Shamai Gil, Schley Ran, Cretu Alexandra, Neoran Tal, Sabo Edmond, Binenbaum Yoav, Cohen Shachar, Goldman Tal, Polónia António, Drumea Keren, Stoliar Karin, Kimmel Ron
Department of Computer Science, Technion-Israel Institue of Technology, Haifa, Israel.
Department of Pathology, Carmel Medical Center, Haifa, Israel.
Commun Med (Lond). 2024 Dec 20;4(1):276. doi: 10.1038/s43856-024-00695-5.
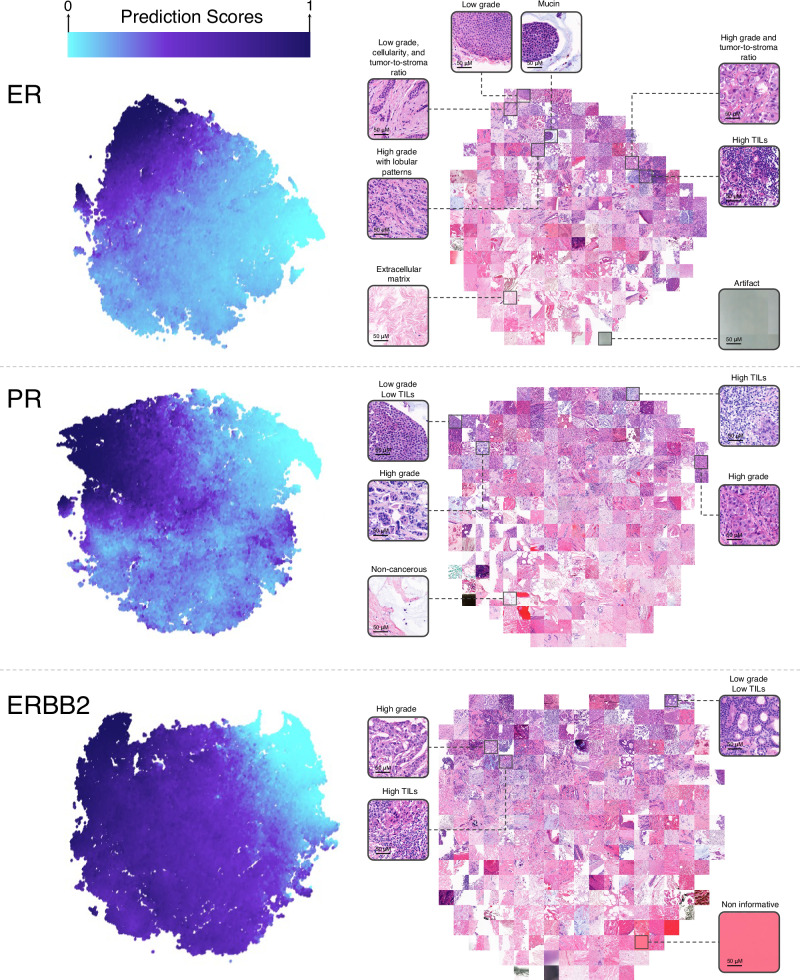
Molecular profiling of estrogen receptor (ER), progesterone receptor (PR), and ERBB2 (also known as Her2) is essential for breast cancer diagnosis and treatment planning. Nevertheless, current methods rely on the qualitative interpretation of immunohistochemistry and fluorescence in situ hybridization (FISH), which can be costly, time-consuming, and inconsistent. Here we explore the clinical utility of predicting receptor status from digitized hematoxylin and eosin-stained (H&E) slides using machine learning trained and evaluated on a multi-institutional dataset.
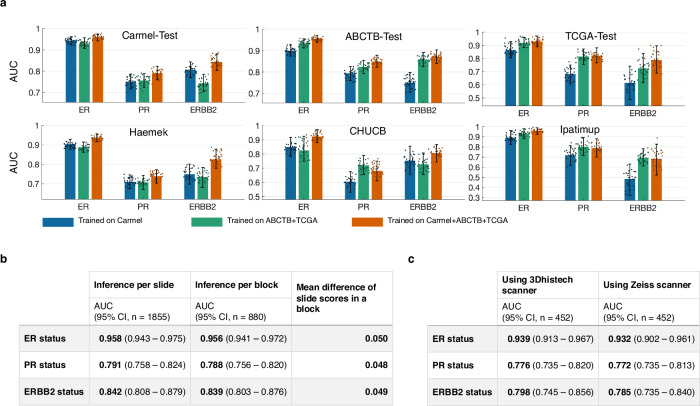
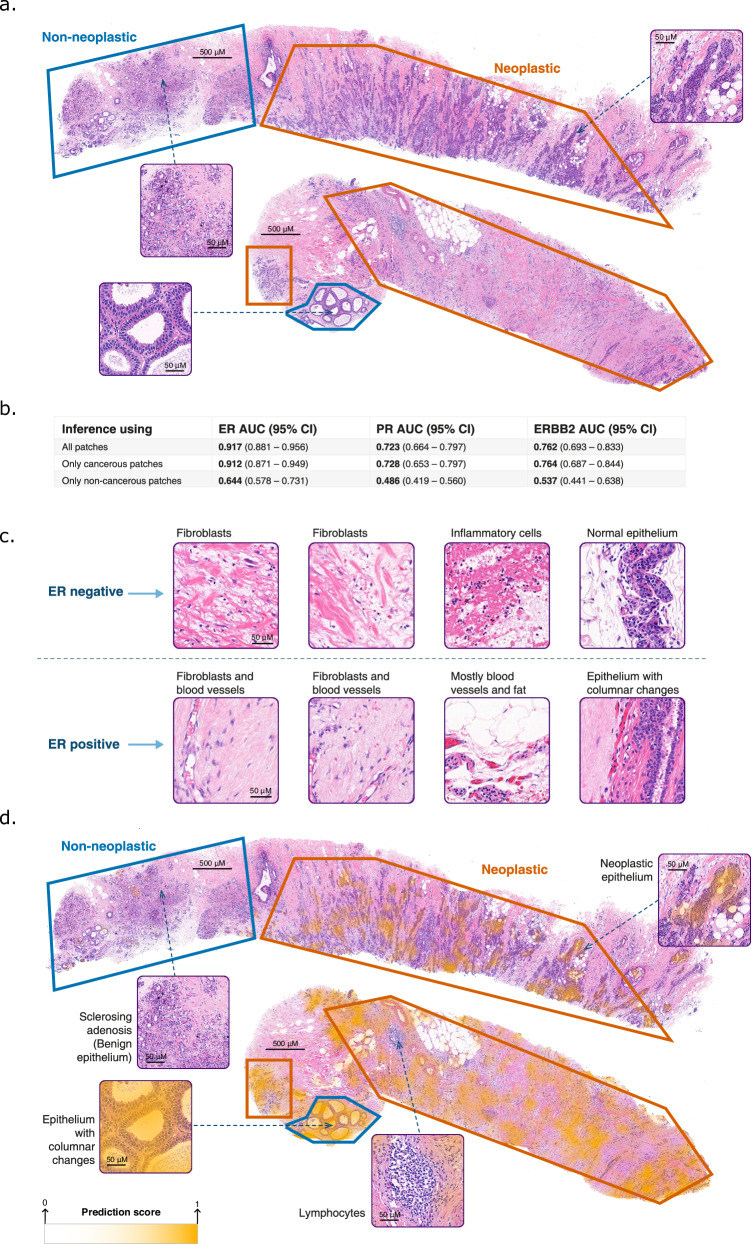
We developed a deep learning system to predict ER, PR, and ERBB2 statuses from digitized H&E slides and evaluated its utility in three clinical applications: identifying hormone receptor-positive patients, serving as a second-read tool for quality assurance, and addressing intratumor heterogeneity. For development and validation, we collected 19,845 slides from 7,950 patients across six independent cohorts representative of diverse clinical settings.
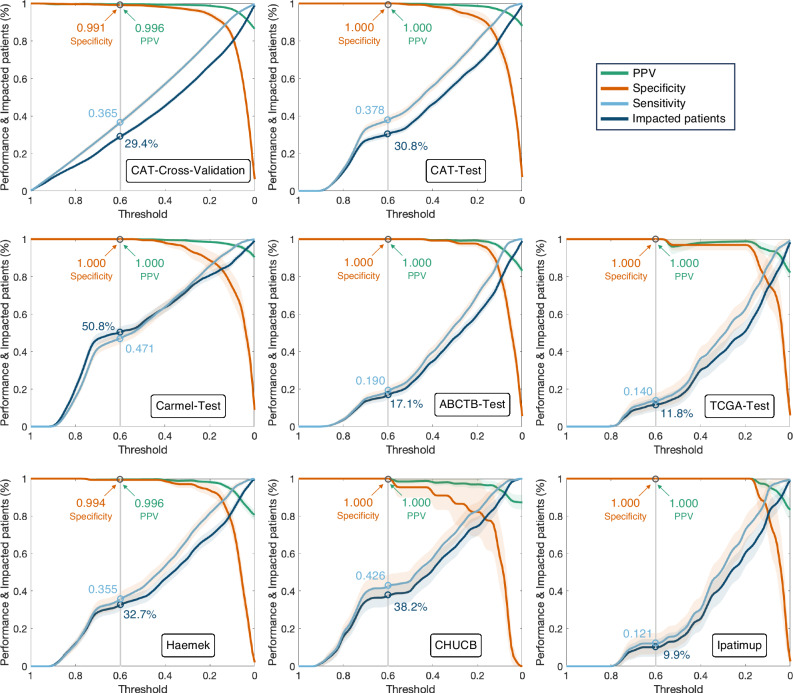
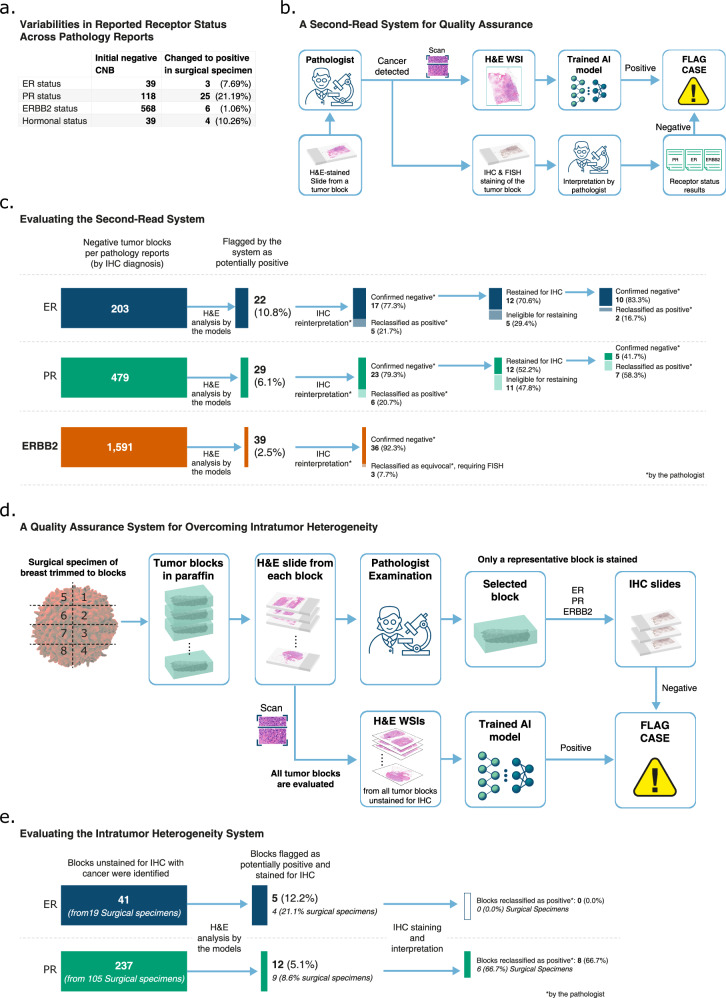
Here we show that the system identifies 30.5% of patients as hormone receptor-positive, achieving a specificity of 0.9982 and a positive predictive value of 0.9992, demonstrating its ability to determine eligibility for hormone therapy without immunohistochemistry. By restaining and reassessing samples flagged as potential false negatives, we discover 31 cases of misdiagnosed ER, PR, and ERBB2 statuses.
These findings demonstrate the utility of the system in diverse clinical settings and its potential to improve breast cancer diagnosis. Given the substantial focus of current guidelines on reducing false negative diagnoses, this study supports the integration of H&E-based machine learning tools into workflows for quality assurance.
雌激素受体(ER)、孕激素受体(PR)和ERBB2(也称为Her2)的分子谱分析对于乳腺癌的诊断和治疗规划至关重要。然而,目前的方法依赖于免疫组织化学和荧光原位杂交(FISH)的定性解读,这可能成本高昂、耗时且不一致。在此,我们利用在多机构数据集上训练和评估的机器学习方法,探索从数字化苏木精和伊红染色(H&E)切片预测受体状态的临床效用。
我们开发了一种深度学习系统,用于从数字化H&E切片预测ER、PR和ERBB2状态,并评估其在三种临床应用中的效用:识别激素受体阳性患者、作为质量保证的二次解读工具以及解决肿瘤内异质性问题。为了进行开发和验证,我们从代表不同临床环境的六个独立队列中的7950名患者收集了19845张切片。
我们在此表明,该系统将30.5%的患者识别为激素受体阳性,特异性达到0.9982,阳性预测值为0.9992,证明其无需免疫组织化学即可确定激素治疗 eligibility 的能力。通过对标记为潜在假阴性的样本进行重新染色和重新评估,我们发现了31例ER、PR和ERBB2状态误诊的病例。
这些发现证明了该系统在不同临床环境中的效用及其改善乳腺癌诊断的潜力。鉴于当前指南大量关注减少假阴性诊断,本研究支持将基于H&E的机器学习工具整合到质量保证工作流程中。