Chaitankar Vijender, Ghosh Preetam, Perkins Edward J, Gong Ping, Deng Youping, Zhang Chaoyang
School of Computing, University of Southern Mississippi, MS 39402, USA.
BMC Syst Biol. 2010 May 28;4 Suppl 1(Suppl 1):S7. doi: 10.1186/1752-0509-4-S1-S7.
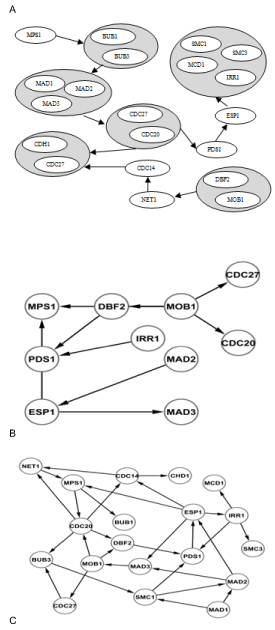
Reverse engineering of gene regulatory networks using information theory models has received much attention due to its simplicity, low computational cost, and capability of inferring large networks. One of the major problems with information theory models is to determine the threshold which defines the regulatory relationships between genes. The minimum description length (MDL) principle has been implemented to overcome this problem. The description length of the MDL principle is the sum of model length and data encoding length. A user-specified fine tuning parameter is used as control mechanism between model and data encoding, but it is difficult to find the optimal parameter. In this work, we proposed a new inference algorithm which incorporated mutual information (MI), conditional mutual information (CMI) and predictive minimum description length (PMDL) principle to infer gene regulatory networks from DNA microarray data. In this algorithm, the information theoretic quantities MI and CMI determine the regulatory relationships between genes and the PMDL principle method attempts to determine the best MI threshold without the need of a user-specified fine tuning parameter.
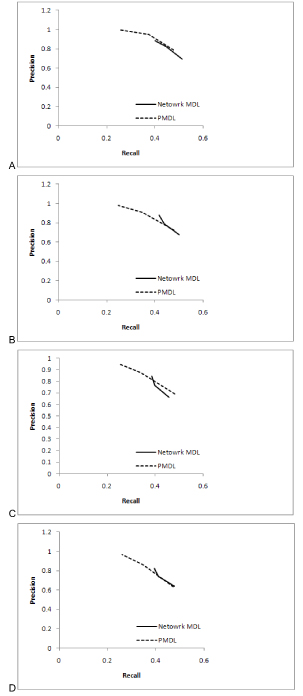
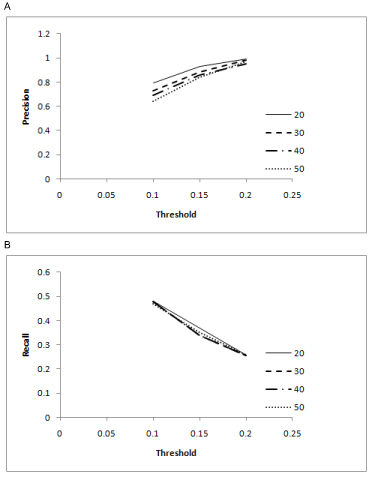
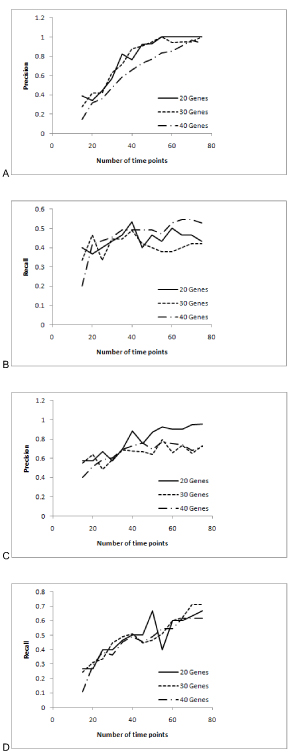
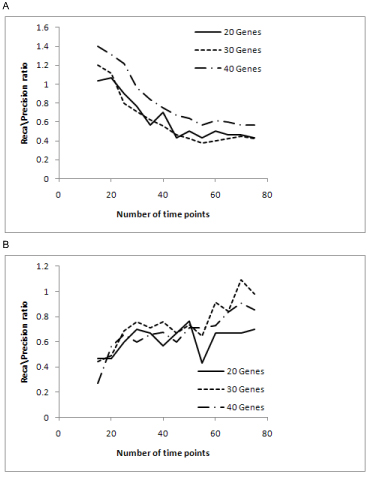
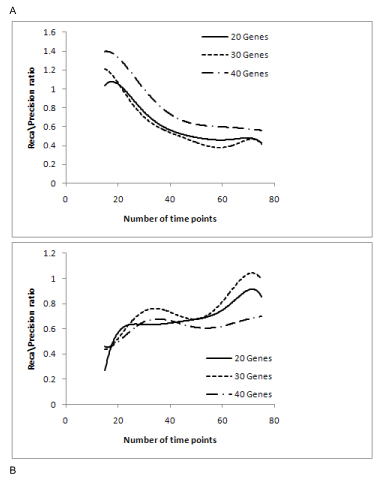
The performance of the proposed algorithm was evaluated using both synthetic time series data sets and a biological time series data set for the yeast Saccharomyces cerevisiae. The benchmark quantities precision and recall were used as performance measures. The results show that the proposed algorithm produced less false edges and significantly improved the precision, as compared to the existing algorithm. For further analysis the performance of the algorithms was observed over different sizes of data.
We have proposed a new algorithm that implements the PMDL principle for inferring gene regulatory networks from time series DNA microarray data that eliminates the need of a fine tuning parameter. The evaluation results obtained from both synthetic and actual biological data sets show that the PMDL principle is effective in determining the MI threshold and the developed algorithm improves precision of gene regulatory network inference. Based on the sensitivity analysis of all tested cases, an optimal CMI threshold value has been identified. Finally it was observed that the performance of the algorithms saturates at a certain threshold of data size.
利用信息论模型对基因调控网络进行逆向工程因其简单性、低计算成本以及推断大型网络的能力而备受关注。信息论模型的一个主要问题是确定定义基因间调控关系的阈值。最小描述长度(MDL)原则已被用于克服这一问题。MDL原则的描述长度是模型长度和数据编码长度之和。一个用户指定的微调参数被用作模型与数据编码之间的控制机制,但很难找到最优参数。在这项工作中,我们提出了一种新的推理算法,该算法结合互信息(MI)、条件互信息(CMI)和预测最小描述长度(PMDL)原则,从DNA微阵列数据推断基因调控网络。在该算法中,信息论量MI和CMI确定基因间的调控关系,而PMDL原则方法试图确定最佳的MI阈值,无需用户指定的微调参数。
使用合成时间序列数据集和酿酒酵母的生物时间序列数据集对所提出算法的性能进行了评估。基准量精度和召回率被用作性能度量。结果表明,与现有算法相比,所提出的算法产生的错误边更少,显著提高了精度。为了进一步分析,观察了算法在不同数据大小下的性能。
我们提出了一种新算法,该算法实现了PMDL原则,用于从时间序列DNA微阵列数据推断基因调控网络,无需微调参数。从合成和实际生物数据集获得的评估结果表明,PMDL原则在确定MI阈值方面是有效的,并且所开发的算法提高了基因调控网络推断的精度。基于所有测试案例的敏感性分析,确定了一个最优的CMI阈值。最后观察到,算法的性能在一定数据大小阈值处达到饱和。