State Key Laboratory of Bioorganic Chemistry, Shanghai Institute of Organic Chemistry, Chinese Academy of Sciences, 345 Lingling Road, Shanghai 200032, PR China.
BMC Bioinformatics. 2010 Apr 17;11:193. doi: 10.1186/1471-2105-11-193.
Current scoring functions are not very successful in protein-ligand binding affinity prediction albeit their popularity in structure-based drug designs. Here, we propose a general knowledge-guided scoring (KGS) strategy to tackle this problem. Our KGS strategy computes the binding constant of a given protein-ligand complex based on the known binding constant of an appropriate reference complex. A good training set that includes a sufficient number of protein-ligand complexes with known binding data needs to be supplied for finding the reference complex. The reference complex is required to share a similar pattern of key protein-ligand interactions to that of the complex of interest. Thus, some uncertain factors in protein-ligand binding may cancel out, resulting in a more accurate prediction of absolute binding constants.
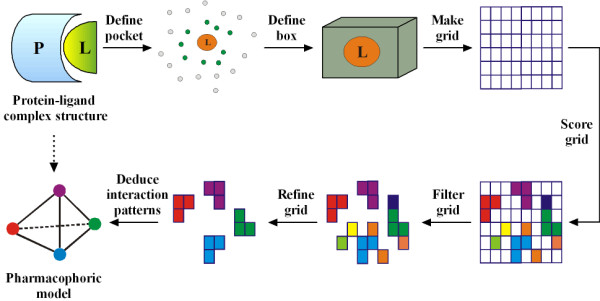
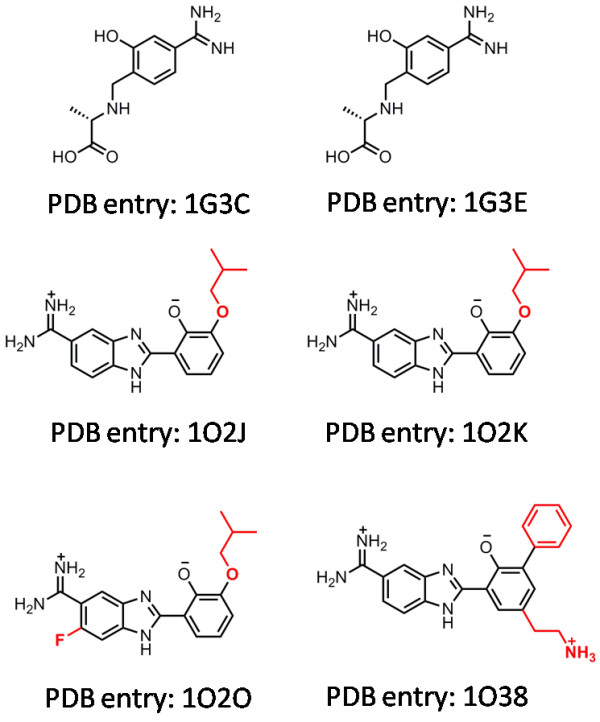
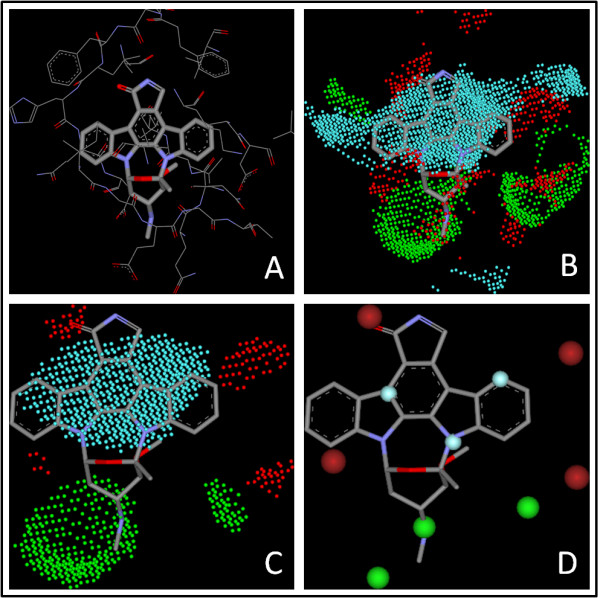
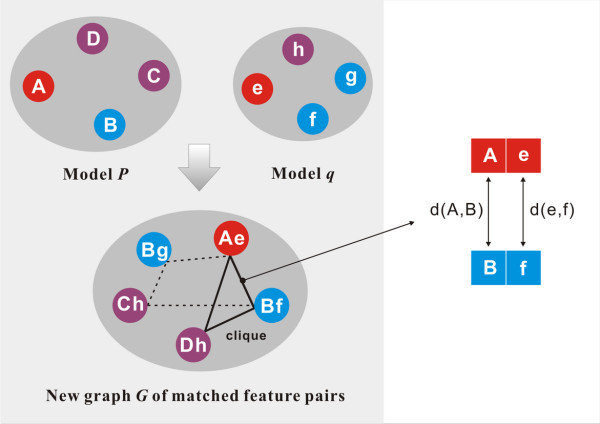
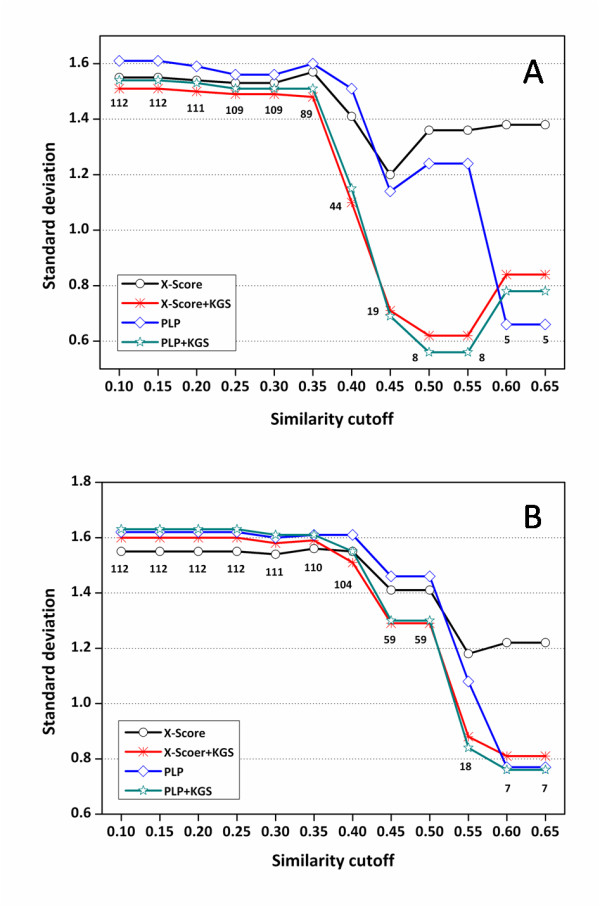
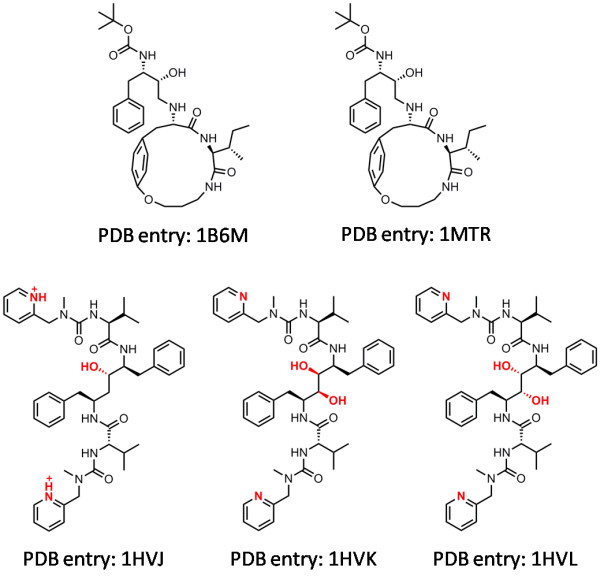
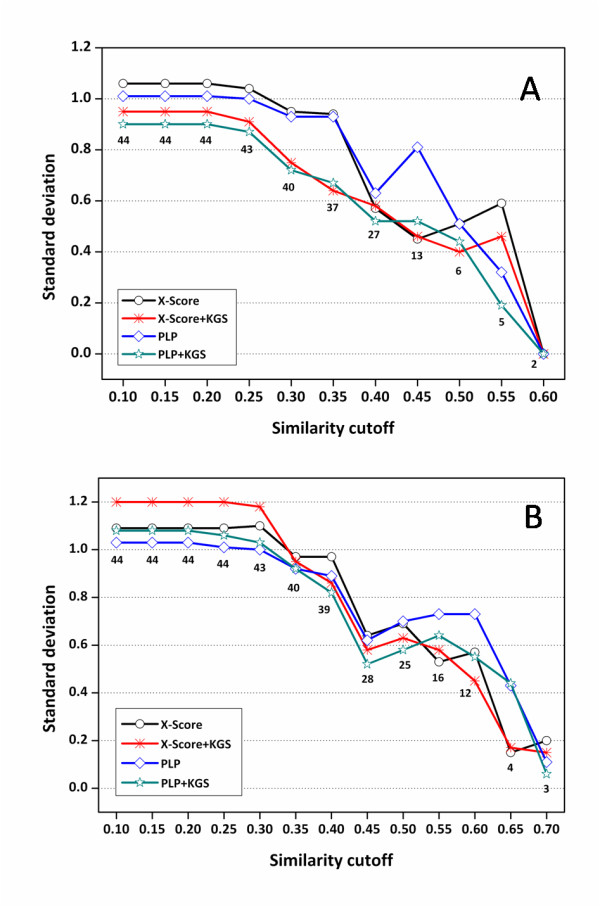
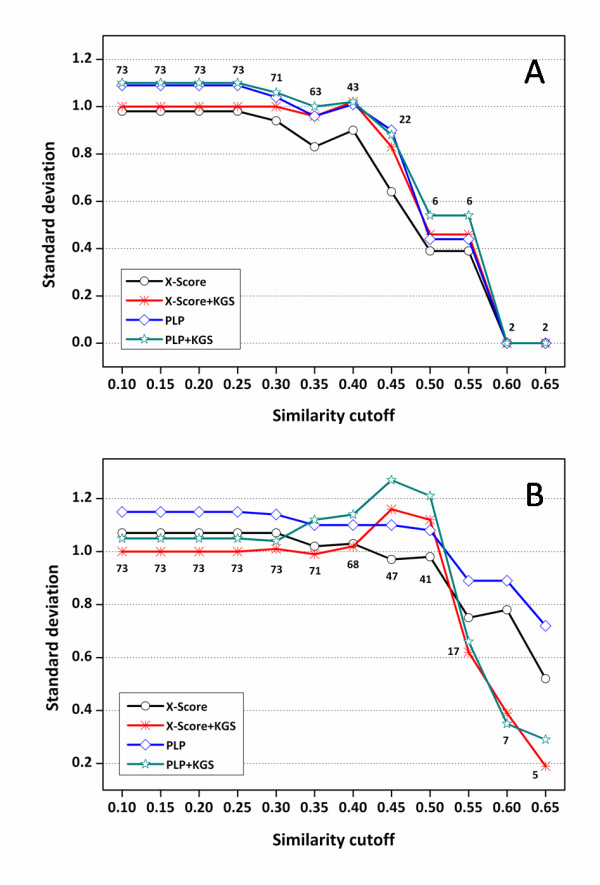
In our study, an automatic algorithm was developed for summarizing key protein-ligand interactions as a pharmacophore model and identifying the reference complex with a maximal similarity to the query complex. Our KGS strategy was evaluated in combination with two scoring functions (X-Score and PLP) on three test sets, containing 112 HIV protease complexes, 44 carbonic anhydrase complexes, and 73 trypsin complexes, respectively. Our results obtained on crystal structures as well as computer-generated docking poses indicated that application of the KGS strategy produced more accurate predictions especially when X-Score or PLP alone did not perform well.
Compared to other targeted scoring functions, our KGS strategy does not require any re-parameterization or modification on current scoring methods, and its application is not tied to certain systems. The effectiveness of our KGS strategy is in theory proportional to the ever-increasing knowledge of experimental protein-ligand binding data. Our KGS strategy may serve as a more practical remedy for current scoring functions to improve their accuracy in binding affinity prediction.
尽管基于结构的药物设计中广泛使用了当前的评分函数,但它们在预测蛋白质-配体结合亲和力方面并不是非常成功。在这里,我们提出了一种通用的知识引导评分(KGS)策略来解决这个问题。我们的 KGS 策略基于适当参考复合物的已知结合常数来计算给定蛋白质-配体复合物的结合常数。需要提供一个包含足够数量具有已知结合数据的蛋白质-配体复合物的良好训练集,以找到参考复合物。参考复合物需要与感兴趣的复合物共享类似的关键蛋白质-配体相互作用模式。因此,蛋白质-配体结合中的一些不确定因素可能会相互抵消,从而更准确地预测绝对结合常数。
在我们的研究中,开发了一种自动算法,用于总结关键的蛋白质-配体相互作用作为药效团模型,并识别与查询复合物具有最大相似性的参考复合物。我们的 KGS 策略与两种评分函数(X-Score 和 PLP)结合,分别对三个测试集进行了评估,包含 112 个 HIV 蛋白酶复合物、44 个碳酸酐酶复合物和 73 个胰蛋白酶复合物。我们在晶体结构和计算机生成的对接构象上获得的结果表明,应用 KGS 策略可以产生更准确的预测,特别是当 X-Score 或 PLP 单独表现不佳时。
与其他靶向评分函数相比,我们的 KGS 策略不需要对当前评分方法进行任何重新参数化或修改,并且其应用不受特定系统的限制。我们的 KGS 策略的有效性在理论上与实验蛋白质-配体结合数据的不断增加的知识成正比。我们的 KGS 策略可能是当前评分函数提高结合亲和力预测准确性的更实用的补救措施。