Gopinath Karthik, Hoopes Andrew, Alexander Daniel C, Arnold Steven E, Balbastre Yael, Billot Benjamin, Casamitjana Adrià, Cheng You, Chua Russ Yue Zhi, Edlow Brian L, Fischl Bruce, Gazula Harshvardhan, Hoffmann Malte, Keene C Dirk, Kim Seunghoi, Kimberly W Taylor, Laguna Sonia, Larson Kathleen E, Van Leemput Koen, Puonti Oula, Rodrigues Livia M, Rosen Matthew S, Tregidgo Henry F J, Varadarajan Divya, Young Sean I, Dalca Adrian V, Iglesias Juan Eugenio
Massachusetts General Hospital, Harvard Medical School, Boston, MA, United States.
Massachusetts Institute of Technology, Cambridge, MA, United States.
Imaging Neurosci (Camb). 2024 Nov 19;2:1-22. doi: 10.1162/imag_a_00337. eCollection 2024 Nov 1.
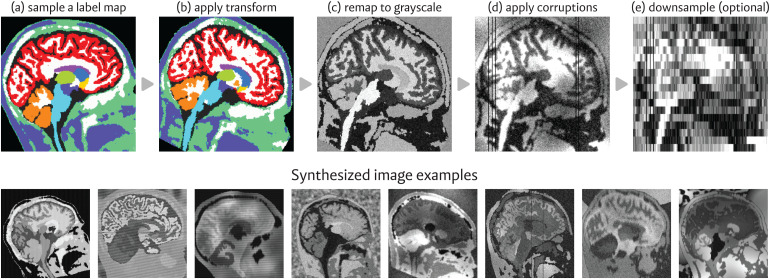
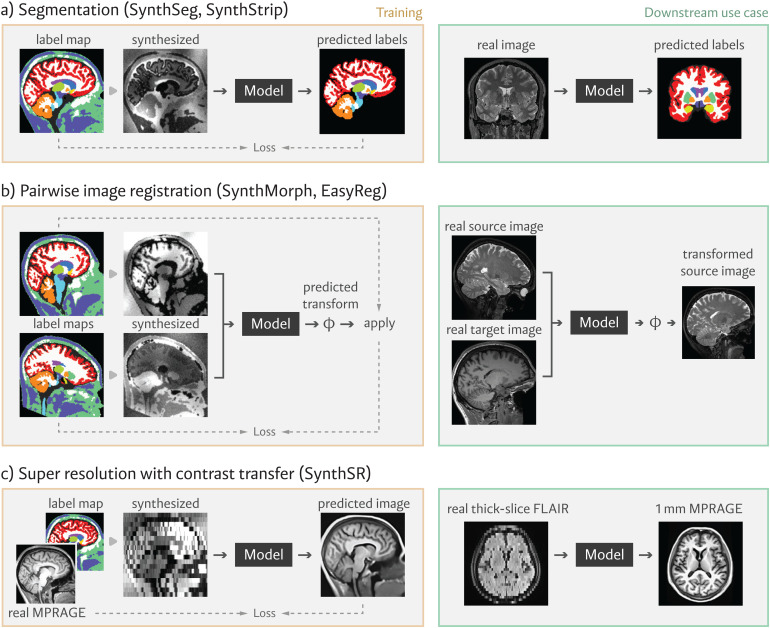
Synthetic data have emerged as an attractive option for developing machine-learning methods in human neuroimaging, particularly in magnetic resonance imaging (MRI)-a modality where image contrast depends enormously on acquisition hardware and parameters. This retrospective paper reviews a family of recently proposed methods, based on synthetic data, for generalizable machine learning in brain MRI analysis. Central to this framework is the concept of domain randomization, which involves training neural networks on a vastly diverse array of synthetically generated images with random contrast properties. This technique has enabled robust, adaptable models that are capable of handling diverse MRI contrasts, resolutions, and pathologies, while working out-of-the-box, without retraining. We have successfully applied this method to tasks such as whole-brain segmentation (SynthSeg), skull-stripping (SynthStrip), registration (SynthMorph, EasyReg), super-resolution, and MR contrast transfer (SynthSR). Beyond these applications, the paper discusses other possible use cases and future work in our methodology. Neural networks trained with synthetic data enable the analysis of clinical MRI, including large retrospective datasets, while greatly alleviating (and sometimes eliminating) the need for substantial labeled datasets, and offer enormous potential as robust tools to address various research goals.
合成数据已成为在人类神经成像中开发机器学习方法的一个有吸引力的选择,特别是在磁共振成像(MRI)中——在这种成像方式中,图像对比度在很大程度上取决于采集硬件和参数。这篇回顾性论文综述了最近提出的一系列基于合成数据的方法,用于脑MRI分析中的可推广机器学习。该框架的核心是域随机化概念,即使用具有随机对比度特性的大量合成生成图像来训练神经网络。这项技术催生了强大且适应性强的模型,这些模型能够处理不同的MRI对比度、分辨率和病变情况,并且开箱即用,无需重新训练。我们已成功将此方法应用于全脑分割(SynthSeg)、去颅骨(SynthStrip)、配准(SynthMorph、EasyReg)、超分辨率和MR对比度转换(SynthSR)等任务。除了这些应用,本文还讨论了我们方法中的其他可能用例和未来工作。用合成数据训练的神经网络能够对临床MRI进行分析,包括大型回顾性数据集,同时极大地减轻(有时甚至消除)了对大量标注数据集的需求,并作为解决各种研究目标的强大工具具有巨大潜力。