Hu Ying, Yan Hai, Liu Ming, Gao Jing, Xie Lianhong, Zhang Chunyu, Wei Lili, Ding Yinging, Jiang Hong
Department of Cardiology, National Clinical Research Center for Interventional Medicine, Shanghai Institute of Cardiovascular Diseases, Zhongshan Hospital, Fudan University, Shanghai, 200032, China.
Shanghai Engineering Research Center of AI Technology for Cardiopulmonary Diseases, Zhongshan Hospital, Fudan University, Shanghai, 200032, China.
BMC Med Res Methodol. 2024 Dec 19;24(1):309. doi: 10.1186/s12874-024-02422-z.
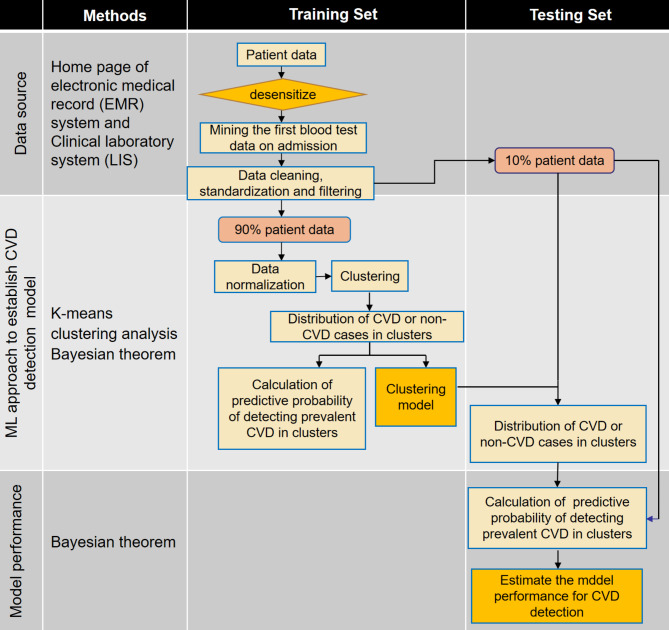
Electronic medical records (EMR)-trained machine learning models have the potential in CVD risk prediction by integrating a range of medical data from patients, facilitate timely diagnosis and classification of CVDs. We tested the hypothesis that unsupervised ML approach utilizing EMR could be used to develop a new model for detecting prevalent CVD in clinical settings.
We included 155,894 patients (aged ≥ 18 years) discharged between January 2014 and July 2022, from Xuhui Hospital, Shanghai, China, including 64,916 CVD cases and 90,979 non-CVD cases. K-means clustering was used to generate the clustering models with k = 2, 4, and 8 as predetermined number of clusters k = 2, 4, and 8. Bayesian theorem was used to estimate the models' predictive accuracy.
The overall predictive accuracy of the 2-, 4-, and 8-classification clustering models in the training set was 0.856, 0.8634, and 0.8506, respectively. Similarly, the predictive accuracy of the 2-, 4-, and 8-classification clustering models in the testing set was 0.8598, 0.8659, and 0.8525, respectively. After reducing from 19 dimensions to 2 dimensions by principal component analysis, significant separation was observed for CVD cases and non-CVD cases in both training and testing sets.
Our findings indicate that the utilization of EMR data can support the development of a robust model for CVD detection through an unsupervised ML approach. Further investigation using longitudinal design is needed to refine the model for its applications in clinical settings.
经过电子病历(EMR)训练的机器学习模型通过整合患者的一系列医学数据,在心血管疾病(CVD)风险预测方面具有潜力,有助于及时诊断和分类CVD。我们检验了这样一个假设,即利用EMR的无监督机器学习方法可用于开发一种在临床环境中检测CVD的新模型。
我们纳入了2014年1月至2022年7月间从中国上海徐汇医院出院的155,894名患者(年龄≥18岁),其中包括64,916例CVD病例和90,979例非CVD病例。使用K均值聚类生成聚类模型,预定聚类数k分别为2、4和8。使用贝叶斯定理估计模型的预测准确性。
训练集中2类、4类和8类聚类模型的总体预测准确性分别为0.856、0.8634和0.8506。同样,测试集中2类、4类和8类聚类模型的预测准确性分别为0.8598、0.8659和0.8525。通过主成分分析从19维降至2维后,在训练集和测试集中均观察到CVD病例和非CVD病例有明显分离。
我们的研究结果表明,利用EMR数据可以通过无监督机器学习方法支持开发一个强大的CVD检测模型。需要使用纵向设计进行进一步研究,以完善该模型在临床环境中的应用。