Department of Decision Sciences, Bocconi University, Milan, Italy.
PLoS Comput Biol. 2010 Dec 2;6(12):e1001021. doi: 10.1371/journal.pcbi.1001021.
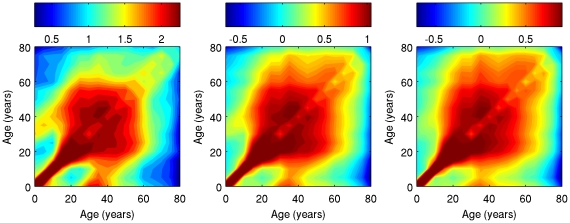
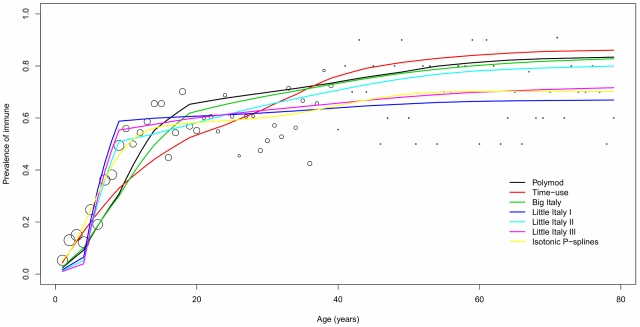
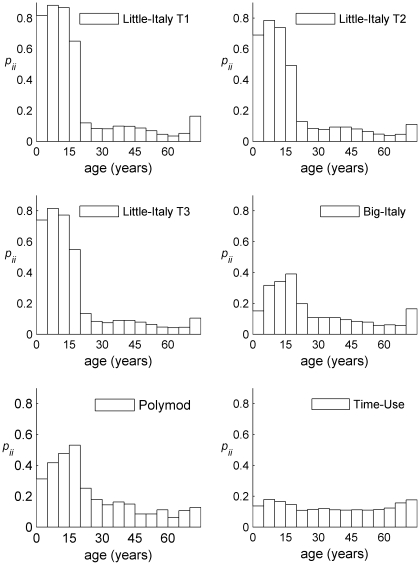
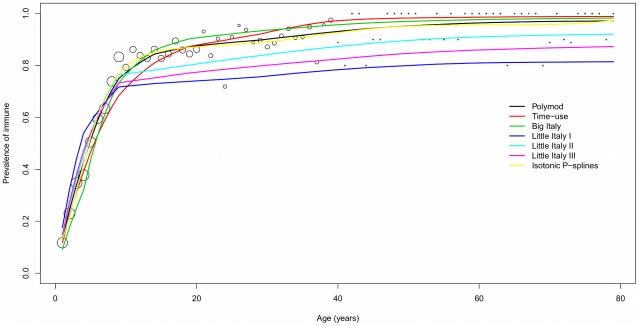
Knowledge of social contact patterns still represents the most critical step for understanding the spread of directly transmitted infections. Data on social contact patterns are, however, expensive to obtain. A major issue is then whether the simulation of synthetic societies might be helpful to reliably reconstruct such data. In this paper, we compute a variety of synthetic age-specific contact matrices through simulation of a simple individual-based model (IBM). The model is informed by Italian Time Use data and routine socio-demographic data (e.g., school and workplace attendance, household structure, etc.). The model is named "Little Italy" because each artificial agent is a clone of a real person. In other words, each agent's daily diary is the one observed in a corresponding real individual sampled in the Italian Time Use Survey. We also generated contact matrices from the socio-demographic model underlying the Italian IBM for pandemic prediction. These synthetic matrices are then validated against recently collected Italian serological data for Varicella (VZV) and ParvoVirus (B19). Their performance in fitting sero-profiles are compared with other matrices available for Italy, such as the Polymod matrix. Synthetic matrices show the same qualitative features of the ones estimated from sample surveys: for example, strong assortativeness and the presence of super- and sub-diagonal stripes related to contacts between parents and children. Once validated against serological data, Little Italy matrices fit worse than the Polymod one for VZV, but better than concurrent matrices for B19. This is the first occasion where synthetic contact matrices are systematically compared with real ones, and validated against epidemiological data. The results suggest that simple, carefully designed, synthetic matrices can provide a fruitful complementary approach to questionnaire-based matrices. The paper also supports the idea that, depending on the transmissibility level of the infection, either the number of different contacts, or repeated exposure, may be the key factor for transmission.
对直接传播感染的传播了解,知识仍然代表着最关键的步骤。然而,社会接触模式的数据获取成本高昂。那么,问题就在于模拟合成社会是否有助于可靠地重建这些数据。在本文中,我们通过模拟一个简单的基于个体的模型(IBM)来计算各种合成的年龄特定接触矩阵。该模型由意大利时间使用数据和常规社会人口数据(例如,学校和工作场所出勤、家庭结构等)提供信息。该模型被命名为“小意大利”,因为每个人工代理都是真实人的克隆。换句话说,每个代理的日常日记就是在意大利时间使用调查中抽样的对应真实个体所观察到的日记。我们还从用于大流行预测的意大利 IBM 的社会人口模型生成了接触矩阵。然后,将这些合成矩阵与最近收集的意大利水痘(VZV)和细小病毒(B19)血清学数据进行验证。将它们拟合血清谱的性能与其他可用于意大利的矩阵(例如 Polymod 矩阵)进行了比较。合成矩阵显示了与从样本调查中估计的矩阵相同的定性特征:例如,强烈的分类和与父母与子女之间的接触相关的超对角线和亚对角线条纹的存在。在与血清学数据进行验证后,Little Italy 矩阵在 VZV 方面的拟合效果不如 Polymod 矩阵,但在 B19 方面的拟合效果优于同期矩阵。这是首次系统地将合成接触矩阵与真实矩阵进行比较,并根据流行病学数据进行验证。结果表明,简单、精心设计的合成矩阵可以为基于问卷的矩阵提供富有成效的补充方法。该论文还支持这样一种观点,即取决于感染的传染性水平,不同接触的次数或重复暴露可能是传播的关键因素。