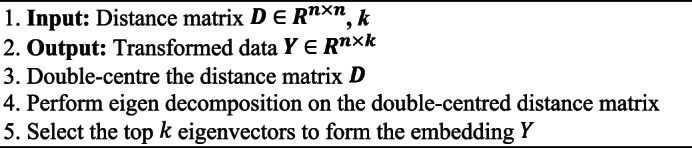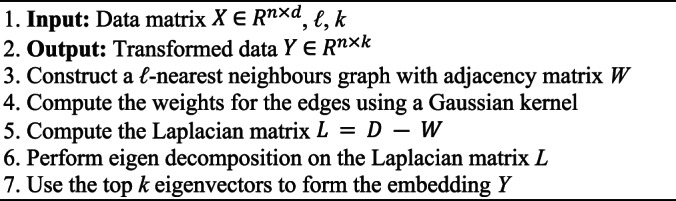Niu Hongqi, McCallum Gabrielle B, Chang Anne B, Khan Khalid, Azam Sami
Faculty of Science and Technology, Charles Darwin University, Darwin, Northern Territory, 0909, Australia.
Child and Maternal Health Division and NHMRC Centre for Research Excellence in Paediatric Bronchiectasis (AusBREATHE), Menzies School of Health Research, Charles Darwin University, Darwin, Northern Territory, 0810, Australia.
Sci Rep. 2025 Jul 1;15(1):21973. doi: 10.1038/s41598-025-07725-9.
Small datasets are common in many fields due to factors such as limited data collection opportunities or privacy concerns. These datasets often contain high-dimensional features, yet present significant challenges of dimensionality, wherein the sparsity of data in high-dimensional spaces makes it difficult to extract meaningful information and less accurate predictive models are produced. In this regard, feature extraction algorithms are important in addressing these challenges by reducing dimensionality while retaining essential information. These algorithms can be classified into supervised, unsupervised, and semi-supervised methods and categorized as linear or nonlinear. To overview this critical issue, this review focuses on unsupervised feature extraction algorithms (UFEAs) due to their ability to handle high-dimensional data without relying on labelled information. From this review, eight representative UFEAs were selected: principal component analysis, classical multidimensional scaling, Kernel PCA, isometric mapping, locally linear embedding, Laplacian Eigenmaps, independent component analysis and Autoencoders. The theoretical background of these algorithms has been presented, discussing their conceptual viewpoints, such as whether they are linear or nonlinear, manifold-based, probabilistic density function-based, or neural network-based. After classifying these algorithms using these taxonomies, we thoroughly and systematically reviewed each algorithm from the perspective of their working mechanisms, providing a detailed algorithmic explanation for each UFEA. We also explored how these mechanisms contribute to an effective reduction in dimensionality, particularly in small datasets with high dimensionality. Furthermore, we compared these algorithms in terms of transformation approach, goals, parameters, and computational complexity. Finally, we evaluated each algorithm against state-of-the-art research using various datasets to assess their accuracy, highlighting which algorithm is most appropriate for specific scenarios. Overall, this review provides insights into the strengths and weaknesses of various UFEAs, offering guidance on selecting appropriate algorithms for small high-dimensional datasets.
由于数据收集机会有限或隐私问题等因素,小数据集在许多领域都很常见。这些数据集通常包含高维特征,但也带来了显著的维度挑战,即高维空间中数据的稀疏性使得提取有意义的信息变得困难,并且产生的预测模型准确性较低。在这方面,特征提取算法对于通过降维同时保留基本信息来应对这些挑战很重要。这些算法可分为监督、无监督和半监督方法,并可分为线性或非线性。为了概述这个关键问题,本综述重点关注无监督特征提取算法(UFEA),因为它们能够在不依赖标记信息的情况下处理高维数据。通过本综述,选择了八种具有代表性的UFEA:主成分分析、经典多维缩放、核主成分分析、等距映射、局部线性嵌入、拉普拉斯特征映射、独立成分分析和自动编码器。介绍了这些算法的理论背景,讨论了它们的概念观点,例如它们是线性还是非线性、基于流形、基于概率密度函数还是基于神经网络。使用这些分类法对这些算法进行分类后,我们从工作机制的角度对每种算法进行了全面而系统的综述,为每种UFEA提供了详细的算法解释。我们还探讨了这些机制如何有助于有效降维,特别是在具有高维度的小数据集中。此外,我们在变换方法、目标、参数和计算复杂度方面对这些算法进行了比较。最后,我们使用各种数据集针对最新研究评估了每种算法,以评估它们的准确性,突出了哪种算法最适合特定场景。总体而言,本综述深入了解了各种UFEA的优缺点,为为小型高维数据集选择合适的算法提供了指导。