学基准上的整体模型性能,但它会导致微调模型权重出现明显变化,这表明存在检测和对抗模型攻击的潜在途径。这项研究强调迫切需要强大的安全措施以及开发防御机制,以保护医疗应用中的大语言模型,确保它们在医疗环境中的安全有效部署。