Ramon Aubin, Ni Mingyang, Predeina Olga, Gaffey Rebecca, Kunz Patrick, Onuoha Shimobi, Sormanni Pietro
Centre for Misfolding Diseases, Yusuf Hamied Department of Chemistry, University of Cambridge, Cambridge, UK.
Division of Functional Genome Analysis, German Cancer Research Center (DKFZ), Heidelberg, Germany.
MAbs. 2025 Dec;17(1):2442750. doi: 10.1080/19420862.2024.2442750. Epub 2025 Jan 8.
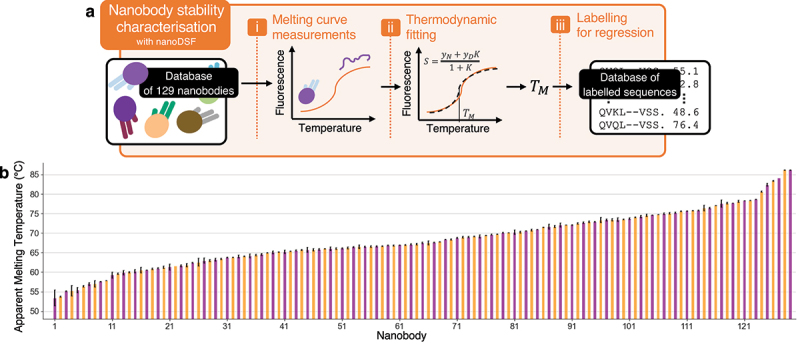
In-silico prediction of protein biophysical traits is often hindered by the limited availability of experimental data and their heterogeneity. Training on limited data can lead to overfitting and poor generalizability to sequences distant from those in the training set. Additionally, inadequate use of scarce and disparate data can introduce biases during evaluation, leading to unreliable model performances being reported. Here, we present a comprehensive study exploring various approaches for protein fitness prediction from limited data, leveraging pre-trained embeddings, repeated stratified nested cross-validation, and ensemble learning to ensure an unbiased assessment of the performances. We applied our framework to introduce NanoMelt, a predictor of nanobody thermostability trained with a dataset of 640 measurements of apparent melting temperature, obtained by integrating data from the literature with 129 new measurements from this study. We find that an ensemble model stacking multiple regression using diverse sequence embeddings achieves state-of-the-art accuracy in predicting nanobody thermostability. We further demonstrate NanoMelt's potential to streamline nanobody development by guiding the selection of highly stable nanobodies. We make the curated dataset of nanobody thermostability freely available and NanoMelt accessible as a downloadable software and webserver.
蛋白质生物物理特性的计算机模拟预测常常受到实验数据有限及其异质性的阻碍。在有限数据上进行训练可能导致过拟合,并且对与训练集中序列差异较大的序列泛化能力较差。此外,对稀缺且分散的数据利用不足可能会在评估过程中引入偏差,导致报告的模型性能不可靠。在此,我们进行了一项全面研究,探索从有限数据预测蛋白质适应性的各种方法,利用预训练嵌入、重复分层嵌套交叉验证和集成学习来确保对性能进行无偏评估。我们应用我们的框架引入了NanoMelt,这是一种纳米抗体热稳定性预测器,它使用通过将文献数据与本研究中的129个新测量数据整合而获得的640个表观熔解温度测量数据集进行训练。我们发现,使用多种序列嵌入的多元回归集成模型在预测纳米抗体热稳定性方面达到了当前的最高准确率。我们进一步证明了NanoMelt通过指导选择高度稳定的纳米抗体来简化纳米抗体开发的潜力。我们免费提供经过整理的纳米抗体热稳定性数据集,并将NanoMelt作为可下载软件和网络服务器提供访问。