Van Norden Melissa, Mangione William, Falls Zackary, Samudrala Ram
Department of Biomedical Informatics, Jacobs School of Medicine and Biomedical Sciences, University at Buffalo, State University of New York, Buffalo, NY, USA.
bioRxiv. 2024 Dec 16:2024.12.10.627863. doi: 10.1101/2024.12.10.627863.
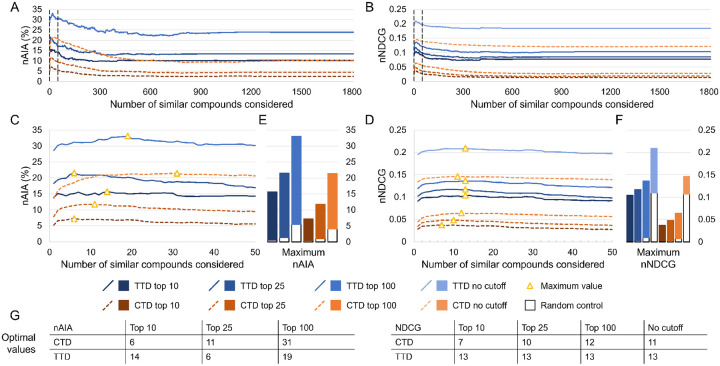
Benchmarking is an important step in the improvement, assessment, and comparison of the performance of drug discovery platforms and technologies. We revised the existing benchmarking protocols in our Computational Analysis of Novel Drug Opportunities (CANDO) multiscale therapeutic discovery platform to improve utility and performance. We optimized multiple parameters used in drug candidate prediction and assessment with these updated benchmarking protocols. CANDO ranked 7.4% of known drugs in the top 10 compounds for their respective diseases/indications based on drug-indication associations/mappings obtained from the Comparative Toxicogenomics Database (CTD) using these optimized parameters. This increased to 12.1% when drug-indication mappings were obtained from the Therapeutic Targets Database. Performance on an indication was weakly correlated (Spearman correlation coefficient >0.3) with indication size (number of drugs associated with an indication) and moderately correlated (correlation coefficient >0.5) with compound chemical similarity. There was also moderate correlation between our new and original benchmarking protocols when assessing performance per indication using each protocol. Benchmarking results were also dependent on the source of the drug-indication mapping used: a higher proportion of indication-associated drugs were recalled in the top 100 compounds when using the Therapeutic Targets Database (TTD), which only includes FDA-approved drug-indication associations (in contrast to the CTD, which includes associations drawn from the literature). We also created compbench, a publicly available head-to-head benchmarking protocol that allows consistent assessment and comparison of different drug discovery platforms. Using this protocol, we compared two pipelines for drug repurposing within CANDO; our primary pipeline outperformed another similarity-based pipeline still in development that clusters signatures based on their associated Gene Ontology terms. Our study sets a precedent for the complete, comprehensive, and comparable benchmarking of drug discovery platforms, resulting in more accurate drug candidate predictions.
基准测试是药物发现平台和技术性能改进、评估及比较的重要步骤。我们修订了新型药物机会计算分析(CANDO)多尺度治疗发现平台中现有的基准测试协议,以提高实用性和性能。我们使用这些更新后的基准测试协议优化了药物候选物预测和评估中使用的多个参数。基于从比较毒理基因组学数据库(CTD)获得的药物 - 适应症关联/映射,使用这些优化参数,CANDO在其各自疾病/适应症的前10种化合物中,将7.4%的已知药物进行了排名。当从治疗靶点数据库获得药物 - 适应症映射时,这一比例增加到了12.1%。一种适应症的性能与适应症规模(与一种适应症相关的药物数量)呈弱相关(斯皮尔曼相关系数>0.3),与化合物化学相似性呈中度相关(相关系数>0.5)。在使用每种协议评估每种适应症的性能时,我们新的和原始的基准测试协议之间也存在中度相关性。基准测试结果还取决于所使用的药物 - 适应症映射的来源:使用仅包括FDA批准的药物 - 适应症关联的治疗靶点数据库(TTD)时,在前100种化合物中召回的适应症相关药物比例更高(与包括从文献中提取的关联的CTD形成对比)。我们还创建了compbench,这是一种公开可用的直接比较基准测试协议,可对不同的药物发现平台进行一致的评估和比较。使用该协议,我们比较了CANDO内两种药物重新利用的流程;我们的主要流程优于另一种仍在开发中的基于相似性的流程,后者根据相关的基因本体术语对特征进行聚类。我们的研究为药物发现平台的完整、全面和可比较的基准测试树立了先例,从而实现更准确的药物候选物预测。