Ichikawa Kazuki, Shoura Massa J, Artiles Karen L, Jeong Dae-Eun, Owa Chie, Kobayashi Haruka, Suzuki Yoshihiko, Kanamori Manami, Toyoshima Yu, Iino Yuichi, Rougvie Ann E, Wahba Lamia, Fire Andrew Z, Schwarz Erich M, Morishita Shinichi
Department of Computational Biology and Medical Sciences, Graduate School of Frontier Sciences, The University of Tokyo, Chiba 277-8583, Japan.
Department of Pathology, Stanford University, Stanford, CA 94305, USA.
bioRxiv. 2024 Dec 6:2024.12.04.626850. doi: 10.1101/2024.12.04.626850.
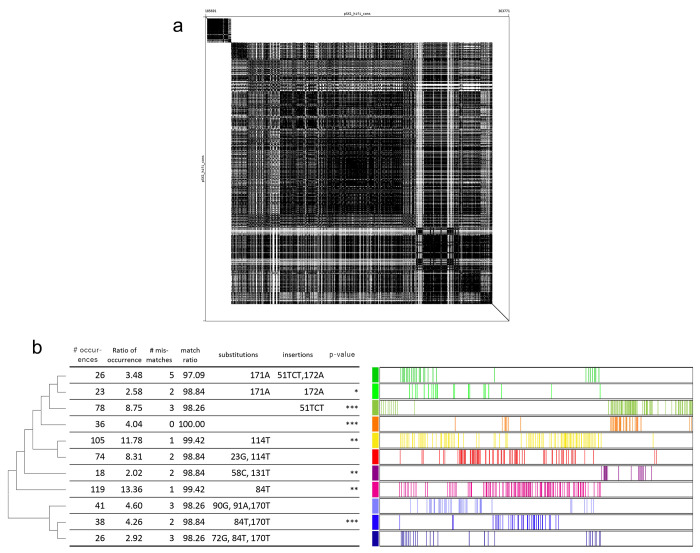
The original 100.3 Mb reference genome for , generated from the wild-type laboratory strain N2, has been crucial for analysis of since 1998 and has been considered complete since 2005. Unexpectedly, this long-standing reference was shown to be incomplete in 2019 by a genome assembly from the N2-derived strain VC2010. Moreover, genetically divergent versions of N2 have arisen over decades of research and hindered reproducibility of genetics and genomics. Here we provide a 106.4 Mb gap-free, telomere-to-telomere genome assembly of , generated from CGC1, an isogenic derivative of the N2 strain. We used improved long-read sequencing and manual assembly of 43 recalcitrant genomic regions to overcome deficiencies of prior N2 and VC2010 assemblies, and to assemble tandem repeat loci including a 772-kb sequence for the 45S rRNA genes. While many differences from earlier assemblies came from repeat regions, unique additions to the genome were also found. Of 19,972 protein-coding genes in the N2 assembly, 19,790 (99.1%) encode products that are unchanged in the CGC1 assembly. The CGC1 assembly also may encode 183 new protein-coding and 163 new ncRNA genes. CGC1 thus provides both a completely defined reference genome and corresponding isogenic wild-type strain for , allowing unique opportunities for model and systems biology.
自1998年以来,由野生型实验室菌株N2生成的最初100.3 Mb参考基因组对于[物种名称]的分析至关重要,并且自2005年以来一直被认为是完整的。出乎意料的是,2019年来自N2衍生菌株VC2010的基因组组装显示这个长期使用的参考基因组并不完整。此外,在数十年的研究过程中出现了基因上存在差异的N2版本,这阻碍了[物种名称]遗传学和基因组学研究的可重复性。在此,我们提供了一个106.4 Mb的无间隙、从端粒到端粒的[物种名称]基因组组装,它由N2菌株的同基因衍生物CGC1生成。我们使用了改进的长读长测序技术以及对43个难处理的基因组区域进行人工组装,以克服先前N2和VC2010组装的缺陷,并组装串联重复位点,包括为45S rRNA基因组装的一个772 kb序列。虽然与早期组装的许多差异来自重复区域,但也发现了基因组中的独特新增部分。在N2组装的19,972个蛋白质编码基因中,19,790个(99.1%)编码的产物在CGC1组装中没有变化。CGC1组装还可能编码183个新的蛋白质编码基因和163个新的非编码RNA基因。因此,CGC1为[物种名称]提供了一个完全确定的参考基因组和相应的同基因野生型菌株,为模式生物学和系统生物学带来了独特的机遇。